TF-IDF와 딥러닝을 사용해 사용자가 입력한 글의 카테고리를 구분하는 프로그램 만들기.
일단 TF-IDF와 scikit-learn을 사용해 장르를 구분하는 프로그램을 만들고 scikit-learn으로 작성한 프로그램을 딥러닝 프로그램으로 변환해 보겠습니다.
뉴스 기사 자동 분류
인터넷에는 매일 대량의 텍스트가 올라옵니다. 메시지가 너무 많다 보니 어떤 주제를 이야기하는지 하 하나 확인하기 굉장히 힘듭니다. 자동으로 텍스트를 분류하고 관심 있는 아의 이야기만 읽을 수 있 다면 편리하지 않을까요? 이번 절에서는 대량의 뉴스 기사를 자동으로 분류해 봅니다. 대량의 뉴스 기 사와 그것이 어떤 카테고리인지의 정보를 학습 데이터로 사용합니다.
TF-IDF
4장에서 BoW(Bag-of-words)' 방법을 사용해 문장을 벡터 데이터로 변환했습니다. 이는 문장에 어 떤 단어가 어떤 빈도로 사용되는지를 확인하는 방법이었습니다. TF-IDF'도 기본적으로는 BoW와 마 찬가지로 문장을 수치로 변환합니다. 다만 단어의 출현 빈도와 함께 문장 전체에서 단어가 어느 정도의 중요도를 갖는지를 고려합니다.
'TF-IDF'는 문서 내부의 특정 단어가 어느 정도의 빈도로 사용되는지 확인해 문서 내부에서 중요하다 고 판단되는 특징적인 단어를 찾습니다.
예를 들어 여러 문서에 흔히 존재하는 단어(예를 들어 이다, 하다' 등)는 중요도를 낮추고 특정 카테고 리에만 존재하는 단어(예를 들어 주식, '주가' 등)는 중요도를 높여서 계산합니다. 즉 단순하게 단어의 출현 횟수를 세는 게 아니라 출현 빈도가 높은 단어는 낮은 중요도, 특징적인 단어는 높은 중요도를 부 여해 단어를 벡터로 만드는 것입니다.
다음 계산식은 TF-IDF가 각 단어의 값을 어떻게 계산하는지 보여줍니다. 다음 식에서 (t, d)는 문서 내부의 단어 출현 빈도를 나타내며 idf(t)는 모든 문서 내부의 단어 출현 빈도를 나타냅니다.
여기서 idf(t)는 다음과 같이 계산합니다. df(d, t)는 단어 t를 포함한 문서의 수이며 분자에 있는 D는 문서의 총 수를 나타냅니다.
공식이 조금 어려워 보일지도 모르겠습니다. 그냥 간단하게 문서 내부의 단어 출현 빈도와 그 단어의 중요도를 곱하는 공식이라고 생각하면 됩니다. TF-IDF를 사용하면 단순하게 단어의 수를 세는 것보다 벡터로 변환할 때의 정밀도를 높일 수 있습니다.
TF-IDF 모듈 만들기
그럼 텍스트를 학습시켜 봅시다. TF-IDF를 실행할 때는 scikit-leam의 'TfidfVectorizer'을 사용하는 것이 일반적입니다. 하지만 한국어 등의 아시아 문자에는 적용하기가 어렵습니다.
TP-IDF를 구현하는 것은 그렇게 어려운 일이 아닙니다. 업무에서 TF-IDF를 사용하고 싶은데 데이터 가 많다면 데이터베이스와의 연계도 고려해야 합니다. 이번 절에서는 TF-IDF를 직접 구현해 보겠습 니다. 다음은 TF-IDF 모듈을 구현한 예입니다.
from konlpy.tag import Okt
import pickle
import numpy as np
# KoNLPy의 Okt 객체 초기화
okt = Okt()
# 전역 변수
word_dic = {'_id': 0} # 단어 사전
dt_dic = {} # 문서 전체에서의 단어 출현 횟수
files = [] # 문서들을 저장할 리스트
def tokenize(text):
'''KoNLPy로 형태소 분석하기'''
result = []
word_s = okt.pos(text, norm=True, stem=True)
for n, h in word_s:
if not (h in ['Noun', 'Verb', 'Adjective']): continue
if h == 'Punctuation' and h2 == 'Number': continue
result.append(n)
return result
def words_to_ids(words, auto_add = True):
'''단어를 ID로 변환하기'''
result = []
for w in words:
if w in word_dic:
result.append(word_dic[w])
continue
elif auto_add:
id = word_dic[w] = word_dic['_id']
word_dic['_id'] += 1
result.append(id)
return result
def add_text(text):
'''텍스트를 ID 리스트로 변환해서 추가하기 '''
ids = words_to_ids(tokenize(text))
files.append(ids)
def add_file(path):
'''텍스트 파일을 학습 전용으로 추가하기 '''
with open(path, "r", encoding='utf-8') as f:
s = f.read()
add_text(s)
def calc_files():
'''추가한 파일 계산하기'''
global dt_dic
result = []
doc_count = len(files)
dt_dic = {}
# 단어 출현 횟수 세기
for words in files:
used_word = {}
data = np.zeros(word_dic['_id'])
for id in words:
data[id] += 1
used_word[id] = 1
# 단어 t가 사용되고 있을 경우 dt_dic의 수를 1 더하기
for id in used_word:
if not(id in dt_dic): dt_dic[id] = 0
dt_dic[id] += 1
# 정규화하기
data = data / len(words)
result.append(data)
# TF-IDF 계산하기
for i, doc in enumerate(result):
for id, v in enumerate(doc):
idf = np.log(doc_count / dt_dic[id]) + 1
doc[id] = min([doc[id] * idf, 1.0])
result[i] = doc
return result
def save_dic(fname):
''' 사전을 파일로 저장하기 '''
pickle.dump(
[word_dic, dt_dic, files],
open(fname, "wb")
)
def load_dic(fname):
''' 사전 파일 읽어 들이기 '''
global word_dic, dt_dic, files
n = pickle.load(open(fname, "rb"))
word_dic, dt_dic, files = n
def calc_text(text):
''' 문장을 벡터로 변환하기 '''
data = np.zeros(word_dic['_id'])
words = words_to_ids(tokenize(text), False)
for w in words:
data[w] += 1
data = data / len(words)
for id, v in enumerate(data):
idf = np.log(len(files) / dt_dic[id]) + 1
data[id] = min([data[id] * idf, 1.0])
return data
# 모듈 테스트하기
if __name__ == '__main__':
add_text('비')
add_text('오늘은 비가 내렸어요.')
add_text('오늘은 더웠지만 오후부터 비가 내렸다.')
add_text('비가 내리는 일요일이다.')
print(calc_files())
print(word_dic)Python으로 모듈을 만드는 방법은 굉장히 간단합니다. 파일 내부에 함수를 정의하기만 하면 됩니다. 다만 Jupyter Notebook에서 모듈을 사용하려면 모듈을 만든 후에 노트를 다시 열거나 커널을 다시 실행해야 합니다.
모듈로 사용할 경우 변수 __name__ 에 모듈 이름이 들어갑니다. 반대로 메인 파일로 실행하는 경우, 변수 __name__에 '__main__' 이라는 문자열이 들어갑니다. 이러한 성질을 이용해 모듈 테스트를 만들 수 있습니다.
실행을 해보면

이렇게 출력이 됩니다.
각 배열이 문장 하나를 나타내며, 각 배열의 요소는 각 단어의 출현 빈도와 중요도를 곱한 값입니다. 마지막에는 단어 사전과 단어 ID를 출력하게 했습니다.
이때 Python의 딕셔너리 자료형은 순서를 고려하지 않으므로 순서가 제멋대로 출력됐습니다.
텍스트 분류하기
텍스트 분류 과정은 다음과 같습니다.
1. 텍스트에서 불필요한 품사를 제거한다.
2. 사전을 기반으로 단어를 숫자로 변환한다.
3. 파일 내부의 단어 출현 비율을 계산한다.
4. 데이터를 학습시킨다.
이러한 과정으로 텍스트를 분류하는데, 신문 저작권의 문제로 이 과정을 마친 파일을 책과 함께 제공 하는 예제 파일에 넣었습니다. 기사로 수집하고 이전에 만든 tiadf 모듈로 기사를 읽어 변환하기만 하면 됩니다.
수집한 기사는 네이버 뉴스에 있는 정치, 경제, 생활, IT/과학 기사입니다. 네이버 뉴스에는 사회/세계 카테고리도 있지만, 해당 카테고리는 정치/경제 기사와 유사도가 굉장히 높을 것이라 예상돼 제외했습 니다.
구현을 위해 3일 동안의 기사 2400개를 수집했습니다(많은 양은 아닙니다). 현재 공교롭게도 3일 동안 애플의 주가 폭락으로 세계 경제가 큰 영향을 받고 있는 시기입니다. 전반적으로 '애플'이라는 글자가 들어가면 IT/과학 기사일 가능성이 높겠지만, 데이터를 수집한 기간에는 '애플'이라는 글자가 들어가면 경제 기사일 가능성이 높을 수 있습니다. 이러한 현상을 막으려면 장기간 동안 수집한 데이터를 사용하 는 게 좋습니다.
또한 네이버 뉴스는 여러 신문사의 뉴스를 수집해서 보여주므로 신문사별로 카테고리 구분 기준이 달 라 문제가 생길 수도 있습니다. 따라서 90% 정도의 구분 정답률이 나오면 어느 정도 잘 활용할 수 있는 수준이라고 볼 수 있습니다. 실제로 이번 절의 예제도 90% 정도의 정답률이 나오지만, 기사를 직접 입 력해서 카테고리를 구분해 보면 "잘 맞는다"라는 느낌을 받을 수 있습니다.
이 과정에서 사용한 프로그램은 다음과 같습니다.
import os, glob, pickle
import tfidf
# 변수 초기화
y = []
x = []
# 디렉터리 내부의 파일 목록 전체에 대해 처리하기 --- (*1)
def read_files(path, label):
print("read_files=", path)
files = glob.glob(path + "/*.txt")
for f in files:
if os.path.basename(f) == 'LICENSE.txt': continue
tfidf.add_file(f)
y.append(label)
# 기사를 넣은 디렉터리 읽어 들이기 --- ( ※ 2)
read_files('text/100', 0)
read_files('text/101', 1)
read_files('text/103', 2)
read_files('text/105', 3)
# TF-IDF 벡터로 변환하기 --- (*3)
x = tfidf.calc_files()
# 저장하기 --- (*4)
pickle.dump([y, x], open('text/genre.pickle', 'wb'))
tfidf.save_dic('text/genre-tdidf.dic')
print('ok')이를 실행하면 문장의 형태소들이 벡터로 만들어집니다.
프로그램을 자세하게 확인해 봅시다. 프로그램의 (1)에서는 디렉터리 내부의 파일 목록을 TF-IDF모듈에 추가하는 처리를 합니다. glob 모듈을 사용하면 파일 목록을 얻고 tfidf.add_file() 함수에 경로를 전달합니다. (2) 에서는 어떤 폴더를 읽어 들일지 지정합니다. (3)에서는 실제로 문장을 TF-IDF 벡터로 변환합니다. 최종적으로 (4)에서 genre.pickle이라는 이름으로 데이터를 저장합니다.
TF-IDF를 나이브 베이즈로 학습시키기
지금까지의 과정으로 TF-IDF 데이터베이스가 만들어졌습니다.
그럼 일단 나이브 베이즈를 사용해 데이터를 학습시켜 봅시다.
import pickle
from sklearn.naive_bayes import GaussianNB
from sklearn.model_selection import train_test_split
import sklearn.metrics as metrics
import numpy as np
# TF-IDF 데이터베이스 읽어 들이기 --- (*1)
data = pickle.load(open("text/genre.pickle", "rb"))
y = data[0] # 레이블
x = data[1] # TF-IDF
# 학습 전용과 테스트 전용으로 구분하기 --- (*2)
x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size=0.2)
# 나이브 베이즈로 학습하기 --- (*3)
model = GaussianNB()
model.fit(x_train, y_train)
# 평가하고 결과 출력하기 --- (*4)
y_pred = model.predict(x_test)
acc = metrics.accuracy_score(y_test, y_pred)
rep = metrics.classification_report(y_test, y_pred)
print("정답률=", acc)
print(rep)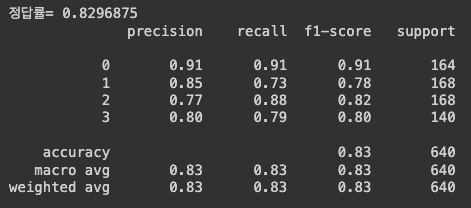
0.83 정도의 정답률이 나온다.
딥러닝으로 정답률 개선하기
scikit-learn 에서 딥러닝으로 변경하기
scikit-learn으로 만든 머신러닝을 Tensorflow + Keras 학습으로 변경해 봅시다.
변경하는 작업은 그렇게 어렵지 않지만, 몇 가지 주의할 점이 있습니다.
1. 레이블 데이터를 one-hot 형식으로 변환하고
2. 입력과 출력 벡터 크기를 확실하게 확인해서 지정해야 합니다.
두 가지만 확실하게 짚고 넘어가면 모델을 정의해 사용하기만 하면 됩니다.
import pickle
from sklearn.model_selection import train_test_split
import sklearn.metrics as metrics
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import RMSprop
import matplotlib.pyplot as plt
import numpy as np
import h5py
# 분류할 레이블 수 --- (*1)
nb_classes = 4
# 데이터베이스 읽어 들이기 --- (*2)
data = pickle.load(open("text/genre.pickle", "rb"))
y = data[0] # 레이블
x = data[1] # TF-IDF
# 레이블 데이터를 One-hot 형식으로 변환하기 --- (*3)
y = keras.utils.np_utils.to_categorical(y, nb_classes)
in_size = x[0].shape[0]
# 학습 전용과 테스트 전용으로 구분하기 --- (*4)
x_train, x_test, y_train, y_test = train_test_split(
np.array(x), np.array(y), test_size=0.2)
# MLP모델의 구조 정의하기 --- (*5)
model = Sequential()
model.add(Dense(512, activation='relu', input_shape=(in_size,)))
model.add(Dropout(0.2))
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(nb_classes, activation='softmax'))
# 모델 컴파일하기 --- (*6)
model.compile(
loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])
# 학습 실행하기 --- (*7)
hist = model.fit(x_train, y_train,
batch_size=128,
epochs=20,
verbose=1,
validation_data=(x_test, y_test))
# 평가하기 ---(*8)
score = model.evaluate(x_test, y_test, verbose=1)
print("정답률=", score[1], 'loss=', score[0])
# 가중치데이터 저장하기 --- (*9)
model.save_weights('./text/genre-model.hdf5')
# 학습 상태를 그래프로 그리기 --- (*10)
plt.plot(hist.history['acc'])
plt.plot(hist.history['val_acc'])
plt.title('Accuracy')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
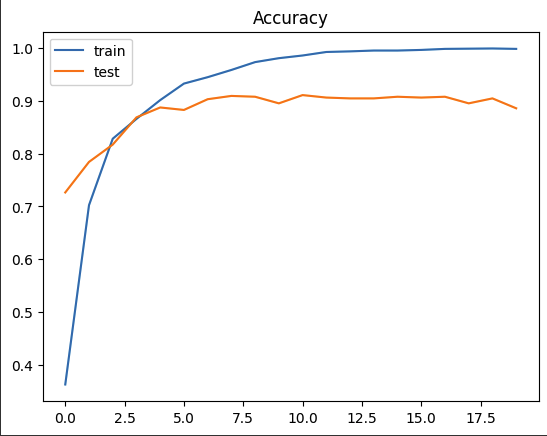
0.88의 정답률을 보인다.
직접 문장을 지정해 판정하기
그럼 직접 문장을 지정해 지금까지의 성과를 확인해 봅시다.
1. 대통령이 북한과 관련된 이야기로 한미 정상회담을 준비하고 있습니다.
2. iPhone과 iPad를 모두 가지고 다니므로 USB를 2개 연결할 수 있는 휴대용 배터리를 선호합니다.
3. 이번 주에는 미세먼지가 많을 것으로 예상되므로 노약자는 외출을 자제하는 것이 좋습니다.
다음은 이전에 학습한 딥러닝 MLP 가중치 데이터를 사용해 텍스트를 판정하는 프로그램입니다.
import pickle, tfidf
import numpy as np
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import RMSprop
from keras.models import model_from_json
# 텍스트 준비하기 --- ( ※ 1)
text1 = """
대통령이 북한과 관련된 이야기로 한미 정상회담을 준비하고 있습니다.
"""
text2 = """
iPhone과 iPad를 모두 가지고 다니므로 USB를 2개 연결할 수 있는 휴대용 배터리를 선호합니다.
"""
text3 = """
이번 주에는 미세먼지가 많을 것으로 예상되므로 노약자는 외출을 자제하는 것이 좋습니다.
"""
# TF-IDF 사전 읽어 들이기 --- (*2)
tfidf.load_dic("text/genre-tdidf.dic")
# Keras 모델 정의하고 가중치 데이터 읽어 들이기 --- (*3)
nb_classes = 4
model = Sequential()
model.add(Dense(512, activation='relu', input_shape=(52800,)))
model.add(Dropout(0.2))
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(nb_classes, activation='softmax'))
model.compile(
loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])
model.load_weights('./text/genre-model.hdf5')
# 텍스트 지정해서 판별하기 --- (*4)
def check_genre(text):
# 레이블 정의하기
LABELS = ["정치", "경제", "생활 ", "IT/과학"]
# TF-IDF 벡터로 변환하기 -- (*5)
data = tfidf.calc_text(text)
# MLP로 예측하기 --- (*6)
pre = model.predict(np.array([data]))[0]
n = pre.argmax()
print(LABELS[n], "(", pre[n], ")")
return LABELS[n], float(pre[n]), int(n)
if __name__ == '__main__':
check_genre(text1)
check_genre(text2)
check_genre(text3)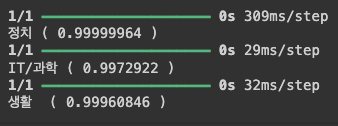
개선힌트
my_text.py에 직접 글을 작성해서 실행했을 때 원하는 결과가 나오지 않는 경우도 있을 것 입니다.
왜 그럴까요? TF-IDF는 학습한 데이터만 벡터로 만듭니다. 현재 예제에서는 미지의 단어가 들어올 경우 이를 무시하고 처리해버립니다. 따라서 학습하지 않은 데이터가 많이 나오면 판정을 아예 못하는 경우가 발생합니다. 따라서 실제 업무에서 활용할 경우 미지의 단어가 나오면 이를 다시 학습시키는 등의 방법을 사용해야 합니다.
