Class Imbalance
Class Imbalance란 무엇인가?
- 기계 학습과 분류 문제에서 발생하는 현상 중 하나, 클래스 간의 데이터 불균형을 나타내는 개념
- 하나의 클래스가 다른 클래스에 비해 데이터 포인트 수가 현저히 적을 때 발
- 예 희귀 질병을 감지하는 분류 모델에서 질병이 있는 경우 양성 클래스 데이터가 드물게 발생하는 경우
Class Imbalance가 발생하는 이유?
- 현실 세계의 데이터는 종종 불균형한 데이터 분포를 갖음 대부분의 거래가 정상적인 신용 카드 거래이고, 사기 거래는 드물게 발생
- 데이터 수집 과정에서 클래스 불균형이 발생 특정 클래스에 대한 Sampling 오류, Data 수집 방법, Labeling 오류
Class Imbalance 중요성
- 실제 ML 응용 분야에서 많이 발생하며, 이를 무시하면 심각한 문제를 초래할 수 있음
- 모델 편향 : 모델이 소수 클래스를 올바르게 식별하지 못할 수 있음
- 비용 고려 : 소수 클래스의 중요도가 높은 경우, 이를 반영하지 않으면 예측의 비용이나 성능이 실제 상황과 맞지 않을 수 있음
- 평가 지표의 왜곡 : 정확도와 같은 평가 지표가 왜곡될 수 있으며, 실제 모델의 성능을 평가하기 어렵게 만듬
Class Imbalance 해결 필요성
- Class Imbalance 문제를 해결하려면 적절한 기술과 전략을 적용 필요
- 적용을 통해서 모델 성능을 향상시키고, 실제 비즈니스 문제에 더 정확한 예측을 제공할 수 있음
Class Imbalance 영향성
Class Imbalance가 모델에 미치는 영향
- 모델 편향 : 소수 클래스를 정확하게 예측하지 못할 가능성이 높음
- 오분류와 비용 : 소수 클래스를 무시하는 경향으로 실제에 큰 문제를 일으킬 수 있음 의료 분야에서 희귀한 질병을 감지하는 모델의 경우, 해당 질병을 놓치는 것은 치명적일 수 있으므로 오분류에 따른 비용이 높을 것임
모델 성능 지표에 미치는 영향
- 평가 지표의 왜곡 : Accuracy는 일반적으로 Class Imbalance에 대한 적절한 지표가 아님 모든 클래스를 다수 클래스로 예측하는 모든 예측이 부정 이라는 간단한 전략으로 높은 정확도를 얻을 수 있음
- Accuracy 외에 precision, recall, f1 score 등의 성능 지표를 고려해야 함
- ROC Curve and AUC
- ROC Curve : 거짓 양성 비율FPR에 대한 진짜 양성 비율TPR의 변화를 시각화
- AUC : ROC 곡선 아래 영역으로, 모델의 성능을 요약하는 지표
- 성능 지표를 신중하게 선택해야 함. 문제의 특성과 비즈니스 요구 사항에 따라 최적의 모델 평가 지표를 설정해야함
Class Imbalance 다루기
Class Imbalance 조절의 목표
- 소수 클래스에 대한 모델 성능을 향상시키는 것
- 오분류 비용을 줄이고 모델의 실용성을 향상시킬 수 있음
Class Imbalance 조절 방법의 대분류
- 데이터 기반 접근법 : Resampling 으로 데이터 수를 조절하여 클래스 간 균형을 맞춤
- ML Algorithm 접근법 : model parameter를 조절하여 class imbalance를 고려하도록 모델을 Tuning
Resampling
OverSampling
SMOTE (Synthetic Minority Over-sampling)
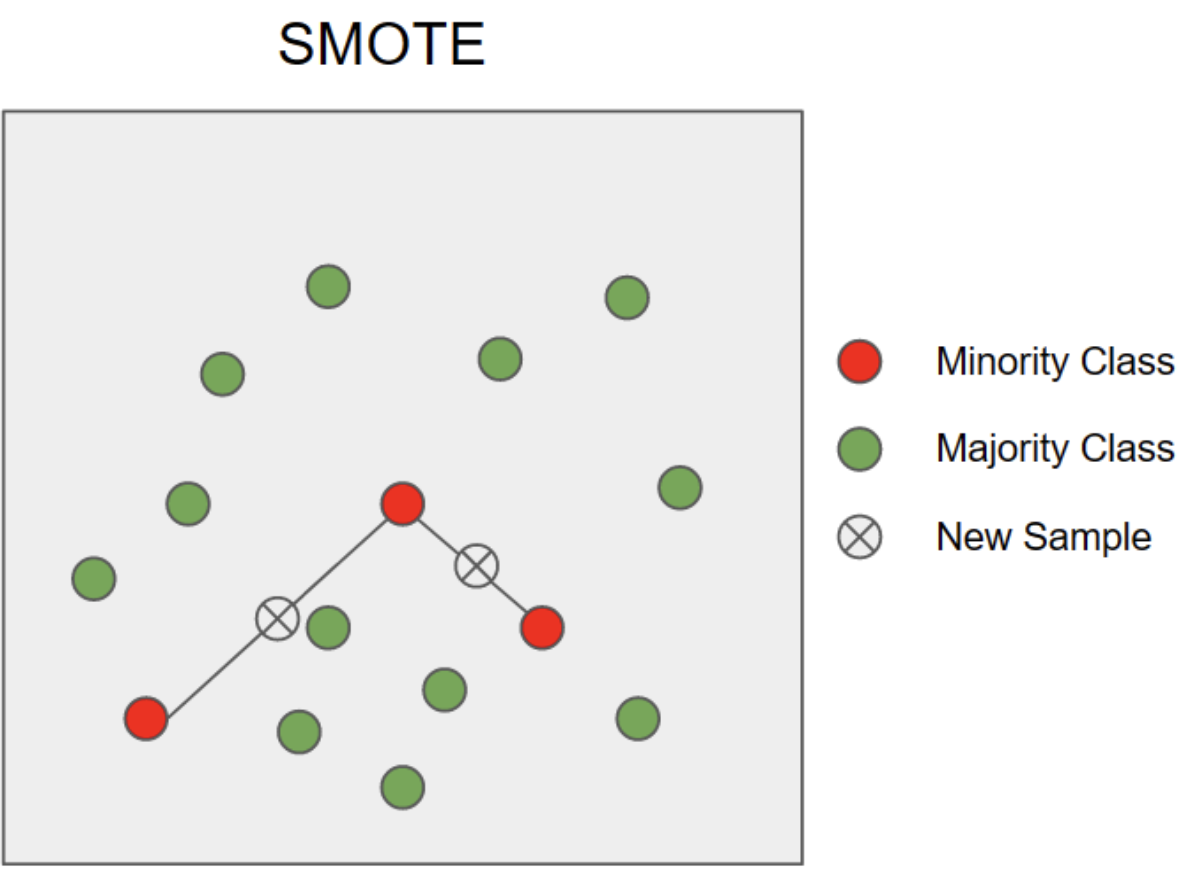
- 소수 클래스 데이터 포인트들을 기존 데이터를 활용하여 데이터를 균형화하는 방법
- 새로운 데이터 포인트는 소수 클래스 데이터 포인트와 그 주변의 이웃 데이터 포인트 랜덤한 데이터를 선택 사이를 보간하여 생성
- 장점 : 다양한 데이터 생성이 가능하며 모델의 일반화 능력을 향상시킬 수 있음
- 단점 : 데이터 중복이 발생할 수 있음
ADASYN Adaptive Synthetic Sampling
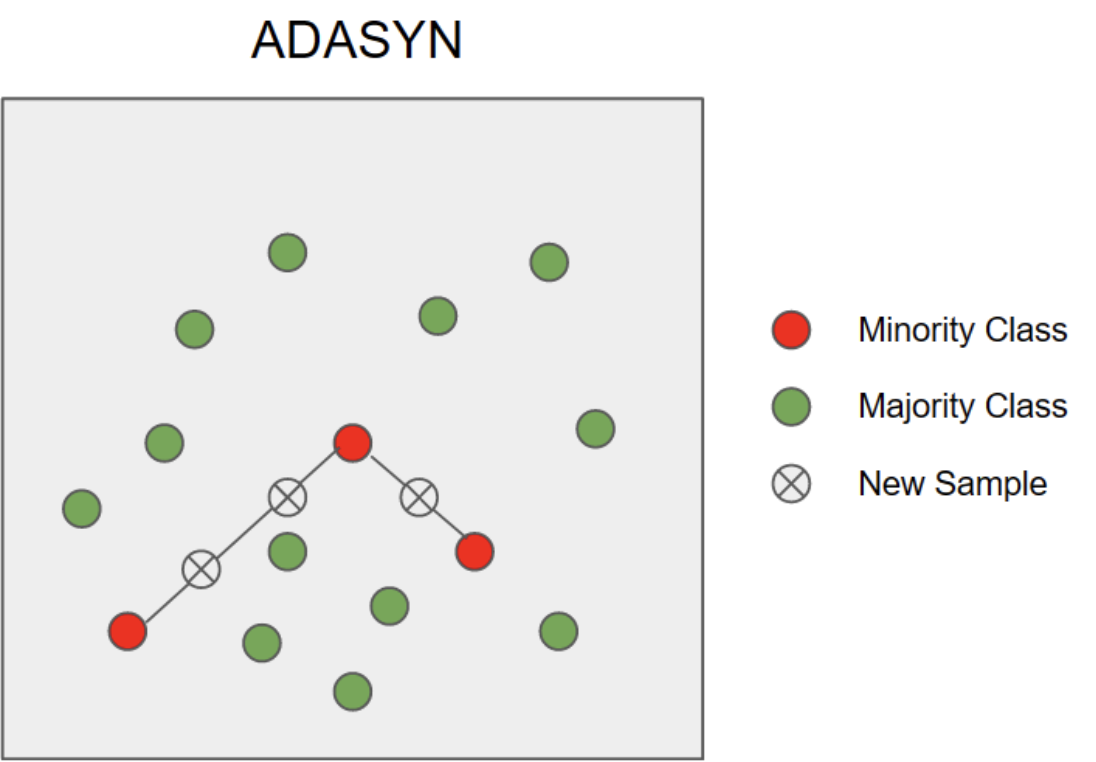
- 소수 클래스 데이터 포인트들을 기존 데이터를 활용하여 데이터를 균형화하는 방법
- 소수 클래스 데이터 포인트의 가중치를 계산하고, 높은 가중치를 가지는 데이터 포인트에 대해 더 많은 합성을 수행
- 가중치는 데이터 분포와 클래스 간 거리에 따라 동적으로 조정. 거리가 가까운 데이터 포인트에 대한 합성이 더욱 강조됨
- 장점 : 데이터 분포 거리 에 더욱 더 적응적으며, 클래스 간 거리에 따라 합성을 조절하여 불균형을 더 효과적으로 다룰 수 있음
- 단점 : SMOTE에 비해 더 복잡하며 계산 비용을 높을 수 있음
UnderSampling
Tomek Links UnderSampling
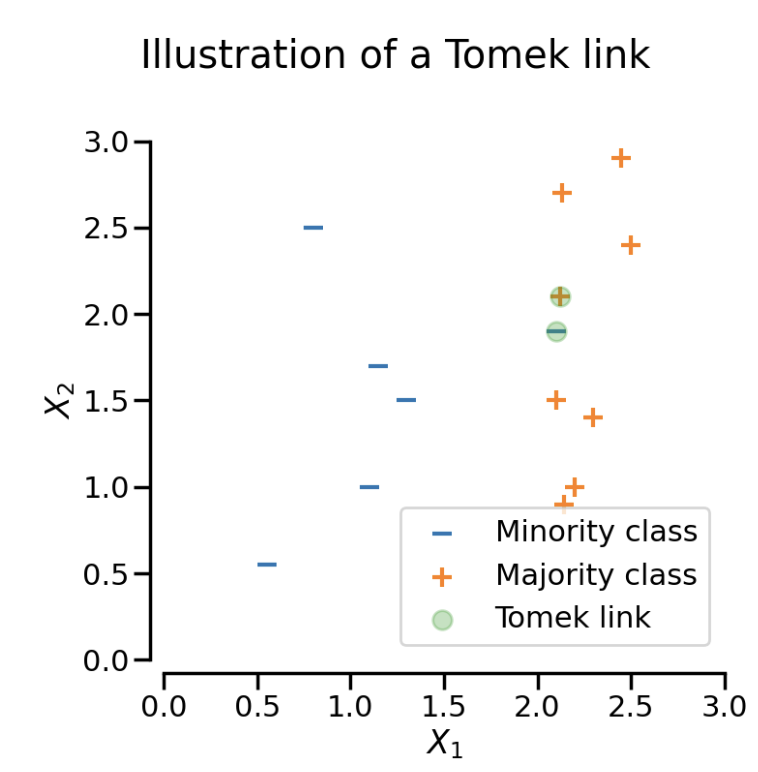 출처 : https://imbalanced learn.org/
출처 : https://imbalanced learn.org/
- 클래스 간 거리가 가까운 데이터 포인트 쌍 중에서 다수 클래스의 데이터를 제거하는 방법
- 다수 클래스와 소수 클래스 사이의 모든 데이터 간의 거리를 계산
- Tomek Links 식별 : 서로 다른 클래스에 속한 데이터 포인트 쌍 중에서 클래스 간 거리가 가장 가까운 데이터 포인트 쌍을 의미
- Tomek Links 제거 : 식별된 Tomek Links를 데이터에서 제거
ENN Edited Nearest Neighbors
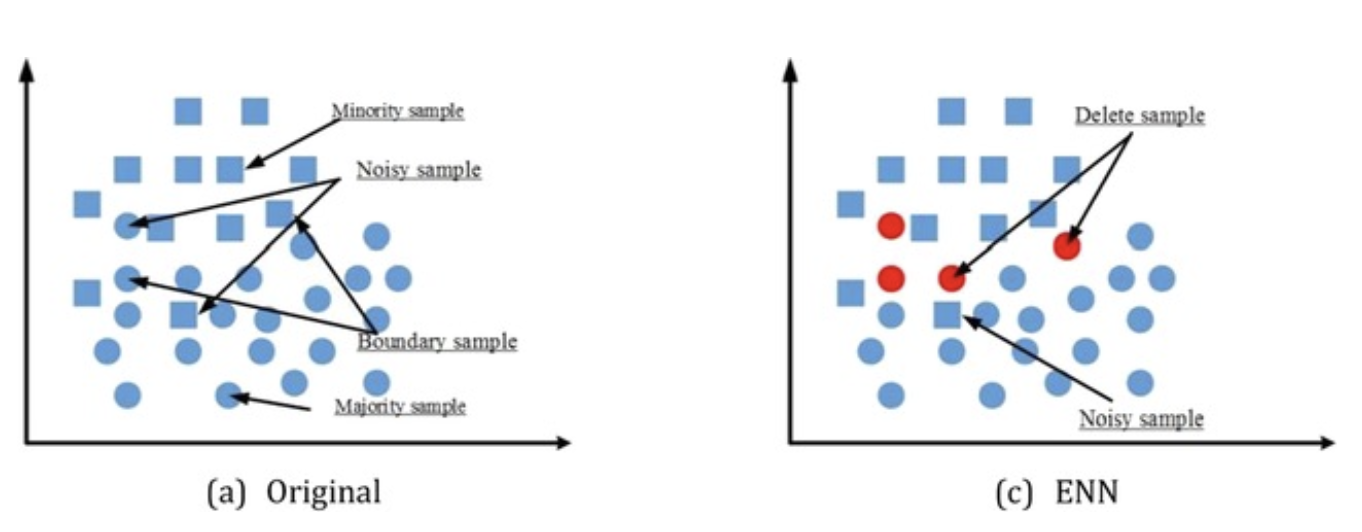 출처 : A hybrid sampling algorithm combining synthetic minority over sampling technique and edited nearest neighbor for missed abortion diagnosis, Fangyuan Yang
출처 : A hybrid sampling algorithm combining synthetic minority over sampling technique and edited nearest neighbor for missed abortion diagnosis, Fangyuan Yang
- 클래스 간 거리가 가까운 데이터 포인트 쌍 중에서 다수 클래스의 데이터를 제거하는 방법
- 다수 클래스 데이터 포인트에 대해, 해당 데이터 포인트와 가장 가까운 k개의 이웃을 찾음
- 다수 클래스 데이터 포인트 중에서 소수 클래스로 잘못 분류된 데이터 포인트를 식별
- 이런 오분류된 데이터 포인트를 제거하여 다수 클래스 데이터를 정제
- 모델이 잘못 분류하는 오분류 데이터를 제거하고 모델의 성능을 향상
TomekLinks와 ENN 공통점
- 클래스 간 거리를 고려하여 데이터 포인트를 수정하며, Class Imbalance 문제를 해결해서 모델 성능을 향상시키는 공동 목표 가짐
TomekLinks와 ENN 차이점
- Tomek Links는 클래스 간 거리가 가까운 데이터 포인트 중에서 서로 다른 클래스 에 속한 데이터 쌍을 식별하여 제거
- ENN은 각 다수 클래스 데이터 포인트에 대해 가장 가까운 이웃을 기반으로 오분류된 데이터 소수 데이터로 판별되는 것 를 찾아내서 제거
- Tomek Links는 클래스 간 경계를 명확하게 만드는 것이 목적
- ENN은 다수 클래스 데이터를 정제하고 오분류를 줄이는 데 목적
Combined Sampling
SMOTEENN
- SMOTE와 ENN 두 기술을 함께 사용하여 클래스 불균형을 해결
- SMOTE를 사용한 오버샘플링
- ENN을 사용한 언더샘플링
- 균형된 데이터셋 구성
- 장점 : 두 기술을 조합함으로써 클래스 불균형을 효과적으로 해결 가능
- 단점 : 모델 성능은 데이터셋의 특성와 문제에 따라 정보 손실이 발생할 수 있으며, 실험과 비교 분석이 필요
ML알고리즘 기반 방법론
- 모델 tuning 및 parameter 조정은 머신러닝 모델의 성능을 최적화하고 Class Imbalance 데이터에 대응하기 위한 중요한 전략 중 하나
- 모델 알고리즘 선택, 클래스 가중치 조정, 임계값 조정, 적절한 Metric 사용, Hyper parameter Tuninig, Validation, Ensenble
- Model Algorithm 선택
- Class Imbalance에 Sensitive한 모델 알고리즘을 선택
- Binary Classification 에서는 SVM, Random Forest, Gradient Boosting과 같은 모델이 좋은 성능을 보임
- Class Weight 조정
- 모델의 Loss Function에 class weight를 부여하여 imbalance class에 높은 가중치weight을 할당
- 모델은 imbalance dataset을 더 중요하게 취급하여 학습 진행
- Threshold 조정
- 모델의 예측 Threshold를 조정하여 Precision과 Recall을 조절 할 수 있음 적절한 Metric 사용
- Accruacy가 일반적으로 Imbalance Class에서 부적절하므로, 다른 Metric을 기반으로 모델을 최적화
- 적절한 Metric 사용
- Accruacy가 일반적으로 Imbalance Class에서 부적절하므로, 다른 Metric을 기반으로 모델을 최적화
- Hyper Parameter Tuning
- 모델의 Hyper Parameter를 조정하여 최적의 모델을 찾음
- Validation
- Cross Validation을 통해 모델의 일반화 능력을 평가하고, Class Imbalance에 대해서도 성능 신뢰성을 확인 필요
- Ensemble 활용
- 다양한 모델을 경합하는 앙상블 기법을 사용하여 Class Imbalance 문제를 다룸
Class Imbalance 성능 평가 및 선택
모델 성능을 어떻게 평가할 것인가?
성능 평가의 중요성
- 모델의 성능을 평가하는 것은 머신러닝 프로젝트에서 매우 중요한 부분
- 모델이 얼마나 잘 작동하고 예측을 얼마나 신뢰할 수 있는지를 판단
평가 Metric 선택
- 모델의 목적과 특성에 따라 다양한 성능 Metric을 선택할 수 있으며, 일반적으로 사용되는 Metric으로는 Accuracy, Precision, Recall, F1Score등이 있다.
예시
- 의료 진단 모델 : 의료 분야에서는 Precision이 매우 중요하며, Recall도 중요한 경우가 많음. 특히 의료 진단 모델은 Class Imbalance가 심하므로 주의해야함
- 스팸 메일 필터링 : Precision와 Recall을 균형있게 유지하는 것이 중요하므로, F1 Score를 평가에 사용할 수 있음
- Class Imbalance 모델 비교 : ROC Curve 혹은 AUC를 활용하여 모델 전반적인 성능을 비교
Class Imbalance와 MLOps
MLOps에 Class Imbalance 통합
통합이 필요한 이유
- Class Imbalance는 모델의 정확도 및 신뢰성에 영향을 미침
- 실제 운영 환경에서 모델의 성능을 보장하는 것이 중요하기 때문에, 이에 영향을 미치는 Class Imbalance 관리 필요
통합 방법
- 데이터 수집 및 전처리 단계 : Class Imbalance를 고려하여 데이터 수집 및 전처리 과정에서 적절한 Resampling 기법을 적용
- 모델 훈련 단계 : 모델 훈련 과정에서 가중치 조정 및 성능 지표 설정을 통해 Class Imbalance를 고려
- 평가 및 모니터링 : 모델의 실시간 평가 및 모니터링에서 모델이 불균형한 Input에도 정상적으로 동작하는지 확인 필요
Model Update에서의 Class Imbalance 관리
- 모델의 시간적 변화 : 실제 환경에서 데이터 및 클래스 분포가 시간이 지남에 따라 변함. 이로 인해 새롭게 발생하는 Class Imbalance 문제가 발생할 수 있으므로, 모델을 update하고 재학습해야함.
- 모델 Update와 Re-training 전략 : 정기적인 모델 update 및 실시간 데이터 스트림에서 모델을 re training fine tuining 하는 방법을 고려해야 함
- Data Drift 및 Class Imbalance : 데이터 분포의 변경Data Drift는 Class Imbalance와 관련성이 있을 수 있으므로 고려 필요
- 모델 버전 관리 : 모델 성능 개선과 비교를 위해 필요
- 모델 성능 모니터링 : Class Imbalance가 성능에 어떻게 영향을 미치지는 추적 모니터링
- 자동화된 Update 및 Re-Training : MLOps에 자동화된 프로세스를 도입하여, Class Imbalance 관련 문제가 감지되면 모델의 자동 update 및 re training을 수행하는 방법을 개발 적용

이기적이타주의자