본 내용은 원티드 프리온보딩 과정을 회고하는 목적으로 작성되었습니다.이번 게시물은 메모리 기반 캐싱을 통한 성능 개선에 관련한 내용입니다.
1-6. 캐시를 활용한 지연 시간(Laytency) 개선 - In Memory Storage
오늘날 서버의 응답 시간은 극도로 짧아야 하며 대부분의 경우 응답 시간이 500ms~700ms 사이라고 합니다. 하지만, 사용자의 증가, 시스템의 복잡성 증가는 지연 시간(Laytency) 를 증가시킵니다. 이를 개선하기 위해서는 캐시(cache) 를 적용하거나 정적 컨텐츠를 컨텐츠 전송 네트워크(CDN)로 이전하는 것이 효과적입니다.
캐시(Cache)
캐시는 자주 참조되는 데이터, 계산 비용이 큰 연산의 결과를 빠르게 접근 가능한 메모리에 저장하는 방식입니다.
예를들어, 웹 페이지를 새로 고칠때마다 데이터베이스를 호출하게 된다면 시스템의 성능에 매우 큰 영향을 끼칩니다. 애플리케이션의 성능은 데이터베이스를 얼마나 자주 호출하느냐에 크게 좌우되는데, 캐시는 이러한 성능 저하 문제를 해결하는데 크게 기여합니다.
캐시 계층(cache tier)
캐시 계층은 데이터베이스의 부하 감소 및 성능 향상을 위해 사용되며, 데이터를 임시로 저장하는 고속의 계층입니다.독립적인 확장이 가능하기 때문에 시스템의 유연성을 높입니다.
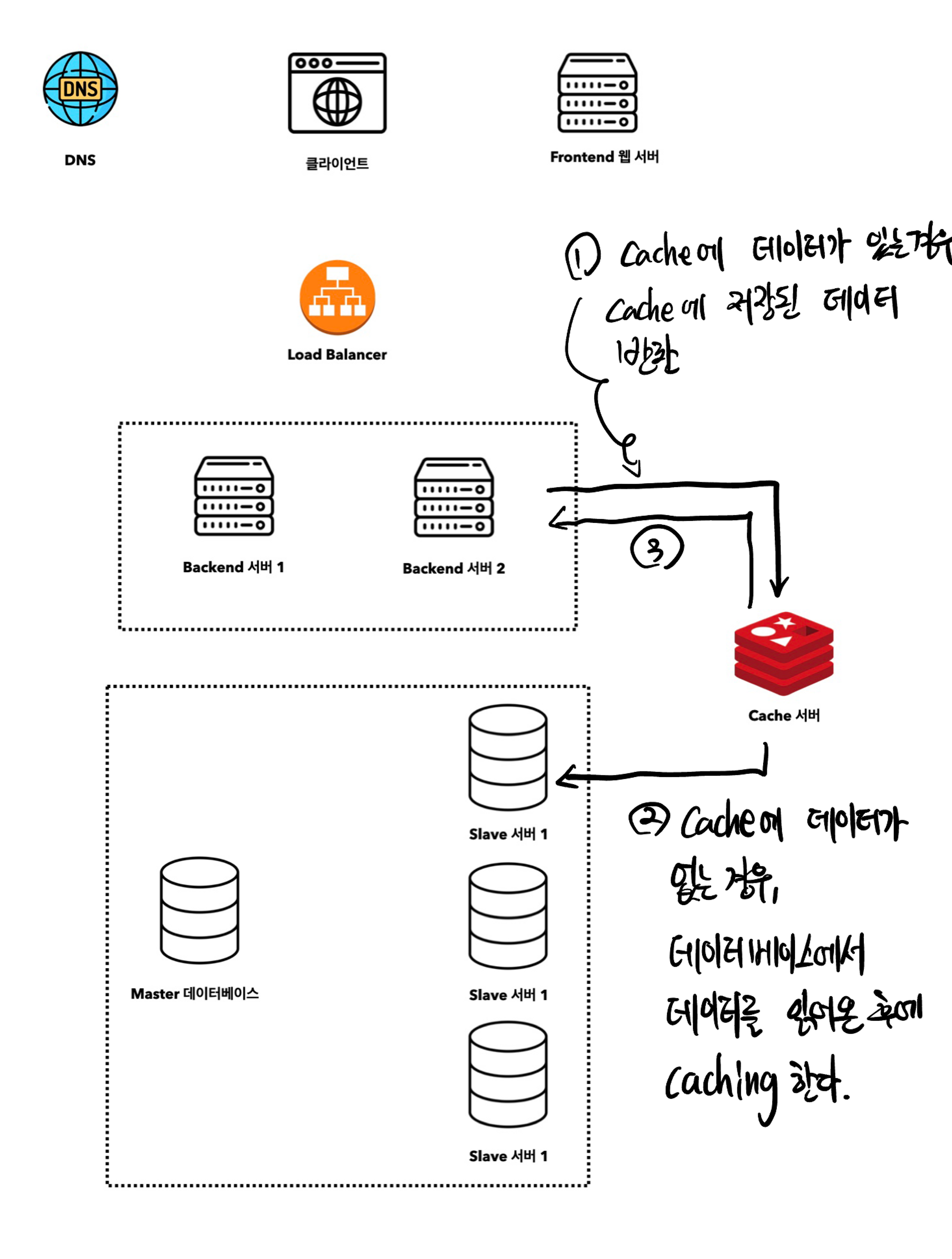
클라이언트의 요청을 WAS에서 받게되면,
- 먼저 Cache 서버에서 해당 응답이 있는지 확인합니다.
- 저장된 데이터가 있다면 클라이언트에 바로 반환합니다.
2-1. 저장된 데이터가 없다면 데이터베이스에서 정보를 조회하고, 그 결과를 캐시에 저장 및 클라이언트에 전달합니다.
이러한 방식을 읽기 주도형 캐시전략(read-through caching strategy)라고 합니다. 이외에도 데이터의 유형, 크키 및 엑세스 패턴에 따른 다양한 캐시 전략이 있습니다.
캐시 서버를 이용하는 방법
대부분의 캐시 서버들이 일반적으로 사용되는 프로그래밍 언어(Java 등) 로 API를 제공합니다.
import redis.clients.jedis.Jedis; // Redis를 Java에서 사용하기 위한 Jedis 라이브러리를 임포트합니다.
// Redis 서버에 연결합니다. 여기서는 로컬 호스트(localhost)에 연결합니다.
Jedis jedis = new Jedis("localhost");
// Redis 데이터베이스에 "products" 키에 "10,000개의 상품 데이터" 값을 저장합니다.
// 두 번째 매개변수인 3600은 데이터의 TTL(Time To Live)로, 초 단위로 설정됩니다.
jedis.set("products", "10,000개의 상품 데이터", 3600);
if (jedis.get("products") != null) {
// 반환
} else {
// 데이터베이스 조회 로직
// Redis 데이터베이스에 Key-Value 데이터 저장
// 반환
}
// Redis 연결을 닫습니다.
jedis.close();위의 코드와 같이 캐시를 먼저 조회후 데이터가 있다면 반환, 없다면 데이터베이스에서 정보를 조회 후 캐시에 저장 후 반환하는 과정을 거칩니다.
캐시 사용 시 주의사항
캐싱을 활용하면 빠른 응답 시간, 데이터베이스 요청 감소에 따른 부하 감소, 데이터를 로컬 메모리에 캐싱함으로써 네트워크 대역폭 절약 등의 장점이 있지만, 무조건 캐시를 사용하는 것은 옳지 않습니다.
데이터베이스의 내용이 변경된 경우 캐시와 데이터베이스 사이의 불일치가 발생할 수 있고, 메모리를 기반하기 때문에 메모리 부족 문제가 발생할 수도 있습니다.
그렇다면 캐싱을 사용할 때 어떤점을 고려해야 좋을까요?
-
어떤 상황에?
데이터 갱신은(쓰기) 자주 일어나지 않지만 참조(읽기)는 빈번하게 일어나는 경우 -
어떤 유형에?
캐시서버는 In Memory 저장소이기 때문에 재시작되면 캐시 내의 모든 데이터가 사라집니다. 따라서 휘발성 메모리에 저장되어도 괜찮은 데이터가 좋습니다. 따라서 중요한 데이터는 지속적 저장소에 저장해야 합니다.(DB, CloudStorage, FileSystem ...) -
보관 기간은?
TTL 변수를 통한 만료 정책을 마련해두자. 만료 기간이 너무 짧다면 DB조회가 너무 자주 일어나는 이슈가 발생할 수 있고, 만료 기간이 너무 길다면 갱신이 적어 원본가 차이날 가능성이 높아진다. -
데이터 일관성은?
데이터 일관성을 위해 데이터 저장소의 원본과 캐시 내의 사본이 같은지 여부를 판단해야 합니다. 따라서 저장소의 원본을 갱신하는 연산과 캐시를 갱신하는 연산이 단일 트랜잭션으로 처리되지 않는다면 일관성이 깨질수 있습니다.
만약, 여러 지역에 걸쳐 시스템을 확장한 경우 일관성 유지가 어려울 수 있습니다. 하나의 지역에서 데이터가 변경 되었을 때, 그 변경 사항을 모든 지역의 캐시에 반영해야하기 때문입니다. -
장애 대처는?
캐시 서버를 한 대만 두는 경우에 해당 서버는 단일 장애 지점(Single Point of Failure) SPOF가 되어버릴 가능성이 있습니다. 이는 전체 시스템에 영향을 끼칠 수 있기 때문에 여러 지역에 걸쳐 캐시 서버를 분산하는 것이 중요합니다. -
메모리 크기는 어느정도?
서버나 장치에 사용 가능한 전체 메모리, 그 중에서 캐시에 할당할 수 있는 메모리 사용량을 고려해야 합니다. 메모리 부족 상황을 피하기 위해 다른 애플리케이션들이 필요로 하는 메모리도 고려해야 합니다. -
데이터 방출(eviction) 정책이란?
캐시의 저장공간이 가득 차면 기존의 데이터를 내보내고 캐시 데이터를 추가합니다. 그래서 캐시 방출 정책은 어떤 데이터를 캐시에 저장할 것인지, 언제 그 데이터를 제거하거나 갱신할 것인지를 경하는 규칙입니다.
대표적으로 LRU(Least Recently User) 정책은 최근에 사용된 항목이 미래에도 사용될 확률이 높다는 가정에 기반하여, 가장 사용한지 오래된 항목을 먼저 제거합니다. 다른 정책으로는 Queue 자료구조 처럼 FIFO(First In First Out) 정책으로 가장 먼저 캐시에 들어온 데이터를 가장 먼저 내보내는 정책입니다.
1-7. 캐시를 활용한 지연 시간(Laytency) 개선 - CDN
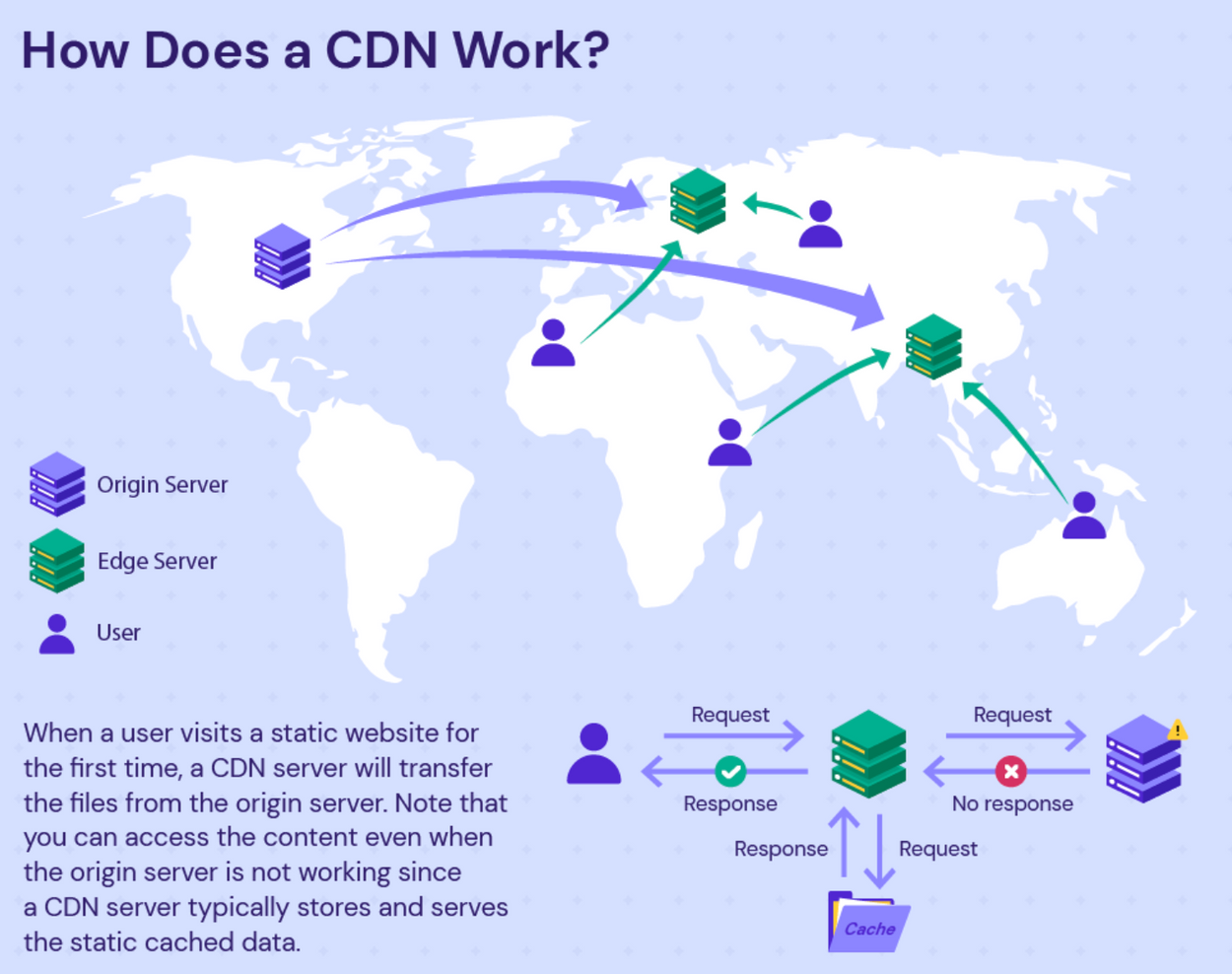
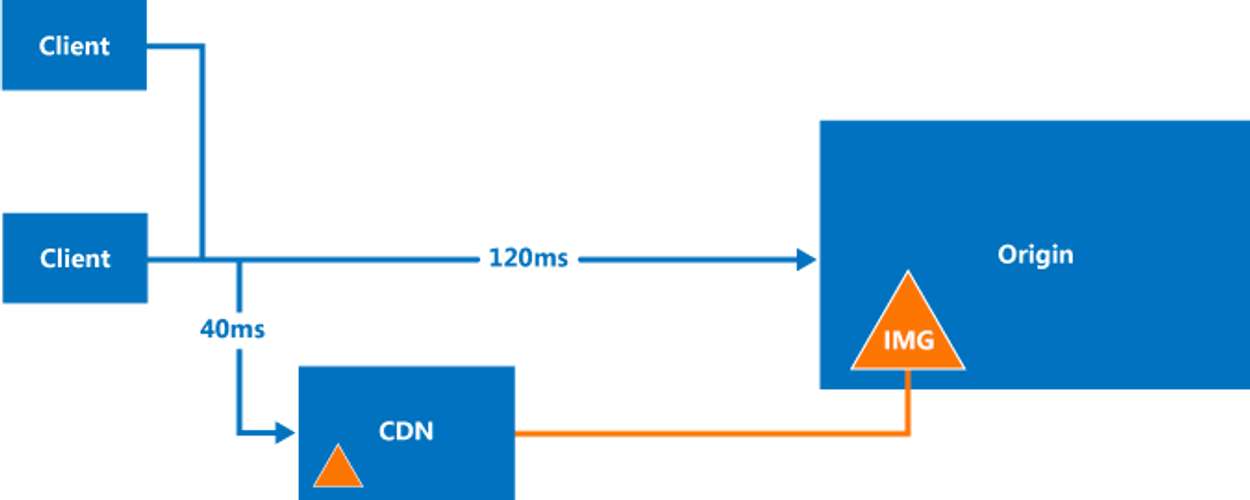
CDN(Content Delivery Network)은 전세계 여러 위치에 지리적으로 분산된 서버 네트워크로, 사용자에게 정적 컨텐츠(Static Content) 를 더 빠르고 안정적으로 제공하기 위해 설계되었다고 합니다.
만약, 서울에 있는 철수가 뉴욕에 있는 웹 서버에 접속하여 동영상을 보려고 할 때, 미국까지의 물리적인 거리와 네트워크 지연으로 인해 버퍼링이나 지연이 발생할 수 있습니다. 하지만! 해당 동영상이 한국에 있는 CDN 서버에 복제되어 있다면? 비교적 가까운 한국의 CDN 서버에서 동영상의 빠른 시청이 가능합니다.
간단히 말하면, CDN은 전세계 여러 곳에 데이터를 복제하고 근처의 사용자들이 그 데이터에 빠르게 접근하도록 도와주는 시스템입니다.
CDN(Content Delivery Network)의 동작 원리
-
콘텐츠 복제
원본 서버(Origin Server)의 컨텐츠(정적 데이터)를 여러 지역에 있는 CDN 서버에 복제합니다. -
요청 라우팅
사용자가 정적 컨텐츠(이미지, 비디오, CSS, JS등)에 접근시에 CDN은 사용자의 가까운 위치나 최적의 조건을 갖춘 CDN 서버로 요청을 라우팅(어떠한 엔드포인트로 전달할지 결정하는 프로세스) 합니다. -
캐시 검사
선택된 CDN 서버는 요청된 콘텐츠가 캐시에 있는지 확인합니다.
- 캐시에 존재하는 경우: 캐시된 콘텐츠를 바로 제공.
- 캐시에 존재하지 않는 경우: 원본 서버나 다른 CDN 서버로 부터 해당 콘텐츠를 가져와 사용자에게 제공하고, 자신의 캐시에도 저장합니다. 원본 서버는 WAS가 될 수도 있고, Amazon S3와 같은 클라우드 기반 저장소가 될 수도 있습니다.
-
캐시 갱신
정기적인 원본 서버와의 동기화, TTL 변수를 참고하여 오래된 콘텐츠를 갱신하거나 삭제합니다. -
보안 및 최적화
많은 CDN 콘텐츠를 사용자에게 전송하기 전 보안 및 성능 최적화 기능(SSL/TLS, 웹 컨텐츠 압축 등) 을 제공합니다.
Amazon Web Services (AWS) CloudFront, Microsoft Azure CDN, Akami 등의 CDN 서비스를 제공하는 기업이 있습니다.
참고문헌
원티드 교육자료
