Ensembles
- 여러 개의 머신러닝 모델을 결합하여 개별 모델보다 더 강력한 성능을 달성하는 기법
- 모델 학습 과정에서만 최적화
- 가정 : 여러 모델의 예측을 결합함으로써 각 각의 모델이 가질 수 있는 특정 유형의 오류를
상쇄시킬 수 있다. - 방법 : Bagging, Boosting, Stacking
배깅 Bagging
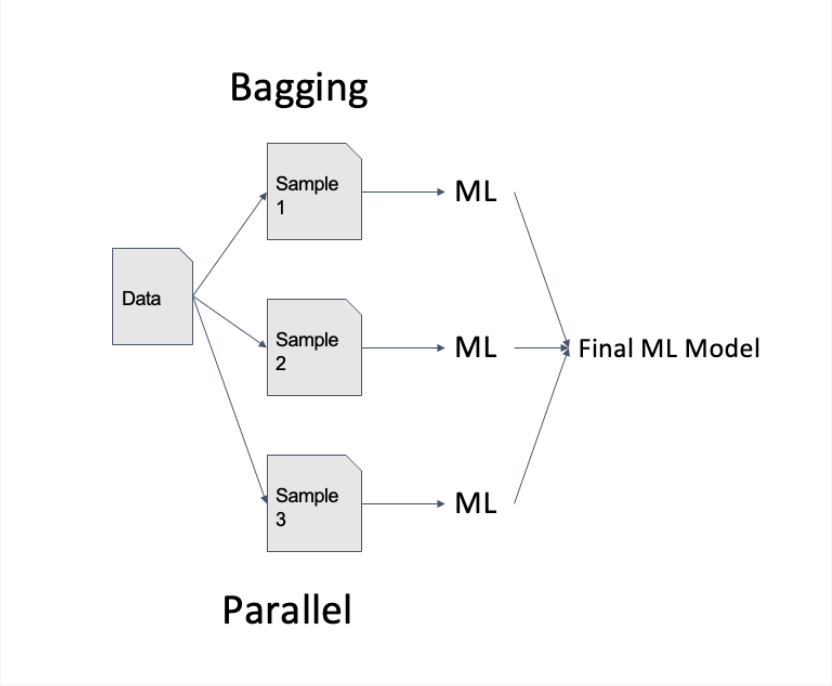
- Bootstrap Aggregating의 줄임말
- 여러 개의 모델이 서로 다른 데이터 샘플에 대해 학습하고, 그 결과를 통합하는 방식
- Random Forest가 대표적 : 다수의 Decision Trees를 학습시키고, 각 트리의 예측을
평균내거나 다수결로 결정하여 최종 예측을 도출 - 모델의 variance을 감소시키고 overfitting을 방지하는데 유용
부스팅 Boosting
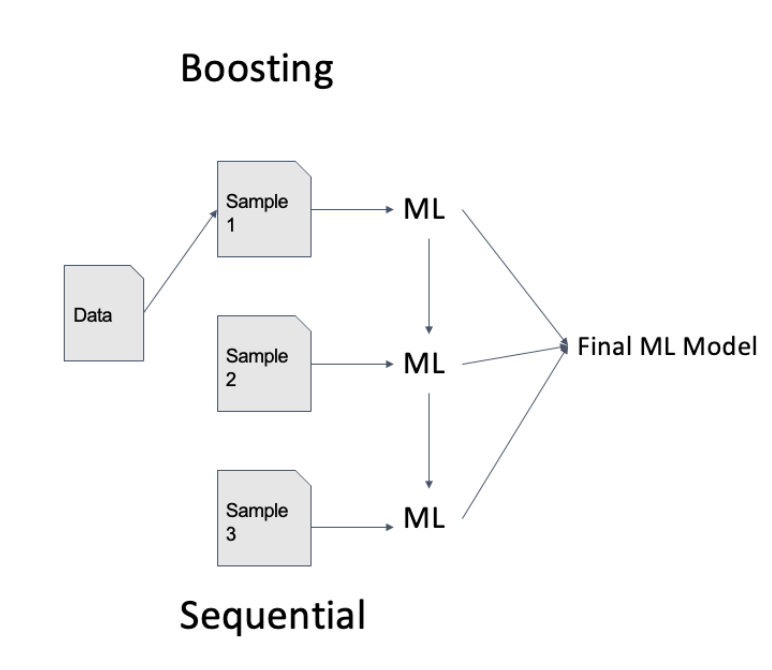
- Weak Learners를 순차적으로 학습시키는 방법
- 이전 학습기Model이 잘못 예측한 사례에 더 많은 가중치를 두어 오류를 개선해 나감
- AdaBoost가 대표적 : 잘못 분류된 데이터 포인트에 더 많은 가중치를 할당하여 새로운
분류기가 그 오류를 바로잡도록 함 - XGBoost, Grandient Boosting : 각 각의 반복에서 손실함수를 최소화하는 방향으로
모델을 업데이트 - 정확도가 올라갈 수 있으나, overfitting에 취약할 수 있음
스태킹 Stacking
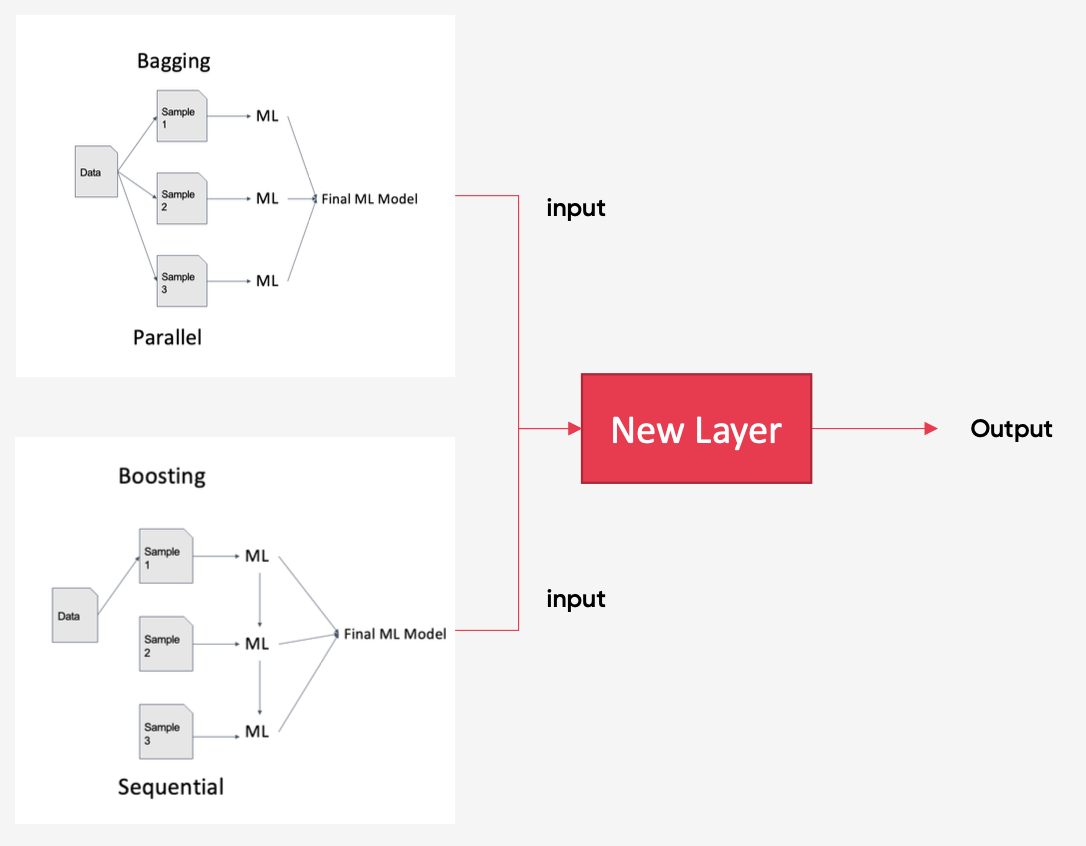
- 여러 다른 모델의 예측을 새로운 데이터로 사용하여, 추가적인 모델 메타 모델 을
학습시키는 방식 - 여러 모델의 예측을 입력으로 사용하여 최종 예측을 결정하는 모델
- 각기 다른 모델의 예측력을 결합하여 더 정확한 예측을 생성하는데 사용
AutoML
 출처: kr.mathworks.com
출처: kr.mathworks.com
- 머신러닝 모델을 개발하는 과정을 자동화하기 위한 도구와 기술의 집합
- 전통적인 머신러닝 프로젝트는 데이터 전처리, Feature engineering, HyperParameter Tuning 등 다양한 단계를 필요로 하며, 각 단계는 상당한 전문 지식과 시간을 요구
- AutoML은 이러한 복잡성을 줄이고, 사용자가 빠르고 효율적으로 모델을 구축할 수 있게 도움
- ML 전문가가 아닌 사용자도 머신러닝 모델을 개발하고 배포할 수 있게 함으로써, 머신러닝 접근성을 크게 향상시킴
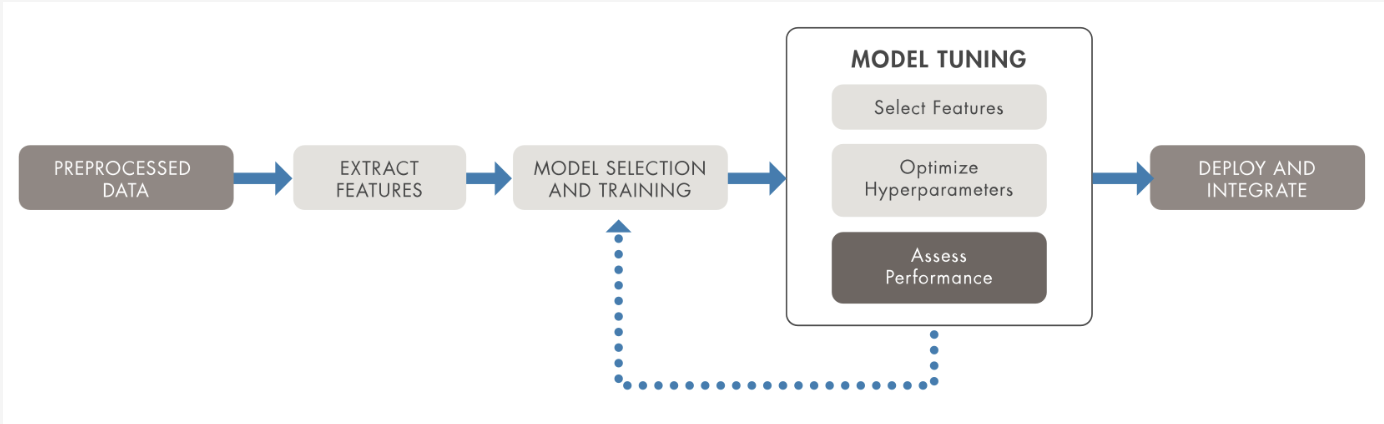
핵심 기능 (포함사항)
- 데이터 전처리 : 결측치를 처리하고, 변수를 변환하는 등의 Data Cleansing과 준비 과정을 자동화
- Feature Engineering : 가장 유용한 변수를 선택하고, 새로운 feature를 생성하여 모델의 예측력을 향상
- Model Selection : 다양한 머신러닝 알고리즘을 자동으로 시험해보고, 문제에 가장 적합한 모델을 찾음
- Model Learning Hyper Parameter Tuning : Grid Search, Random Search, Bayesian Optimization과 같은 전략을 사용하여 모델의 HyperParameter를 자동으로 조정
- Model Evaluation : Cross Validation과 같은 방법을 사용해 모델을 평가하고, 가장 성능이 좋은 모델을 자동으로 선택
대표 도구
-
Google Cloud AutoML : 사용자가 구글 클라우드의 강력한 인프라를 활용하여 자신의 데이터에 적합한 머신러닝 모델을 자동으로 생성하고 배포할 수 있게 해주는 서비스. 비전, 언어, 번역 등의 다양한 API를 제공하여 구체적인 문제에 적용할 수 있음

-
H20 AutoML : 오픈 소스 기반으로, 다양한 알고리즘을 자동으로 시도해보고 Stacking 기법을 사용하여 최종 모델을 생성. 사용이 간편하고 여러 알고리즘을 지원하여 뛰어난 성능의
모델을 생성할 수 있음

-
Auto sklearn : Scikit learn 기반의 AutoML 도구로, 특히 분류와 회귀 문제에 적합. Bayesian Optimization을 통해 Model과 Hyper parameter를 선택하여 Pipeline 구성 요소를
자동으로 조합하여 최적의 Solution을 제공

https://automl.github.io/auto-sklearn/master/

이기적이타주의자