LLM
대규모 언어 모델.
대량의 텍스트 데이터를 학습하여 자연어 처리 작업을 수행.
주로 딥러닝 기법인 트랜스포머(Transformer) 아키텍처를 사용하여 구축됨.
텍스트 생성, 기계 번역, 감정 분석, 질문에 대한 답변 제공 등 다양한 언어 관련 작업 처리 가능.
Transformer
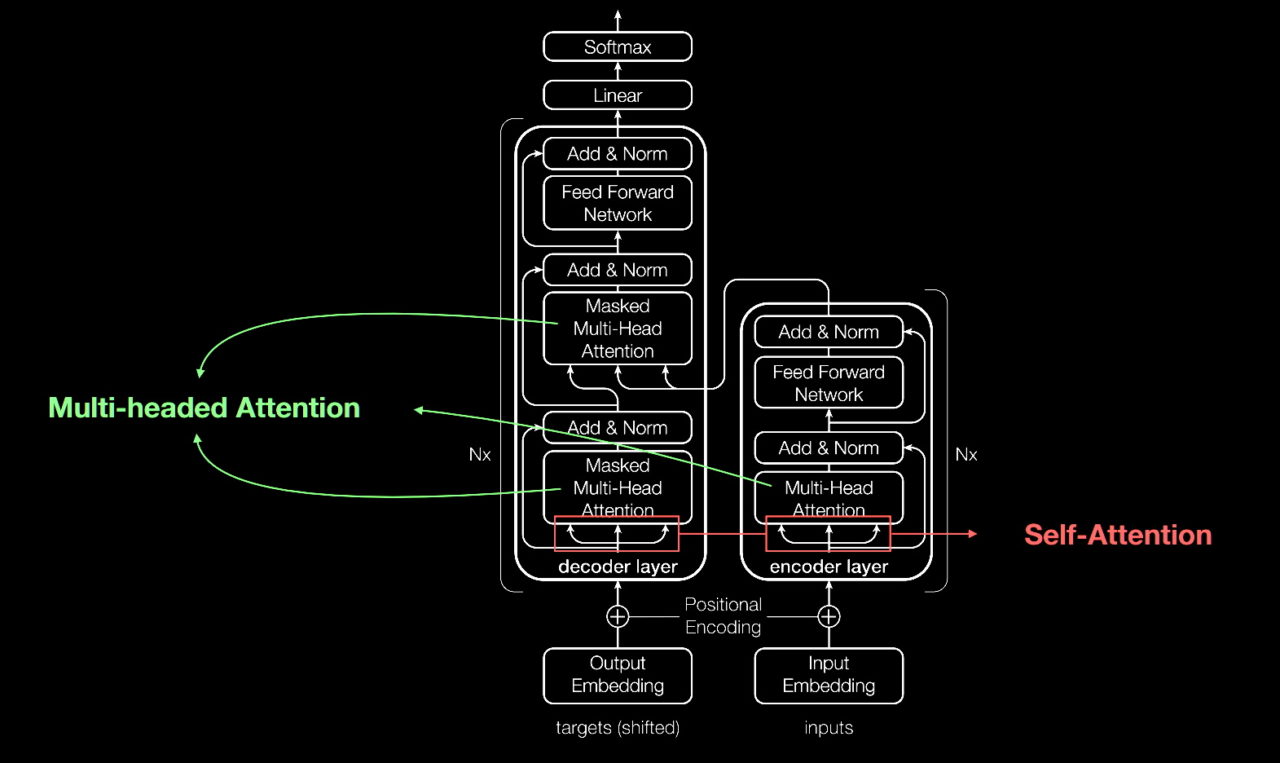
Google Transformer 아키텍처는 AI 모델이 문장 내 단어들의 관계를 이해하는 데 사용하는 구조.
이 아키텍처는 주로 'Attention' 메커니즘을 통해 중요한 단어에 집중함.
Encoder 와 Decoder로 구성되어있는데
Encoder로만 만든게 google BERT이고, Decoder로만 만든게 ChatGPT임.
Scailing Laws for Neural Language Models (2020년)
-
모델 크기가 클수록, 일반적으로 성능이 향상된다. 특정포인트까지 성립.
-
데이터셋이 클수록 모델 성능이 개선된다.
-
더 많은 학습 계산량은 모델 성능은 향상된다. 특정포인트까지 성립.
-
모델 크기, 데이터셋 크기, 학습 계산량 이 3가지 요소를 효율적으로 조정하여 최적의 성능을 달성하는 방법에 대한 지침이 나옴.
-
큰 모델은 상당한 비용
-
큰 모델은 더 범용적인 능력을 보이나 때로는 특정 작업에 최적화된 작은 모델이 더 효율적임.
Emergent Abilities of Large Language Models (2022년)
모델이 일정규모 이상 학습되면 예상하지 못한 능력이 생길 수 있음이 논문으로 발표되었음.
-
추론능력의 발달(텍스트에서 숨겨진 의미를 추론하고, 상황에 따라 적절한 결론 도출)
-
지식의 내재화(다양한 주제에 대한 지식의 내재화하여 새로운 질문이나 작업에 적용)
-
언어 생성의 자연스러움(사람이 쓴 것과 구분하기 어려운 수준의 텍스트를 생성함)
-
문제 해결 능력(특정 프로그래밍 문제를 해결, 복잡한 질문에 대한 답변 제시 및 전통적으로 인간의 영역으로 여겨졌던 문제 해결 능력을 보임)
-
다양한 언어 작업(번역,요약,질답에서 높은 성능)
-
새로운 작업에의 적응(명시적으로 학습되지 않은 새로운 작업에 대해서도 높은 이해와 수행 능력을 보여줌)
In-context learning(2020년)
문맥을 활용해서 새로운 작업을 수행하는 방식
Insturction following(tuning)(2021년)
기존에는 입력과 정답으로 이루어진 내용을 학습시킴.
Instruction following은 작업 지시문과 이에 따른 아웃풋 예시로 학습을 시킴.
장점은 데이터가 적어도 된다.
단점은 성능이 Instruction의 질에 의존하고, 고도의 질문에는 답변 힘듬.
Step-by-step reasoning(2023년)
복잡한 추론과정을 작은 단계로 나누고 추론이 가능하다는 것.
왜 이런 능력이 생겼는 지는 규명이 되지않았다고함.
시간에 따른 언어 모델의 역할
1990s - Statistical LM(통계, 확률에 대한 보조)
2013 - Neural LM(자연어 처리에 대한 작업 수행)
2018 - Pre-trained LM(더 다양한 자연어 처리에 대한 작업 수행)
2020 - LLM(프롬프트를 통해서 더 다양한 실제 task 문제를 해결함)
