01. 넘파이
-
파이썬 기반 머신러닝에서 넘파이를 이해하는 것은 중요
-
⭐ axis 0 = row, axis 1 = column 방향
02. 판다스
-
CSV file: 칼럼을 ','로 구분한 파일 포맷
-
read_csv()를 통해 DataFrame 생성 -
데이터의 분포도를 아는 것 중요
-
value_counts: 데이터 분포도를 확인하는 데 유용 -
series: index와 단 하나의 칼럼으로 구성된 데이터 세트
-
⭐ DataFrame을 넘파이 ndarray로 변환하는 것: DataFrame 객체의
values이용 -
데이터 삭제 시 주의 할점
DataFrame.drop(labels=None, axis=0, index=None, Columns=None, level=None, inplace=False, errors='raise')- 'axis=1'이면 칼럼 축 방향으로 드롭 수행 = labels에 원하는 칼럼명 입력 (교재 대부분의 경우)
- 여러개의 칼럼을 삭제하고 싶으면, labels에 칼럼명을 리스트 형태로 입력
- 'axis=0'이면 로우 축 방향으로 드롭 수행 = labels에 index
- inplace: 디폴트값은 False이며, 이 경우 자기 자신의 (원본의) 데이터는 삭제되지 않는다
- 'axis=1'이면 칼럼 축 방향으로 드롭 수행 = labels에 원하는 칼럼명 입력 (교재 대부분의 경우)
-
DataFrame 및 Series의 Index 객체는 변경 불가, Index는 오직 식별용!
-
reset_index(): 인덱스가 연속된 int 숫자형 데이터가 아닐 경우 다시 이를 int 숫자형 데이터로 만들 때 주로 사용 -
❕DataFrame과 Series: series가 하나의 열을 구성, series가 여러개 모이면 DataFrame
-
iloc[]는 열 위치에 '-1'을 입력하여 DF의 가장 마지막 열 데이터를 가져오는 데 자주 사용 -
loc[인덱스값, 칼럼명]: 명칭 기반 데이터 추출 -
❕주의❕
loc[]에서의 슬라이싱 시, 시작값~종료값이다 (종료값-1 아니고, 어찌보면 당연함 명칭에서 '-1'을 하는게 불가하니까) -
iloc[]과는 다르게loc[]은 불린 인덱싱이 가능하다 & 이 둘은 행과 열을 함께 사용하여 데이터 추출 시 사용 -
DataFrame aggregation 함수 적용: min(), max(), sum(), count()
03. 사이킷런 (scikit-learn)
-
분류 알고리즘 구현한 클래스는 Classifier, 회귀 알고리즘 구현한 클래스는 Regressor => 이 둘을 합쳐서 Estimator
-
일반적으로 머신러닝 모델 구축 주요 단계:
- 피처 처리 → ML 알고리즘 학습/예측 수행 → 모델 평가 -
학습 데이터를 GridSearchCV 이용해 최적 하이퍼 파라미터 튜닝 수행 → 테스트 데이터 세트에서 이를 평가
1) 첫번째 머신러닝 - 붓꽃 품종 예측
- 분류 (Classification): 지도학습 방법의 하나
- 레이블 데이터로 모델 학습 → 미지의 레이블 예측
- 즉, 명확히 답이 주어진 데이터를 먼저 학습하고, 미지의 정답을 예측하는 방식
- 학습 데이터 세트, 테스트 데이터 세트
- 피처(feature) 데이터, 레이블(label) 데이터 - 데이터 세트 분리 → 모델 학습 → 예측 수행 → 평가
- 모델 학습:.fit()
- 예측:.predict()
2) 교차 검증
: 과적합 문제 개선하기 위함 (❓과적합(Overfitting)이란? 모델이 학습 데이터에만 과도하게 최적화되어, 실제 예측을 다른 데이터로 수행할 경우 예측 성능이 과도하게 떨어지는 현상)
- K 폴드 교차 검증: K개의 데이터 폴드 세트를 만들어서, K번만큼 각 폴드 세트에 대해 학습과 검증 평가를 반복적으로 수행 (학습 데이터 세트, 검증 데이터 세트 점진적으로 변경)
- Stratified K 폴드: 불균형한 분포도를 가진 레이블 데이터 집합을 위한 K 폴드 방식
cross_val_score(): 교차 검증 더욱 간단하게, fit/predict/evaluate 모두 내부에서 일어난다
3) 데이터 전처리
- 식별자 피처(e.g. 주민번호, 단순 문자열 아이디)는 인코딩하지 않고 삭제하는 것이 좋음, 이런 피처는 단순히 데이터 로우를 식별하는 용도로 사용되므로 오히려 예측 성능을 떨어뜨리기 때문!
- 데이터 인코딩
- 레이블 인코딩: 문자열 값을 숫자형 카테고리값으로 변환, but 변환된 값은 단순 코드이므로 선형 회귀에서는 적용 X
- 원-핫 인코딩: 새로운 피처를 추가하여 고유값에 해당하는 칼럼에만 1, 나머지 칼럼에는 0 표시
- 판다스에서는
get_dummies()로 편리하게 원-핫 인코딩
- 판다스에서는
- 피처 스케일링: 정규화, 표준화
- StandardScaler, MinMaxScaler
- ❗학습 데이터로
fit()이 적용된 스케일링 기준 정보를 그대로 테스트 데이터에 적용해야 = 테스트 데이터는 학습 데이터의 스케일링 기준을 따라야 = 테스트 데이터에 다시fit()을 적용하면 안됨!
+) 보완 & 실습 part
-
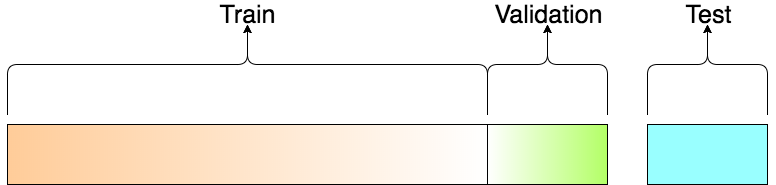
train_test_split()
: 기존 train / test로 구분 되어 있었던 데이터 셋을 train에서 train / validation으로 일정 비율 쪼갠 다음에 학습 시에는 train 셋으로 학습 후 중간중간 validation 셋으로 내가 학습한 모델 평가
-
X_train, X_test, y_train, y_test: X는 피처 부분, y는 label 부분 -
accuracy_score(y_test, dt_pred)
: 인자 차례대로 (정답, 예측값) → 정확도 계산 -
학습, 예측, 정확도 계산 파라미터
# train 데이터들로 학습
clf.fit(X_train, y_train)
# 피처들이 주어지면 그거에 대해 결과(= y, label) 예측
predictions = clf.predict(X_test)
# '정답, 예측값' 기반으로 정확도 계산
accuracy = accuracy_score(y_test, predictions)- 순서 정리
- 전처리: 데이터 가공 및 변환
- 데이터 세트 분리: 학습 데이터, 테스트 데이터로 분리
- 모델 학습: 학습 데이터 기반 머신러닝 알고리즘 적용
- 예측 수행: 테스트 데이터에 대한 예측
- 평가: 예측된 결과값과 실제 결과를 비교
유용해요~!👍🏻