Intro to Deep Neural Networks
-
Artificial Neural Networks
- imitates neurons
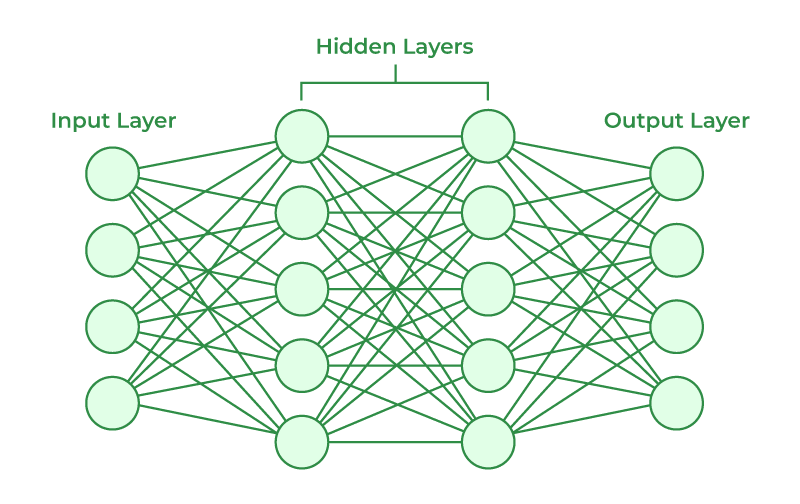
- imitates neurons
-
Deep Neural Network (DNN)
- stacking neural network layers = improves AI accuracy
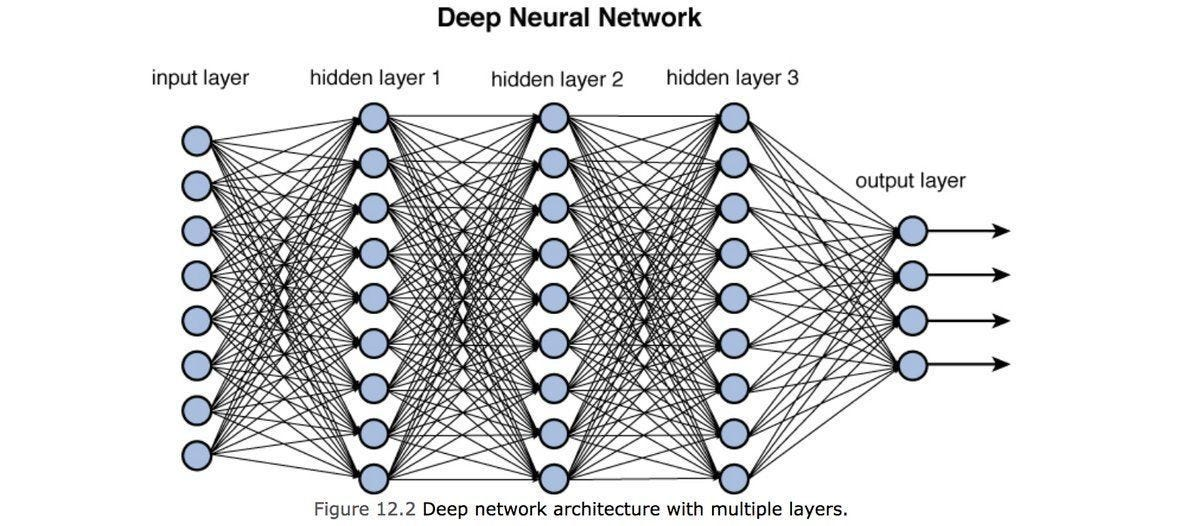
- stacking neural network layers = improves AI accuracy
-
perceptron
- Single-layer = AND gate, OR gate
- Multi-layer = XOR gate
- Hidden layer: Input layer와 Output layer의 중간 단계로, 서로 다른 역할을 해주는 여러 뉴런들이 모여있고 순차적 연결을 돕는다.
- hidden layer가 1개이면 2-layer Neural Network
-
Linear layer (= Fully-connected layer)
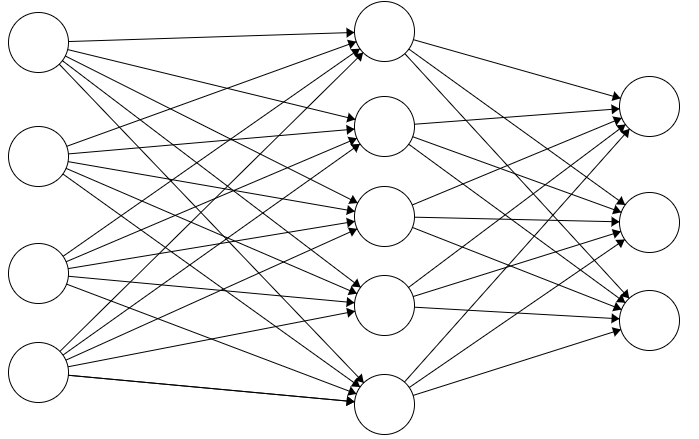
- the layer where perceptrons are fully connected between two layers
-
Softmax layer
- multiclass classification
- 주어진 벡터의 각 요소를 0과 1 사이의 값으로 변환하고, 모든 요소의 합이 1이 되도록 (sum-to-one) 정규화하는 함수
- Softmax loss (= Cross-entropy loss, NLL)
Training Neural Networks
-
Training NN via Gradient Descent
- Gradient Descent: loss를 최소화 하는 weight를 찾는 방법 중 하나
- various Gradient Descent methods: Adam, GD, Momentum, ...
- use Backpropagation to compute Gradient in NN
-
Sigmoid Activation
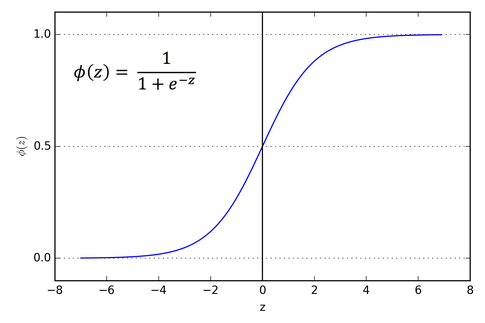
- problem of Sigmoid activation: cause gradient vanishing problem
-
Tanh Activation
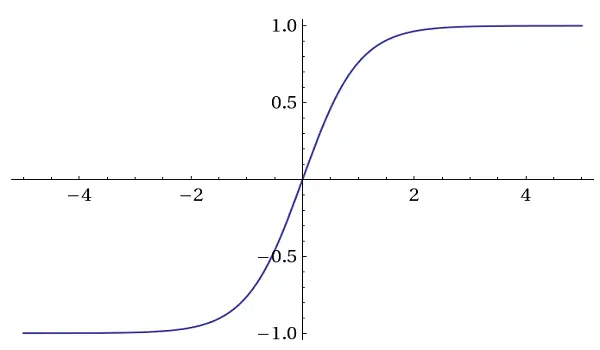
- numbers range [-1, 1]
- zero centered, but still cause a gradient vanishing problem
-
ReLU Activation
- ReLU: Rectified Linear Unit
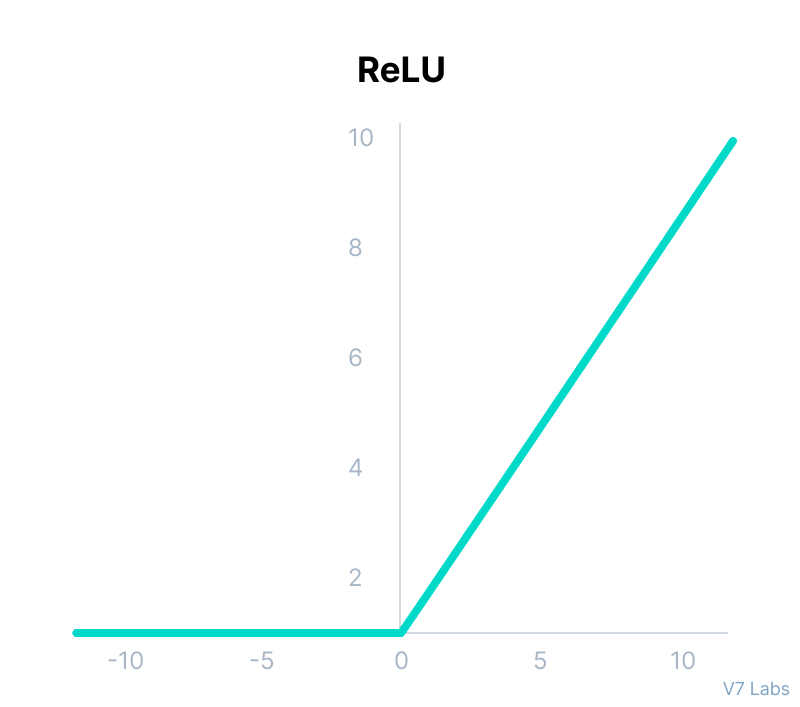
- F(x) = max(0, x)
- converge much faster than sigmoid/tanh
- ReLU: Rectified Linear Unit
-
Batch Normalization
- 학습을 용이하게 하는 특별한 형태의 추가적인 neuron/layer
- mini batch : compute empirical mean and variance → normalize (to unit Gaussian)
Convolutional Neural Networks & Image Classification
-
ConvNets or CNN (Convolutional Neural Network)
-
Process
- overlap the small pattern (convolutional filter) and the image patch
- multiply each pixel by the corresponding filter coefficient
- add them up
- divide by the total number of pixels (optional)
- can get output activtion map
- Pooling: shrink the image stack
-
Various CNN Architectures
- VGGNet
- small convolutional filters, with deeper layers
- ResNet (Residual Network)
- very deep networks using residual connections
- VGGNet
Seq2seq with Attention for Natural Language Understanding and Generation
-
RNN (Recurrent Neural Networks)
- given a sequence data, recursively run the same function over time
-
Various Problem settings of RNN-based Sequence Modeling
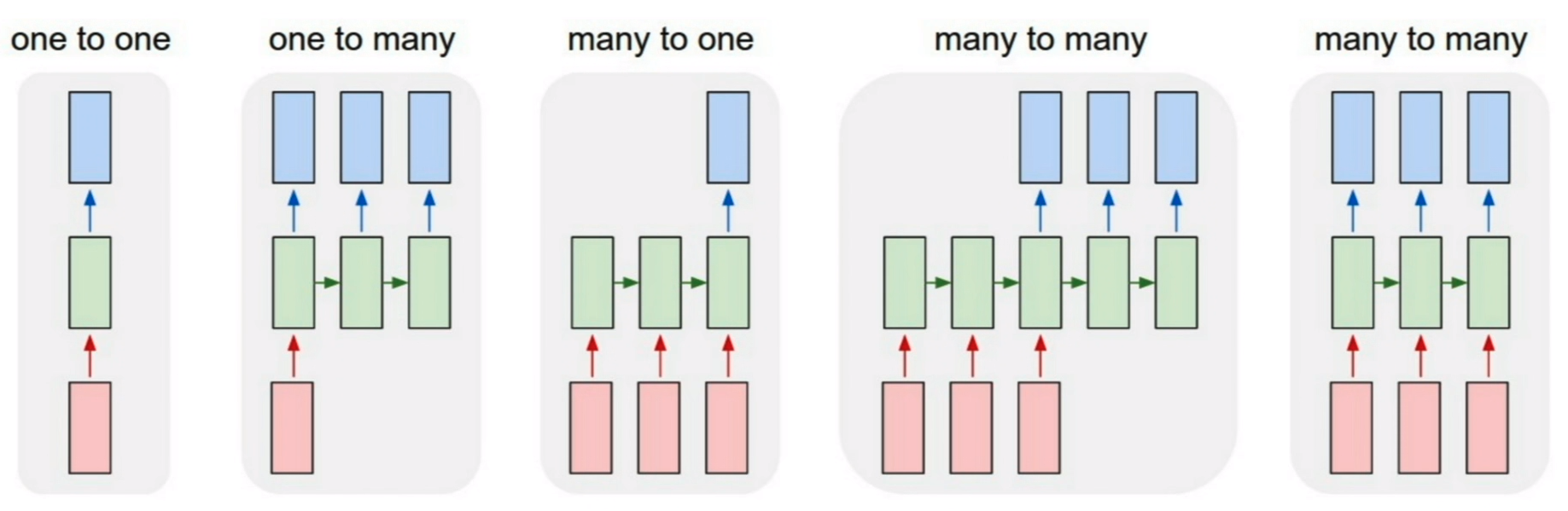
- One to one: Vanilla neural networks
- One to many: 순차적 예측 결과 생성 (e.g. Image captioning)
- Many to one: sequence로 주어지는 입력에 따라 단일한 time step의 예측 결과 생성 (e.g. Sentiment Classification: Sequence of Text → Sentiment)
- Many to many: 입력도 sequence, 출력도 sequence
- 입력 sequence 모두 읽고 나서 출력 (e.g. Machine Translation)
- 입력 sequence와 출력 sequence의 delay를 허용하지 않는 경우, 실시간 예측 (e.g. Video classification on frame level)
-
Auto regressive model
: at test-time sample characters one at a time, feed back as an input to the model at the next time step -
Advanced RNN models such as LSTM or GRU are often used in practice
-
Long Short Term Memory (LSTM)
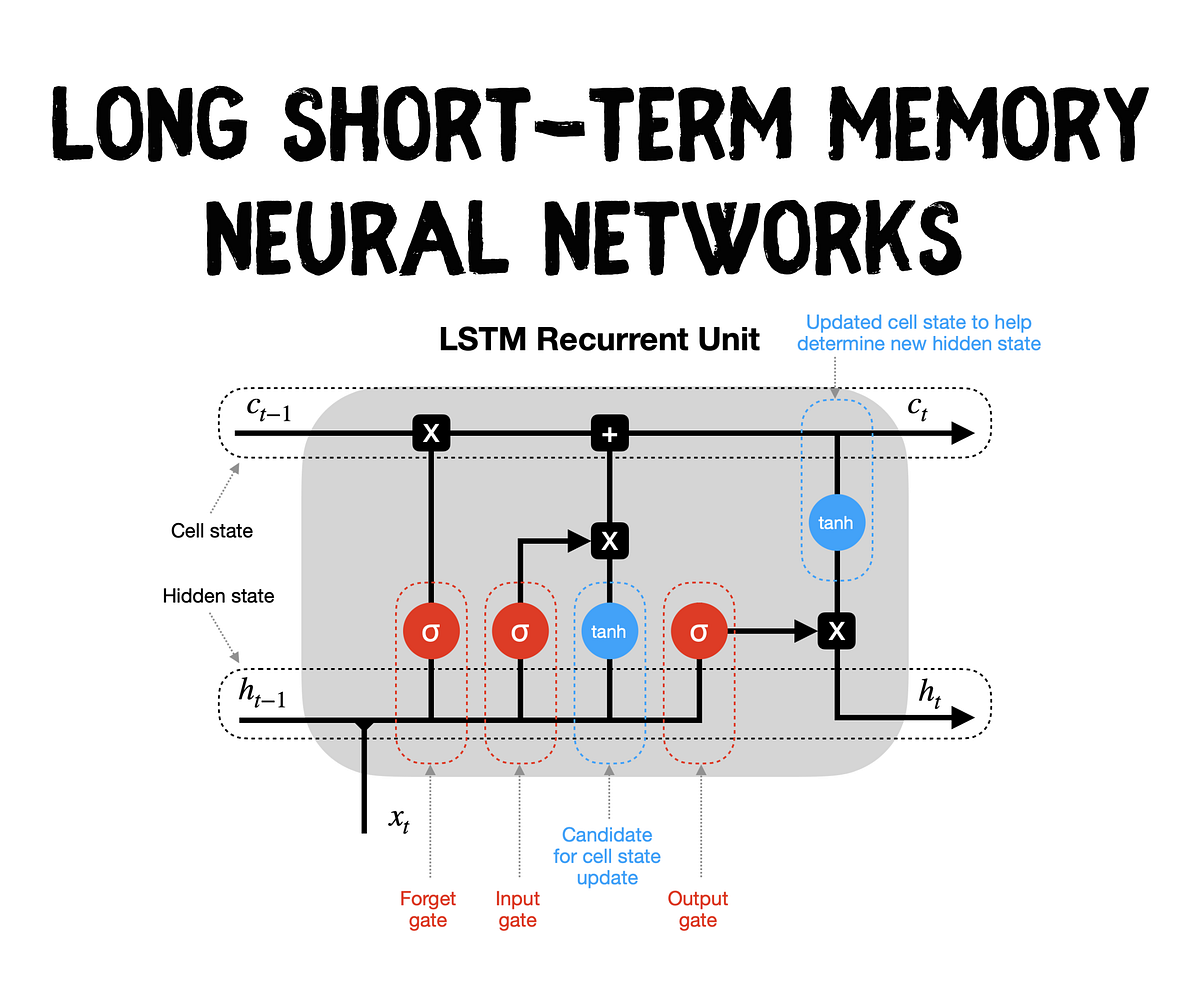
-
Seq2seq model

- sequence of words as input and sequence of words as output
- Encoder / Decoder
-
Seq2seq with Attention
- solution to the bottleneck problem of original seq2seq
- IDEA: at each time step of the decoder, allow the decoder to utilize a different part of the source sequence
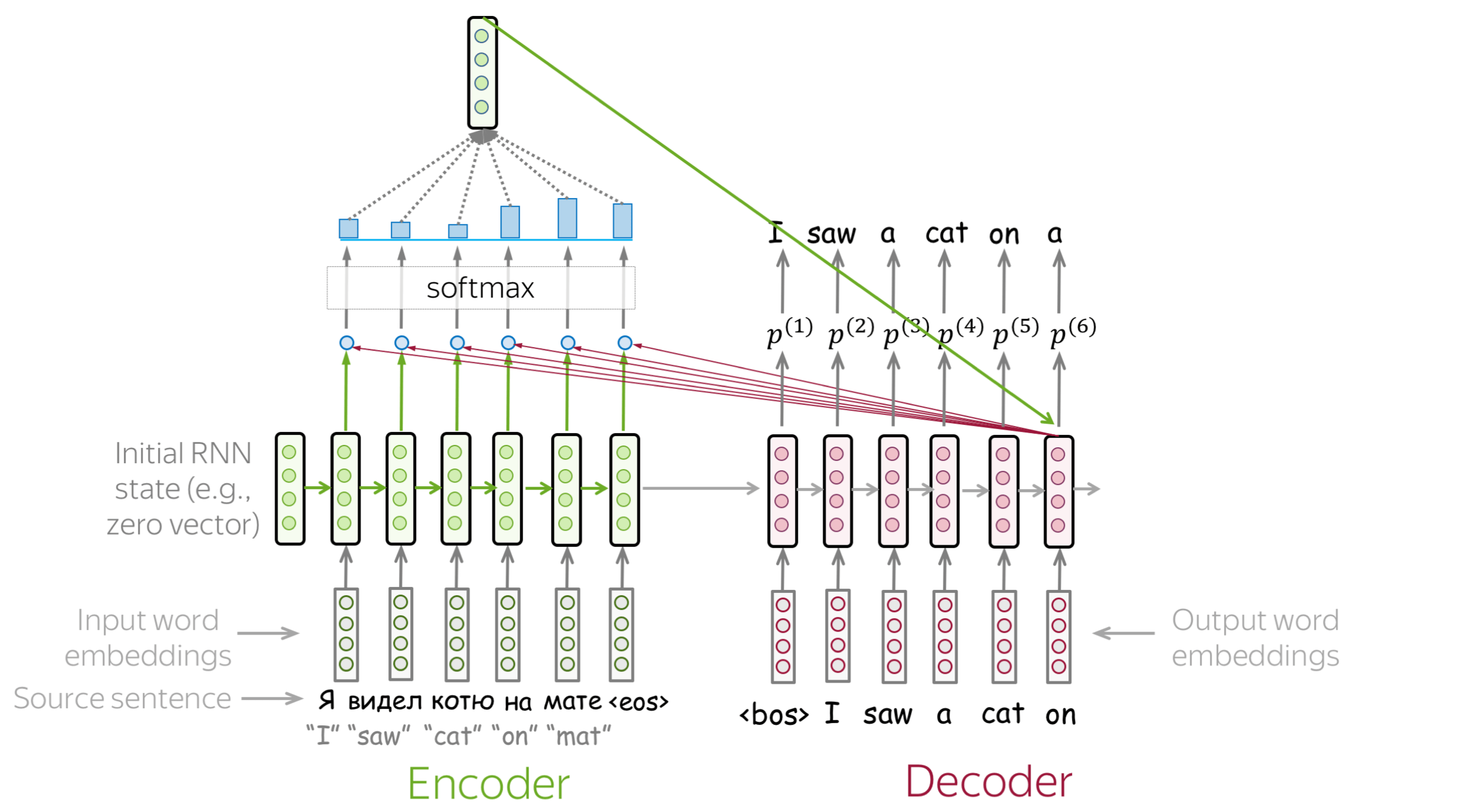
-
Advanced Attention Techniques
- Gating (use sigmoid instead of softmax)
- Self-attention
Transformer
-
Scaled Dot-product Attention
-
Multi-head attention
-
Layer Normalization
Self-supervised learning and Large-scale Pre-trained models
-
Self supervised learning
: Given unlabeled data, hide part of the data and train the model so that it can predict such a hidden part of data, given remaining data -
BERT
- Pre-training through Masked Language Modeling (MLM) and Next-Sentence Prediction (NSP) tasks
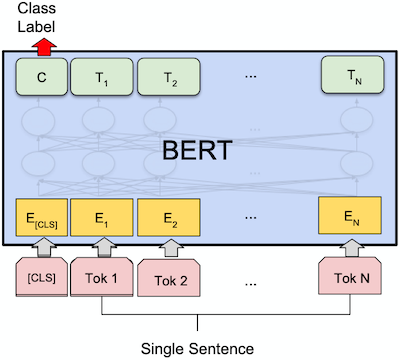
- Pre-training through Masked Language Modeling (MLM) and Next-Sentence Prediction (NSP) tasks
-
GPT (Generative Pre-Training Transformer)
- Genrative Pre-training task, Language modeling, Auto-regressive model