Introduction to Machine Learning
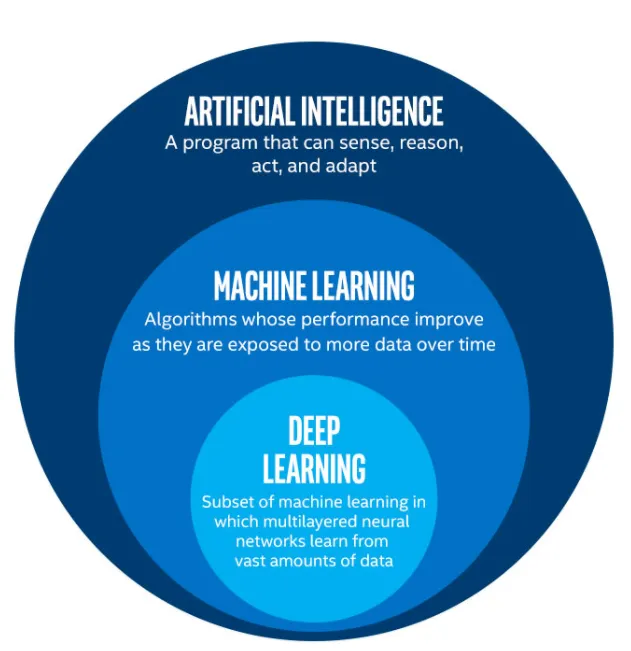
💡 Machine Learning
: a branch of Artificial Intelligence, concerned with the design and development of algorithms that allow computers to evolve behaviors based on empirical data
-
Improvement on task T, with respect to Performance Metric P, based on experience E
-
The key idea of ML is "Generalization".
- not to learn EXACT representation of training data itself, but to build a statistical model of the process that generates the data
- Generative AI: the use of AI to create new contents
-
No Free Lunch Theorem for ML
: No machine learning algorithm is universally any better than any other
1. Supervised learning
- given input and output data (x, y) - learn a function f(x)
- Classification: y is categorical
- Regression: y is continous (real number)
2. Unsupervised learning
- only given x to find hidden structure (e.g. clusters)
- Classification
- Clustering, Anomaly detection, Density estimation, ...
3. Semi-supervised learning
- some of training data includes desired outputs
- label only a small number of examples & make use of a large number of unlabeled examples to learn
- LU learning: small set of Labeled examples, large set of Unlabeled examples
- PU learning: Positive and Unlabeled examples
- can label unlabeled data probabilistically (soft label)
4. Reinforcement learning
- feedback loop between learning system and environment
- No supervisors, but only rewards
- (-) feedback could be delayed = take longer time
Bias and Variance
-
Generalization in ML
- model's ability to perform well on new unseen data
- = related to Overfitting
- Overfitting means poor generalization
-
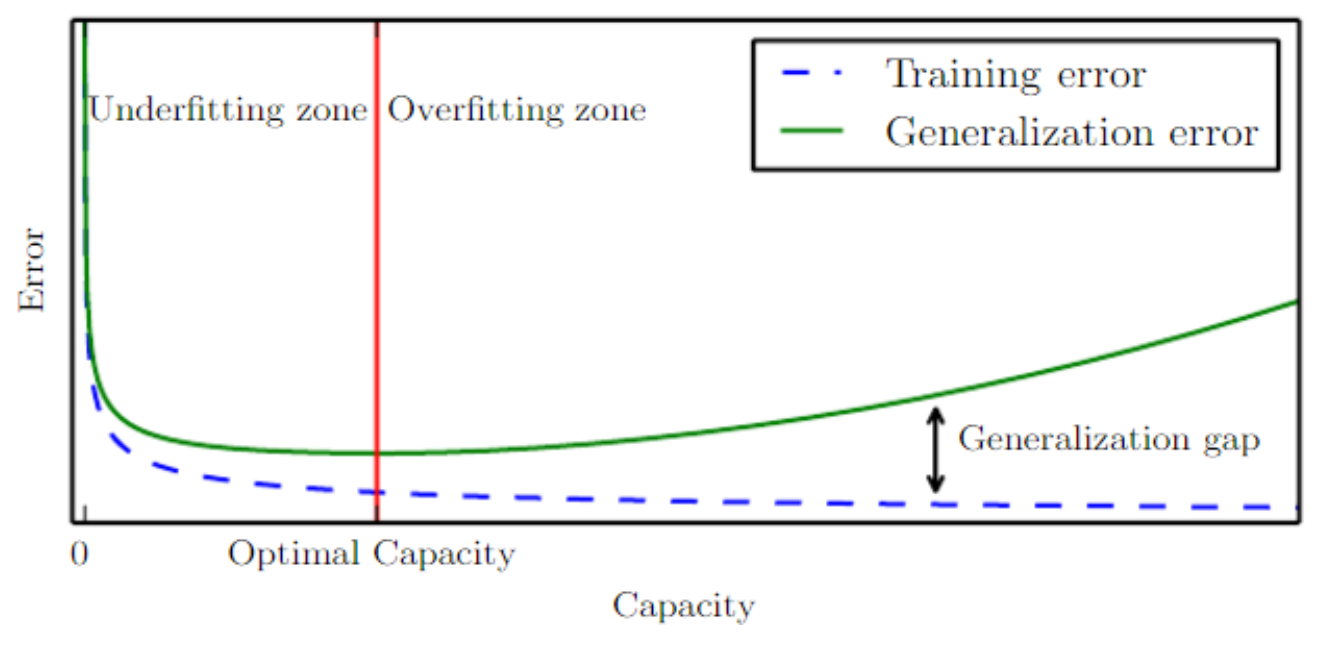
Generalization Error
- Underfitting
- Generalization Error < Training Error
- must NOT occur
- Overfitting
- Generalization Error > Training Error
- too fit for the training data
- So, out first goal is to have "Overfitting"
- because this means we found a model which performs well at least on the training data
- Underfitting
-
Model's Capacity
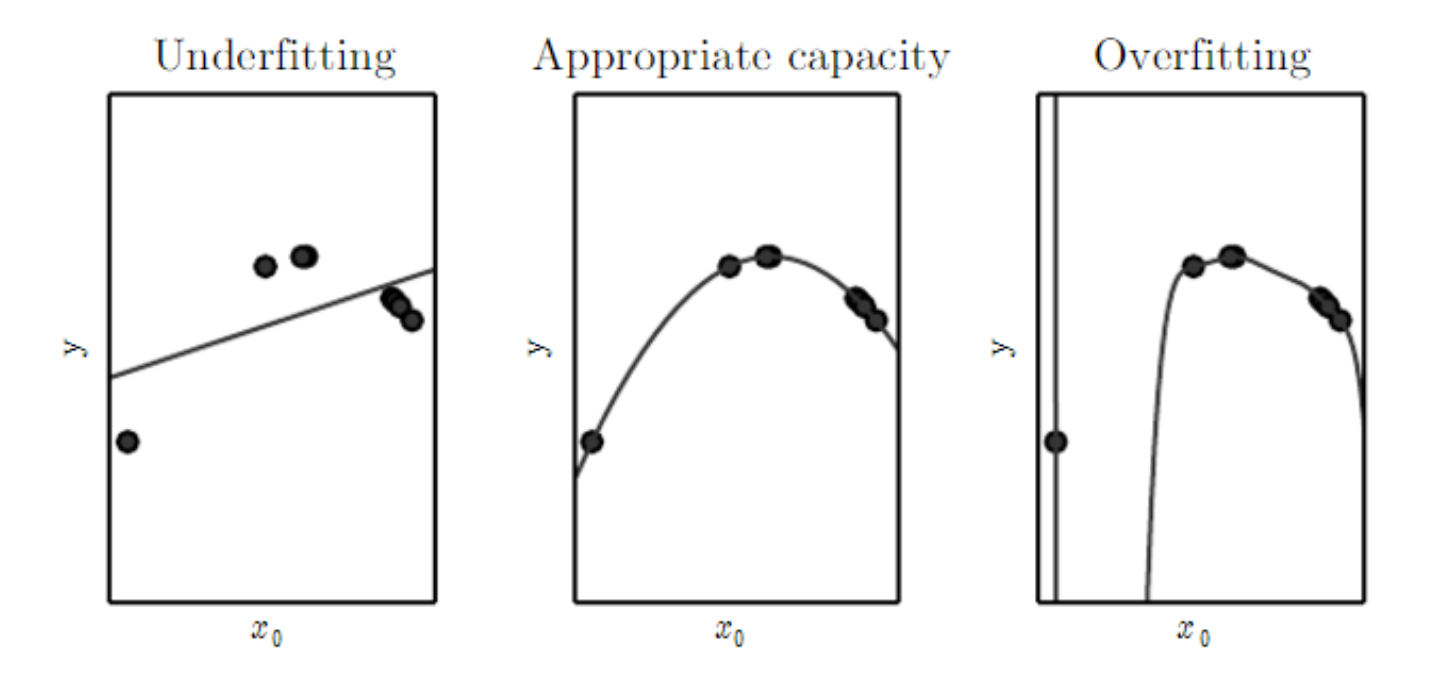
- Linear: unable to capture curvature
- Quadratic
- Polynomial of degree 9: too complex, a deep valley in between to datapoints
-
Occam's Razor: a principle of Parsimony (based on probability and experience)
-
Typical Relation between Capacity and Error
-
Regularization
- to reduce model's generalization error but not training error
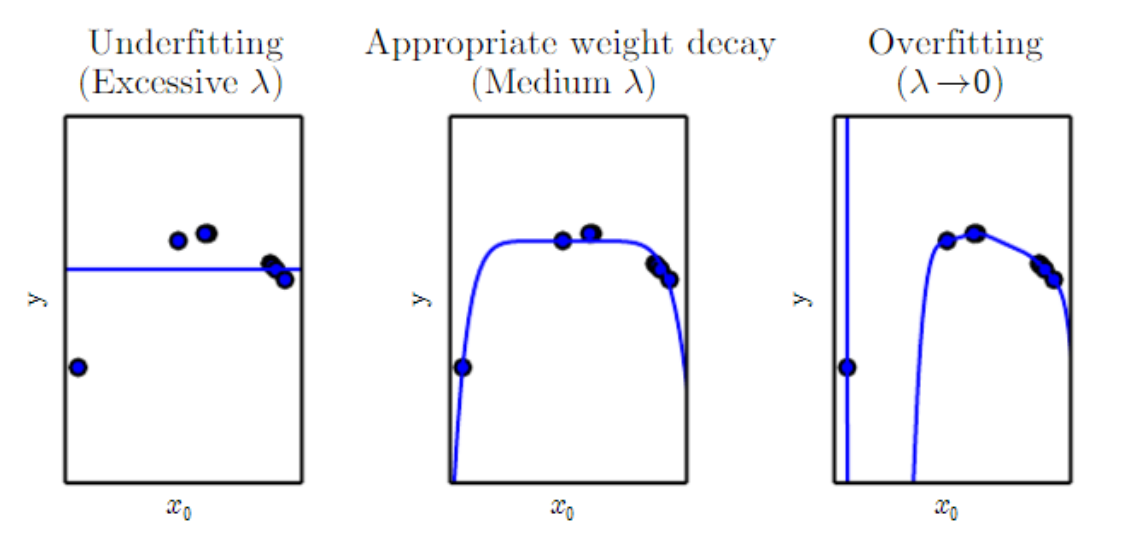
- to reduce model's generalization error but not training error
-
Bias/Variance
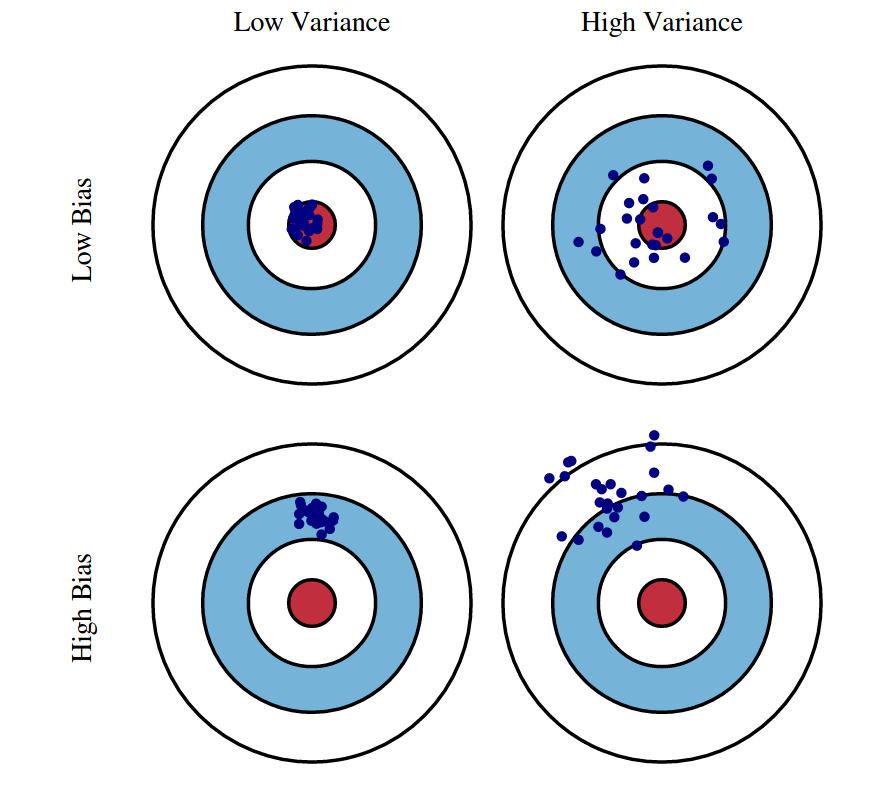
- Low bias means "predicted well",
- Low variance means "stable".
- There's a tradeoff between them
- High variance implies Overfitting
- High bias implies Underfitting
Recent Progress of Large Language Models
-
GPT-3
- Generative Pretrained Transformer
: not simply perform a single task, but general-purpose tasks
- Generative Pretrained Transformer
-
InstructGPT
- fine-tune GPT-3 using human feedback
- Reinforcement Learning from Human Feedback (RLHF)
- Training of InstructGPT
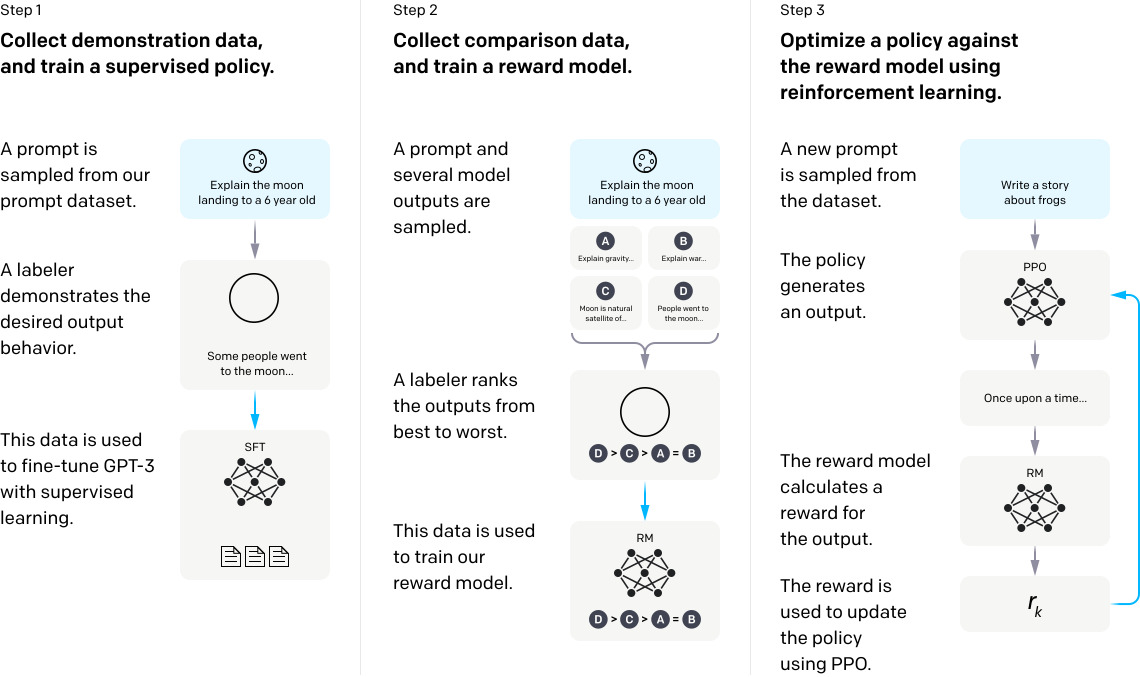
- Suprvised fine-tuning (SFT)
- Reward Model (RM) training
- Reinforcement Learning (RL) via PPO
-
ChatGPT: similar model of InstructGPT with conversational UI
-
GPT-4: a large multimodal language model
-
Timeline of Large Language Models
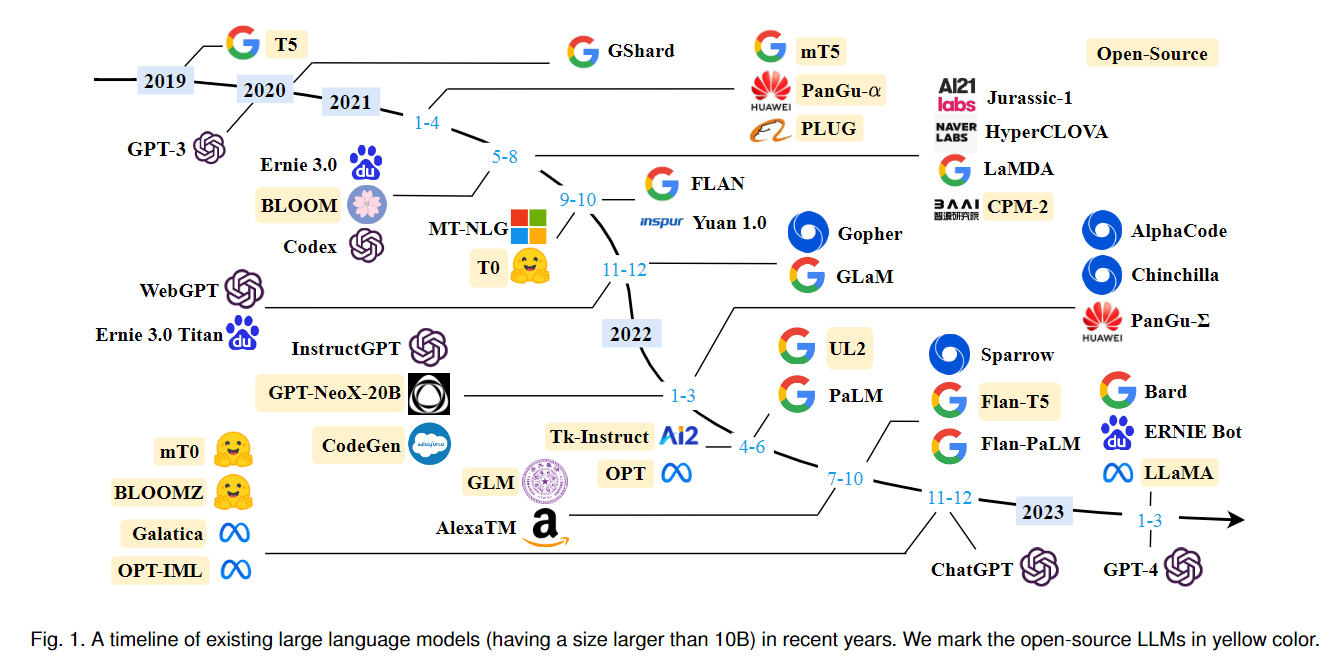
- Anthropic Claude
- Google Bard
- Google PaLM
- Meta OPT & LLaMA
- Open pretrained transformer (OPT)
- Stanford Alpaca: self-instruct tuning on LLaMA (retain data from GPT and train on LLaMA)
- LMsys Vicuna: fine-tuned from Meta's LLaMA
-
Conclusion
- Data-centric AI (importance of data itself)
- API vs IN-house LLM?