이번 프로젝트에서는 운영 효율성을 높이기 위해 Third-party Application을 도입했습니다. 당장은 사용자 수가 적더라도, 향후 폭발적인 증가나 서버 인스턴스 확장 상황을 대비해 학습하고 싶었습니다.
그 과정에서 제한 정책을 얼마나 빠르고 정확하게 적용할 수 있을지, 그리고 시스템 상태를 실시간으로 모니터링할 수 있을지를 고민했습니다.
이 글에서는 이러한 문제를 해결하기 위해 선택한 두 가지 핵심 기술 스택 — Redis와 Prometheus + Grafana + Loki 조합 — 을 왜 도입했는지, 어떻게 활용했는지 그리고 어떤 이점을 얻었는지 포스팅해 보겠습니다.
1. Redis
Redis란?
Redis는 인메모리 데이터 저장소로, 매우 빠른 읽기/쓰기 성능을 자랑합니다. TTL(Time-To-Live), Pub/Sub, Sorted Set 등 다양한 자료구조를 지원하며, 카운팅이나 시간 기반 제어에 특히 강력합니다.
왜 Redis?
처음에는 서버 메모리에 직접 도배 방지, 신고 쿨타임(TTL 기반)과 같은 제한 로직을 구현했습니다. 하지만 이 방식에는 한계가 있었습니다.
- 단일 서버에서만 동작 → 확장성 부족
- 서버 인스턴스가 늘어나면 제약 조건을 공유할 수 없음
해당 문제를 고려하여 매니지드 Redis 서비스인 RedisCloud를 도입했습니다. RedisCloud는 클러스터링, 샤딩, 자동 장애 복구 같은 기능을 제공해주어, 인프라를 직접 운영하지 않아도 분산 환경에서 안정적인 제약 처리를 유지할 수 있었습니다.
운영 과정에서는 RedisInsight도 함께 활용했습니다. RedisInsight는 Redis 데이터를 GUI로 시각화할 수 있어 TTL 만료 상태, Pub/Sub 메시지 흐름, Key 사용량 등을 한눈에 확인할 수 있습니다.
아래 그림처럼 RedisInsight를 통해 Key TTL과 카운팅 현황을 직접 확인할 수 있었고, 실시간 제약 정책이 제대로 동작하는지 빠르게 검증할 수 있었습니다.
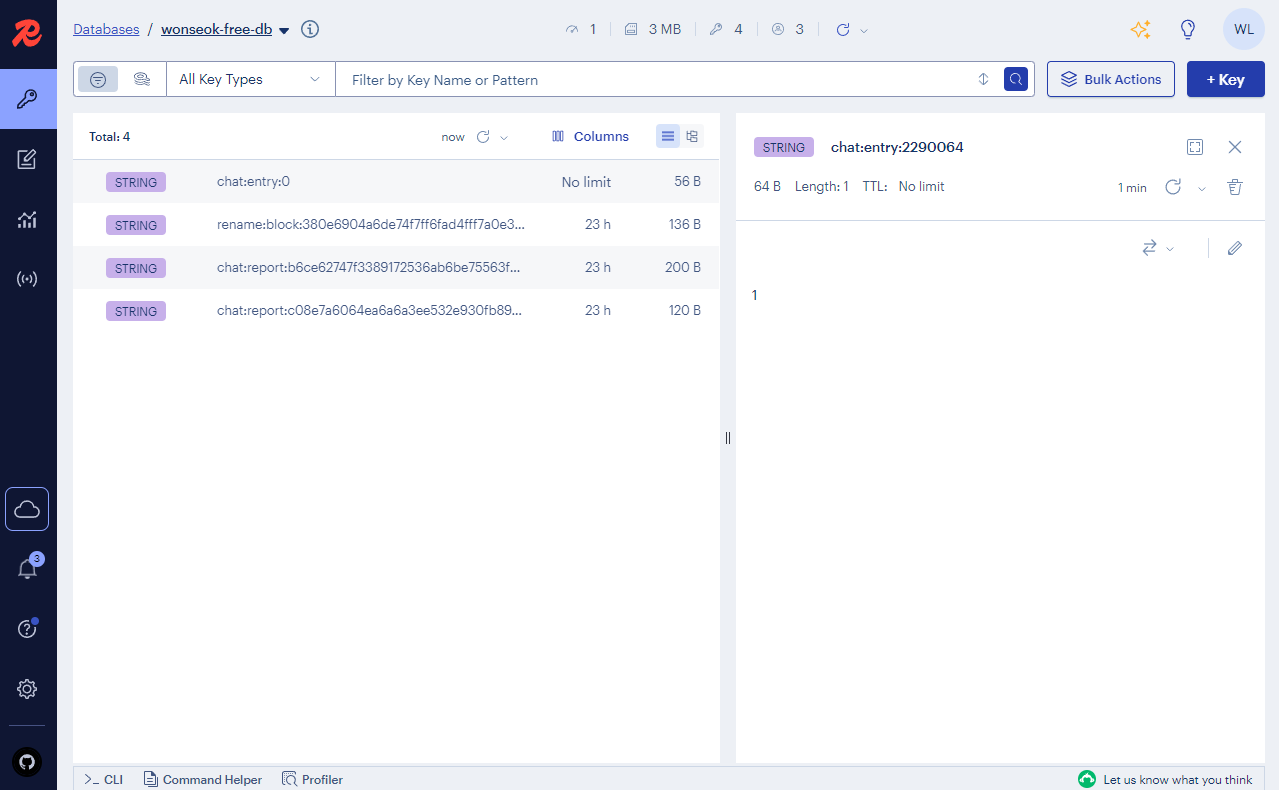
어떻게 활용했나?
1. 닉네임 변경 쿨타임 제어
- rename:block:{UUID} Key를 TTL 24시간으로 설정 → 하루 1회만 변경 가능
- 변경 시도 시 Key 존재 여부로 판단
2. 도배 방지 및 신고 제한
- message:count:{UUID}, chat:block:{UUID} Key에 도배·반복 메시지·신고 횟수를 저장해 제어
3. 채팅방 인원 관리
- 입장 시 chat:entry:{itemId} Key 카운트 증가, 퇴장 시 감소
- Redis Lua 스크립트로 원자적 연산 보장
4. 중복 요청 차단
- 동일 요청 반복 시 Key TTL을 활용해 1초간 차단
어떤 효과를 봤나?
- 학습 효과: 인메모리 DB와 분산 처리에 대한 실전 경험
- 운영 효율: RedisCloud로 인프라 관리 부담을 줄이고 확장성 확보
- 개발 생산성: RedisInsight로 Key-TTL을 시각적으로 확인하며 디버깅 속도 향상
- 성능: RDB 대비 훨씬 낮은 레이턴시로 실시간 제약 처리 가능
2. Prometheus + Grafana + Loki – 통합 모니터링
왜 모니터링을 고민했나?
최근 기업 컨퍼런스를 보면 메트릭과 로그 기반의 모니터링 시스템을 적극적으로 활용하고 있었습니다. 그런데 저는 배포한 프로젝트의 CLI로 로그를 찍어보면서 문제점을 찾고 있었고, 로그 및 매트릭 매니지먼트 툴 들에 무지했습니다.
이러한 과정을 좀 더 효율적으로, 그리고 체계적으로 개선해보고자 모니터링 스택을 도입해보기로 했습니다.
Prometheus – 메트릭 수집기
Prometheus는 애플리케이션의 메트릭(JVM, CPU, 요청 수 등)을 주기적으로 수집하는 툴입니다. Pull 방식으로 동작하며, Spring Actuator + Micrometer와 연동하면 거의 모든 지표를 자동으로 가져올 수 있습니다.
덕분에 “어떤 요청이 몇 건 들어오고, CPU 사용률이 어떻게 변하는지” 같은 지표를 실시간으로 볼 수 있게 되었습니다.
global:
# 5초마다 Pull 방식으로 메트릭 수집
scrape_interval: 5s
scrape_configs:
- job_name: "spring-app"
# SpringBoot의 Actuator 엔드포인트 명시
metrics_path: "/api/v1/actuator/prometheus"
static_configs:
- targets: ["172.31.47.167:8081"]Grafana – 대시보드 & 알림
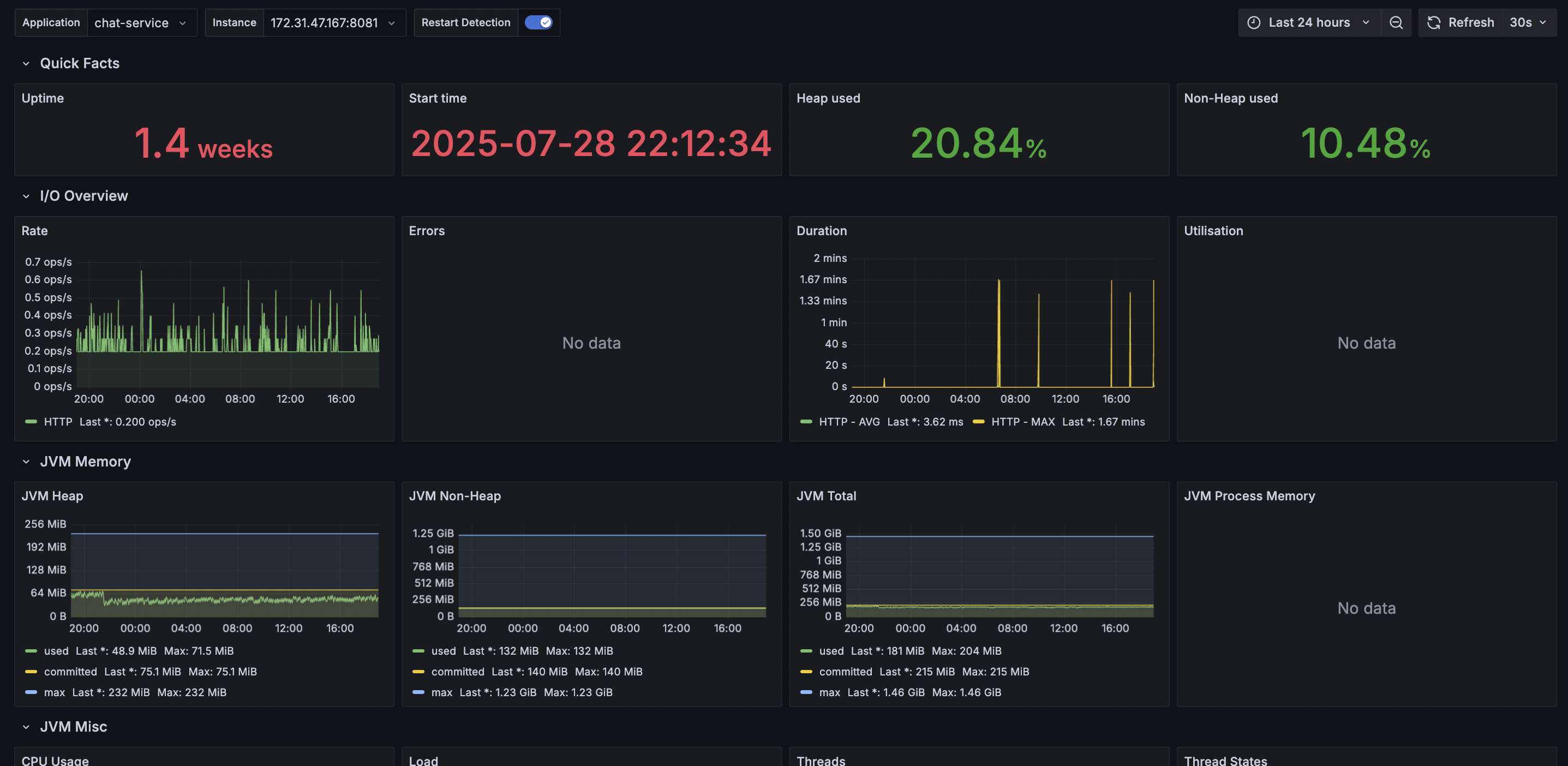
Grafana는 Prometheus와 Loki에서 가져온 데이터를 시각화하는 도구입니다. 단순히 그래프만 보여주는 게 아니라, 임계치를 설정해 알람을 받거나, 특정 구간의 이상치를 쉽게 찾아낼 수도 있습니다.
CLI에 찍힌 텍스트 로그만 보던 시절과 비교하면, 운영 효율성이 압도적으로 좋아졌다고 볼 수 있습니다.
Loki & Promtail:
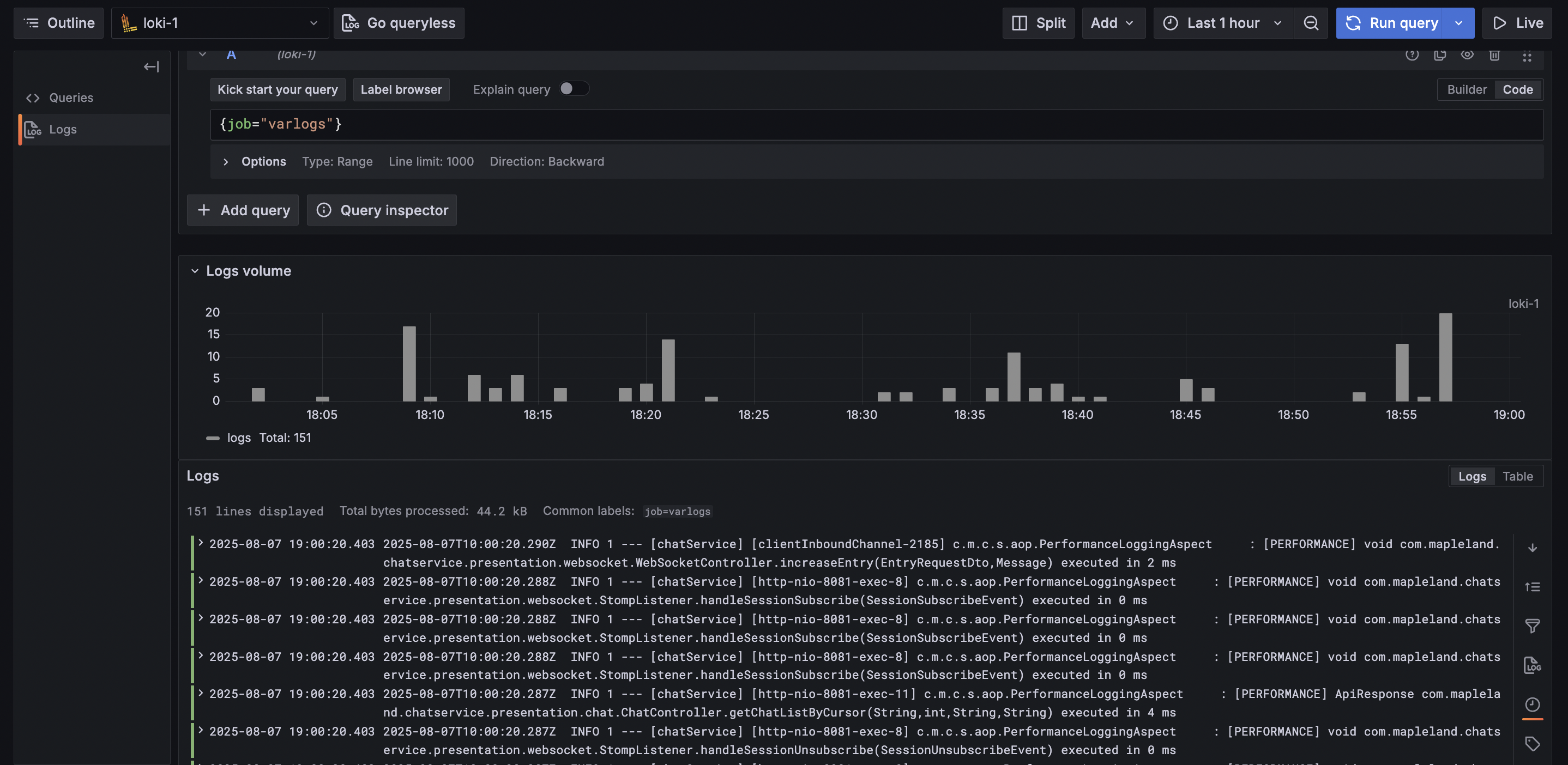
Grafana는 Loki에 저장된 로그를 LogQL이라는 쿼리 언어를 통해 필요한 로그만 빠르게 검색할 수 있습니다.
Spring Boot 애플리케이션은 기본적으로 Logback(또는 Log4j2)을 통해 로그를 파일이나 콘솔로 출력합니다. 해당 로그를 Loki로 전달하기 위해 Promtail(Loki 공식 수집기)을 사용했습니다.
Promtail은 설정 파일에서 지정한 경로(예: 컨테이너 로그 디렉토리를 EC2의 /var/log/...에 볼륨 마운트) 를 file tailing 방식으로 감시하다가, 새로운 로그가 발생하면 이를 실시간으로 Loki로 Push합니다.
loki-config.yml
auth_enabled: true
server:
http_listen_port: 3100
grpc_listen_port: 9095
...
schema_config:
configs:
- from: 2024-01-01
// fileSystem 기반으로 간단하게 운영
store: boltdb-shipper
object_store: filesystem
schema: v11promtail-config.yml
server:
http_listen_port: 9080
grpc_listen_port: 0
# 마지막으로 읽은 로그 위치(offset)를 기록
positions:
filename: /tmp/positions.yaml
# 수집한 로그를 해당 경로로 Push
clients:
- url: http://loki:3100/loki/api/v1/push
scrape_configs:
- job_name: system
static_configs:
- targets:
- localhost
labels:
job: varlogs
# 해당 경로의 수집된 로그 파일들을 "file tailing" 방식으로 감시
__path__: /home/ec2-user/app/logs/*.log
docker-compose.yml
# docker-compose.yml
version: "3.8"
services:
prometheus:
image: prom/prometheus:latest
container_name: prometheus
user: "0:0" # 현재 호스트 사용자의 권한으로 실행
ports:
- "9090:9090"
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml # 설정 파일 마운트
- ./prometheus-data:/prometheus # Prometheus 데이터 영속화
networks:
- app-network
grafana:
image: grafana/grafana:latest
container_name: grafana
# user: "$UID:$GID"
ports:
- "3000:3000"
volumes:
- ./grafana-data:/var/lib/grafana # Grafana 데이터 영속화
depends_on:
- prometheus # Prometheus 먼저 실행
networks:
- app-network
loki:
image: grafana/loki:2.9.4
container_name: loki
ports:
- "3100:3100"
command: -config.file=/etc/loki/config.yml
volumes:
- ./loki-config.yml:/etc/loki/config.yml
- ./loki-data/index:/loki/index
- ./loki-data/chunks:/loki/chunks
- ./loki-data/boltdb-cache:/loki/boltdb-cache
- ./loki-data/wal:/loki/wal
- ./loki-data/compactor:/loki/compactor
networks:
- app-network
promtail:
image: grafana/promtail:2.9.4
container_name: promtail
volumes:
- /home/ec2-user/app/logs:/var/log # EC2의 실제 로그 디렉토리
- ./promtail-config.yml:/etc/promtail/config.yml
command: -config.file=/etc/promtail/config.yml
networks:
- app-network
networks:
app-network:
external: true
volumes:
prometheus-data:3. 마치며
Redis를 통한 제약 처리와 확장성 확보, Prometheus·Grafana·Loki를 통한 모니터링과 알림 체계 덕분에 비로소 “운영 가능한 서비스”에 가까워질 수 있었습니다.
아직은 작은 규모의 프로젝트였지만, 실무에서도 동일한 문제를 어떻게 풀어낼지에 대한 감을 얻을 수 있었던 경험이었습니다.
