본 내용은 원티드 프리온보딩 과정을 회고하는 목적으로 작성되었습니다.시작하며
실무경험이 없는 신입 개발자 입장에서 시스템 디자인에 대해 높은 이해도를 가지는 것은 쉽지 않습니다. 하지만, "내가 리더라면? 어떤 역량이 필요할까.. 어떻게 그 일을 해낼까?" 나는 사고력을 키우는 것은 중요하다고 생각합니다.
"전체 시스템을 파악하며 개발하는 개발자" 와 "주어진 기능을 개발하는 개발자" 중 전자가 되기 위한 학습 과정을 제 생각을 기반으로 간단하게 정리해보고자 합니다.
1. 사용자 수 증가에 따른 시스템 설계
소규모 사용자를 대상으로 하는 서비스 부터, 대규모 사용자 서비스를 위한 설계의 기본적인 개념과 기술들은 어떤게 있을까?
1-1. 단일 서버 구조
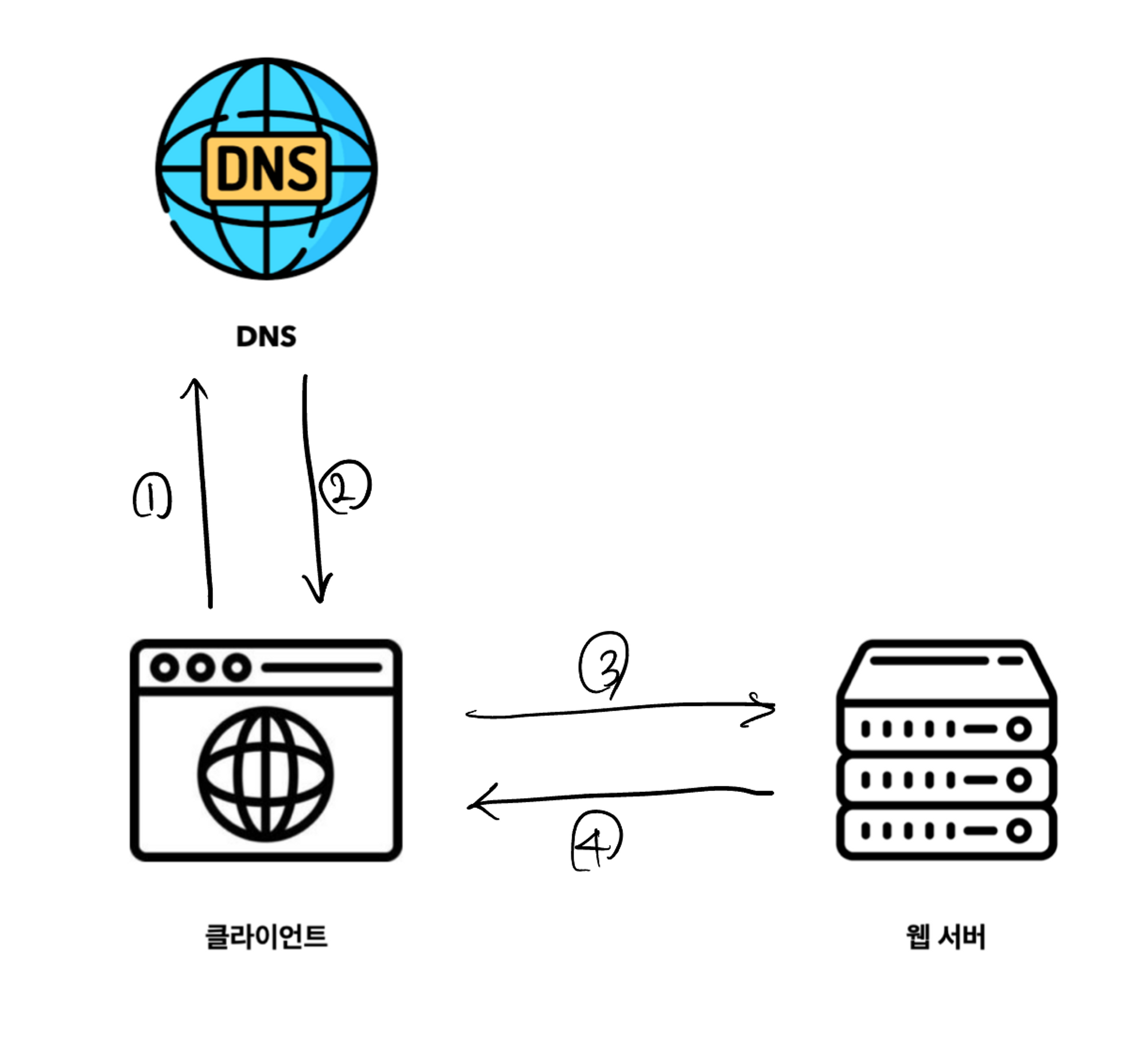
-
사용자(클라이언트)는 도메인 이름을 통해 웹 사이트에 접속합니다. 이를 위해선 DNS에 도메인 이름을 질의하여 IP 주소로 변환하는 과정이 필요합니다.
ex)
사람이 이해하기 쉬운 도메인 이름 (google.com) -> 컴퓨터와 네트워크 장치가 이해할 수 있는 IP 주소 (172.217.11.174)이를 통해 클라이언트는 IP 주소를 기억할 필요 없이 웹 사이트에 접근할 수 있습니다.
-
변환된 IP 주소가 반환됩니다.
-
해당 IP 주소로 HTTP(Hyper Text Transfer Protocol) 요청이 전달됩니다.
-
웹 서버는 요청에 따른 HTML, CSS, JavaScript 정적 파일을 응답합니다.
초기에는 대부분의 웹페이지가 정적(static) 이었습니다. 특별한 웹 프레임워크 없이도 간단한 웹 서버만으로 처리할 수 있었고 이러한 정적 웹페이지를 서비스하기 위해 사용되는 웹 서버로 Apache, Nginx 등이 사용되었습니다.
이후 동적인 웹페이지가 등ㅈ아하며 서버 사이드 스크립트, 언어와 프레임워크들이 개발되었습니다. 클라이언트의 요청에 따라 서버에서 적절한 데이터와 로직을 거쳐 정적 데이터를 생성하고 그 결과를 반환합니다.
1-2. 다중 서버(프론트엔드&백엔드 분리)
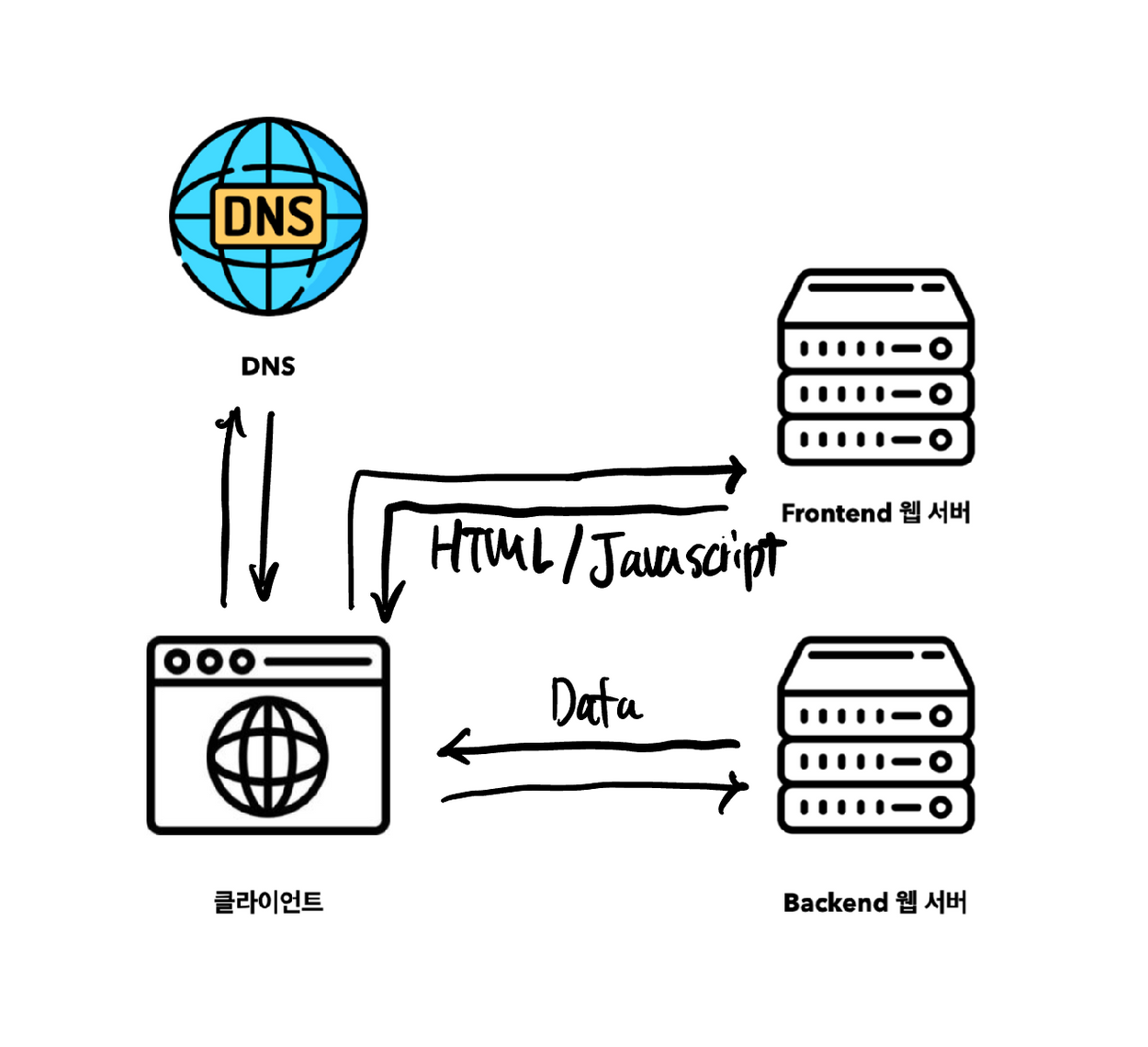
SPA(Single Page Application) 방식의 등장으로, 웹 페이지 렌더링에 필요한 JavaScript 코드를 최초 한 번의 통신에서 모두 송수신 하며 (초기 구동속도가 느림) 그 후로는 서버와 실시간으로 데이터를 주고받으며 화면을 동적으로 구성합니다.
이는 매번 정적 데이터를 서버에서 전송하던 단일 서버 구조보다 훨씬 효율적인 통신을 하게 만들어줍니다. (서버와의 통신은 데이터 전송 및 연산 작업이 대부분)
1-3. 데이터베이스
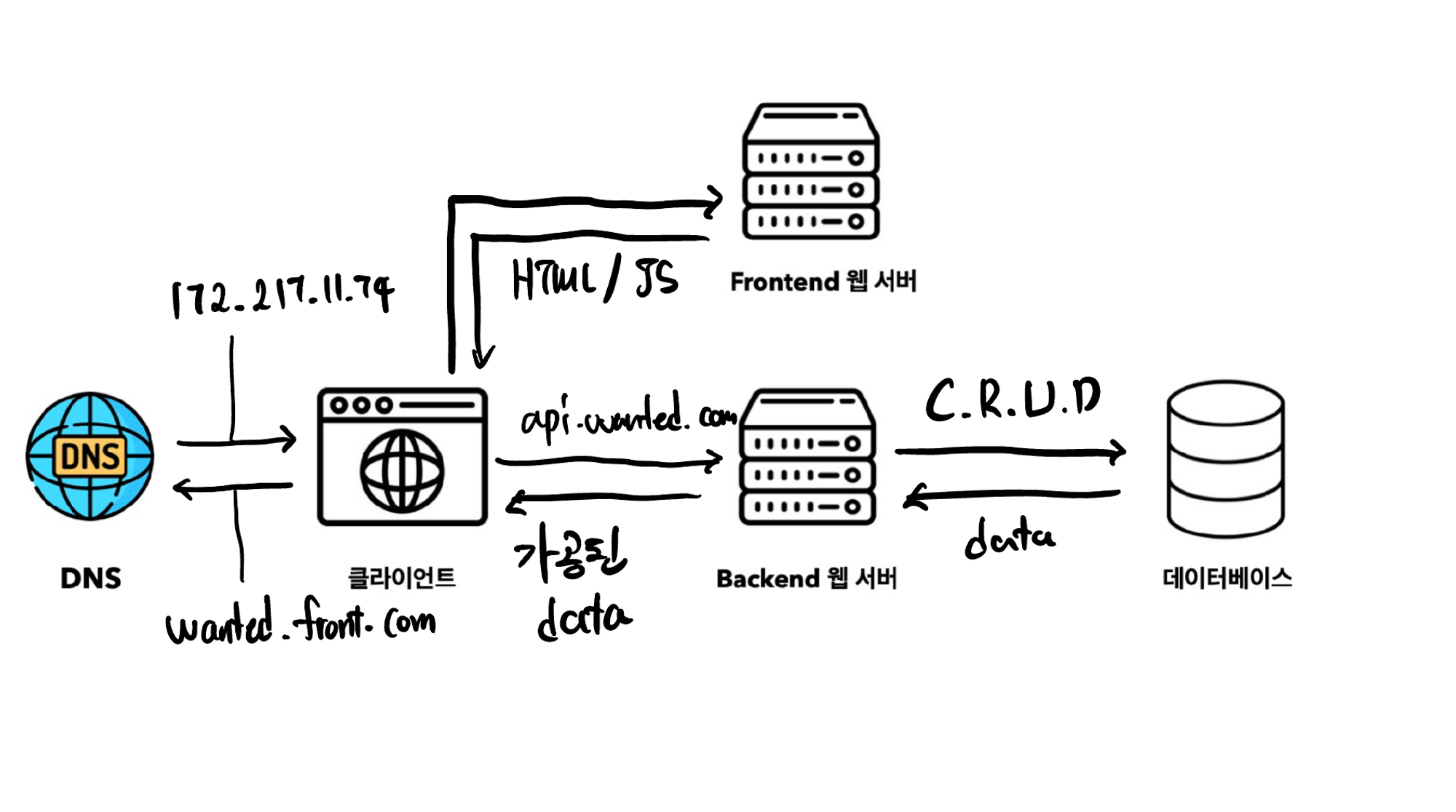
웹/모바일 클라이언트 처리 용도의 WAS와 데이터베이스 전용 서버를 분리함으로써 각각의 책임의 분리가 가능하고, 이는 독립적으로 유연하게 확장할 수 있는 구조가 됩니다.
1-4. Scale Up vs Scale Out
사용자 수가 점점 증가하게 된다면 더 이상 기존의 서버 한 대 만으로는 트래픽을 감당할 수 없게 됩니다.
이를 위해 트래픽을 감당할 수 있는 두 가지 방법 이 있습니다.
Scale Up (수직적 확장)
수직적 규모 확장으로 한 대의 서버 를 유지하며 하드웨어의 성능(CPU, RAM) 등의 성능을 높이는 방법입니다.
-
장점
하드웨어의 성능을 높이는 것으로 방법이 단순합니다. -
단점
한 대의 서버에 CPU, RAM 등을 늘리는 데에는 한계가 있습니다. 또한, 단일 서버는 장애에 대한 자동복구나 다중화 방안을 제시하지 않습니다.
Scale Out (수평적 확장)
수평적 규모 확장으로 더 많은 서버를 추가하여 부하를 분산시키고 성능을 개선합니다. Scale Up이 갖는 단점을 극복한 방법이며 대부분의 대규모 어플리케이션은 이 방법을 사용합니다.
-
장점
높은 확장성을 가지고 있습니다. -
단점
서버가 여러 대로 증설되면 각각의 IP 주소가 다르기 때문에, 사용자 입장에서는 여전히 동일한 URL로 접속하는 것이 가능하도록 해야합니다.
로드 밸런서(Load Balancer)
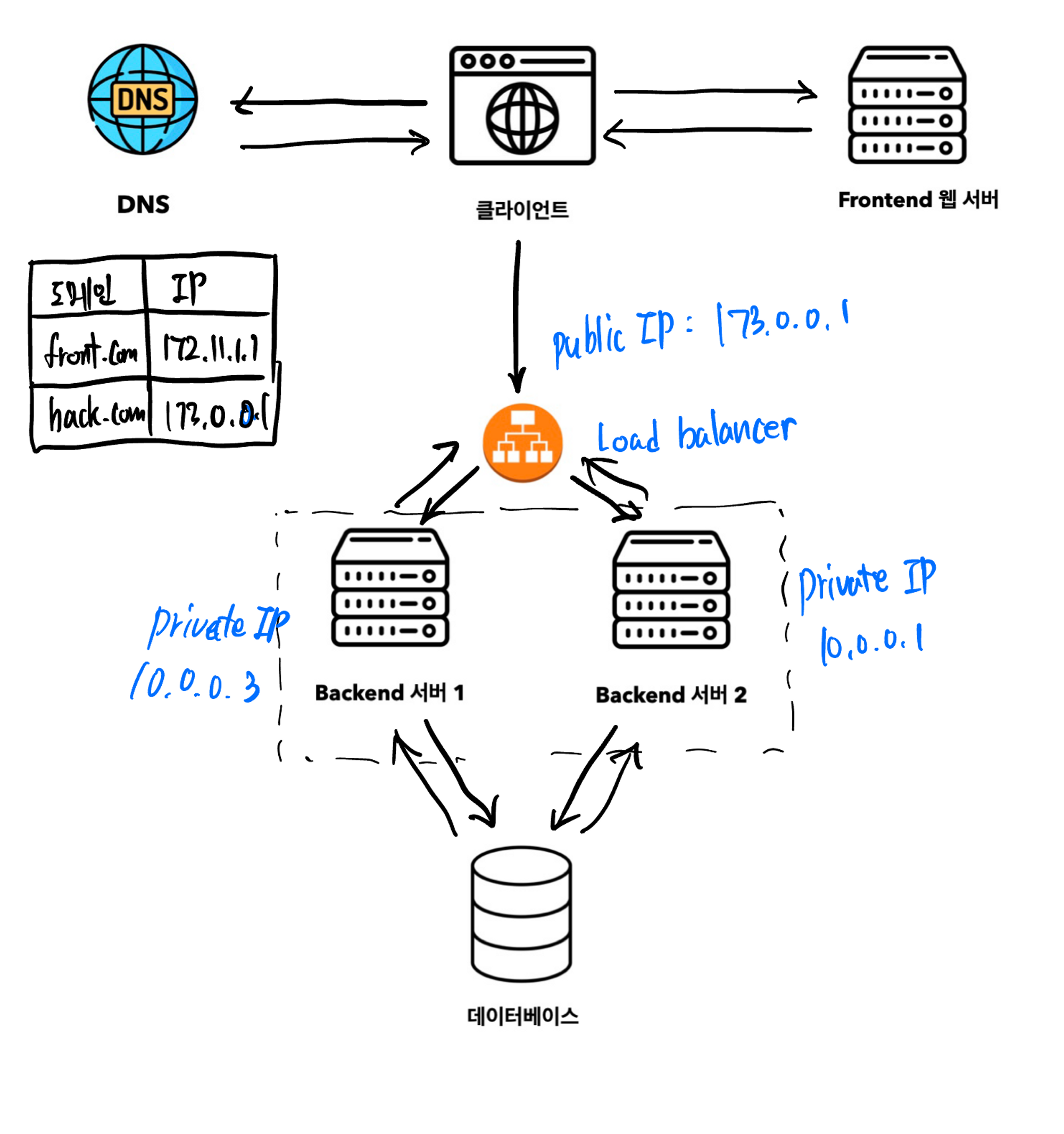
로드 밸런서는 여러 서버에 네트워크 트래픽이나 애플리케이션 요청을 분산하는 장치나 소프트웨어 입니다.

마치 동전 분리기..
주요 목적으로는 트래픽 병목현상을 해소시켜 성능을 향상시키고, 리소스 사용률을 최적화 합니다.
클라이언트로 발생하는 모든 트래픽은 1차적으로 로드 밸런서가 받으며, 부하 분산 집합에 속한 WAS에게 이를 고르게 분산하는 역활(Round Robin) 을 합니다. 이 외에도 다양한 주요 기능이 있습니다.
주요기능
- Proxy & 보안 기능
- 장애 탐지 및 자동 장애 복구
- 스케일링(확장) 기능
대표적인 로드 밸런서
- 소프트웨어 로드 밸런서: Nginx, Apahce HTTP Server
- 클라우드 기반 로드 밸런서: AWS Elastic Load Balancing, Google Colud Load Balancer, Azure
1-5. 데이터베이스 다중화 (Replication)
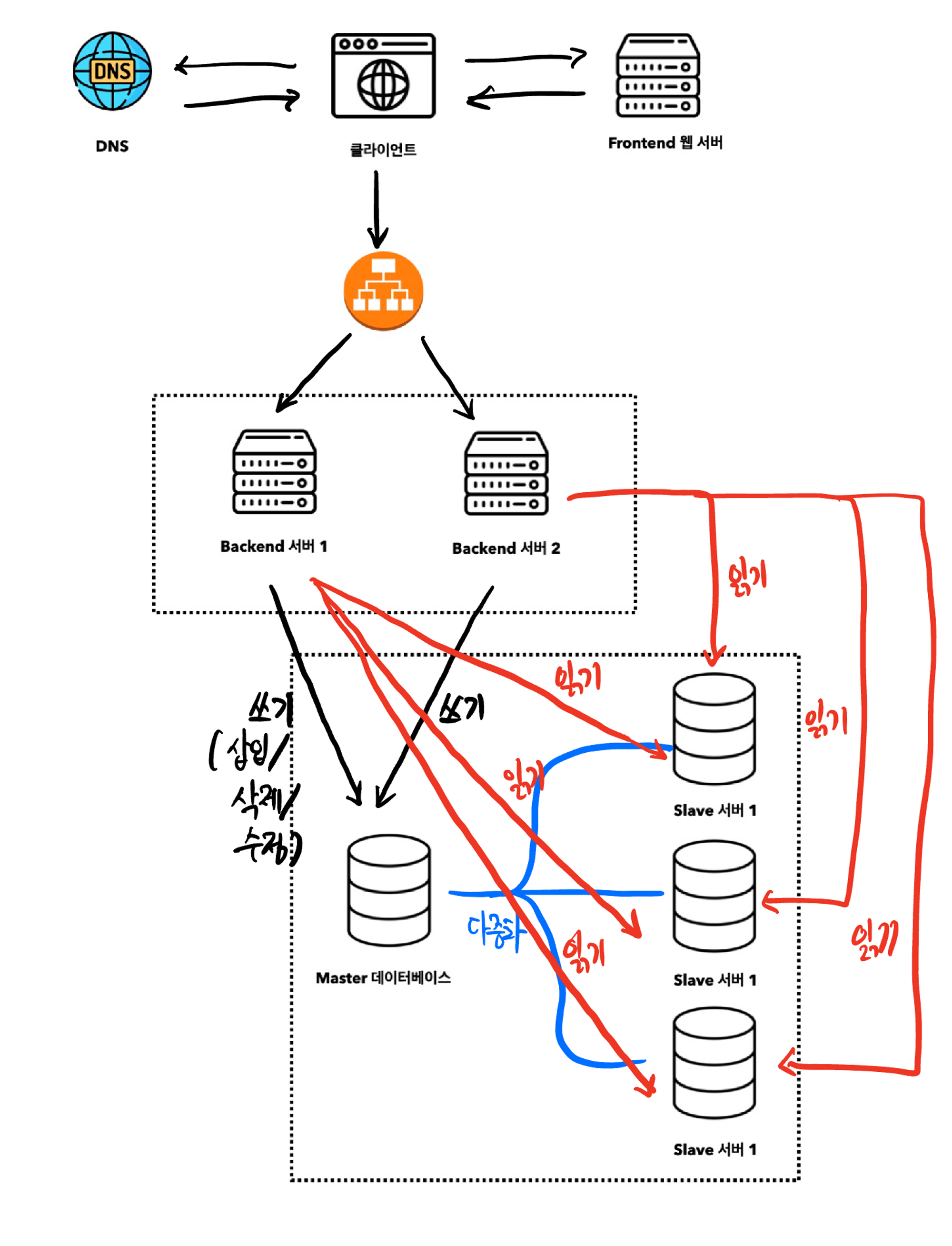
많은 DBMS에는 주(master)와 부(slave)의 구조로 DB를 설정하며, 주 서버에는 원본 데이터를 부 서버에는 그 사분을 저장합니다.
Master DB는 쓰기 연산(write operation)을 주로 처리하며 Slave DB는 Master로부터 데이터 사본을 받아오며 읽기 연산(read operation)을 처리합니다.
읽기 연산(select) 가 쓰기 연산(insert, delete update)에 비해 상대적으로 더 빈번하게 발생하므로 보통 Slave가 Master보다 많게 설계합니다.
이러한 데이터베이스 다중화는 사용자 증가에 따른 다양한 이점을 제공합니다.
-
성능:
Master-slave 다중화 모델에서 데이터 변경 연상는 주 데이터베이스가, 읽기 연산은 부 데이터베이스 서버로 분산되기 때문에 병렬로 처리할 수 있는 질의(Query)의 수가 늘어나고 동시에 처리할 수 있는 작업이 늘어나며 성능이 높아집니다. -
안정성:
만약 데이터베이스 서버중 일부가 자연 재해등의 (카카오 데이터 센터 화재사건 등) 이유로 일부가 멈추게 되어도 데이터를 물리적으로 떨어진 장소에 다중화 시킨다면 데이터를 보존할 수 있습니다. -
가용성:
데이터를 여러 지역에 다중화 및 복제해 둠으로써, 하나의 데이터베이스 서버에 장애가 발생하더라도 다른 서버에 있는 데이터를 가져와 서비스를 유지할 수 있습니다.
이러한 이점들을 통해 단일 서버보다 원활한 장애 탐지 및 자동 장애 복구가 가능합니다.
- 예시: AWS의 관계형 데이터베이스 서비스에서는 특히 Amazon Aurora와 같은 서비스가 장애 탐지 및 자동 장애 복구를 진행
Master 서버의 장애를 탐지 -> Slave(Replica or Secondary) 서버 중 하나를 새로운 Master로 승격 시키는 기능 제공
- 장애 탐지:
Amazon RDS 또는 Aurora는 주기적으로 DB 인스턴스의 상태를 체크하며 동작 문제를 감지 - 자동 장애 복구:
Master 서버가 다운된다면 가용중인 Slave 중 하나가 Master로 승격 (Slave가 다운된다면 가용 가능한 다른 Slave 혹은 Master 서버가 연산 작업 대체) - DNS 업데이트:
DB 엔드포인트의 DNS가 새로운 Master 서버를 가르키도록 업데이트. 이로 인해 애플리케이션은 DNS TTL(Time-to-Live)가 만료되면 새로운 Master 로의 연결을 시도. (DNS TTL은 DNS 레코드에 대한 정보가 캐싱된 상태를 나타냄. TTL 값은 DNS 캐시 서버에서 해당 DNS 레코드를 저장한 후, 해당 시간이 만료되면 레코드를 삭제 후 새로운 정보를 가져오도록 서버에 요청함) - Replica 재구성
이러한 자동 복구 기능은 고가용성을 갖춘 DB 환경을 쉽게 설정하고 운영할 수 있게 합니다.
하지만, 애플리케이션 측면에서도 복구 시간 동안의 DB 연결 및 예외 처리 전략을 잘 구현하는 것이 중요합니다.
참고문헌
원티드 교육자료
