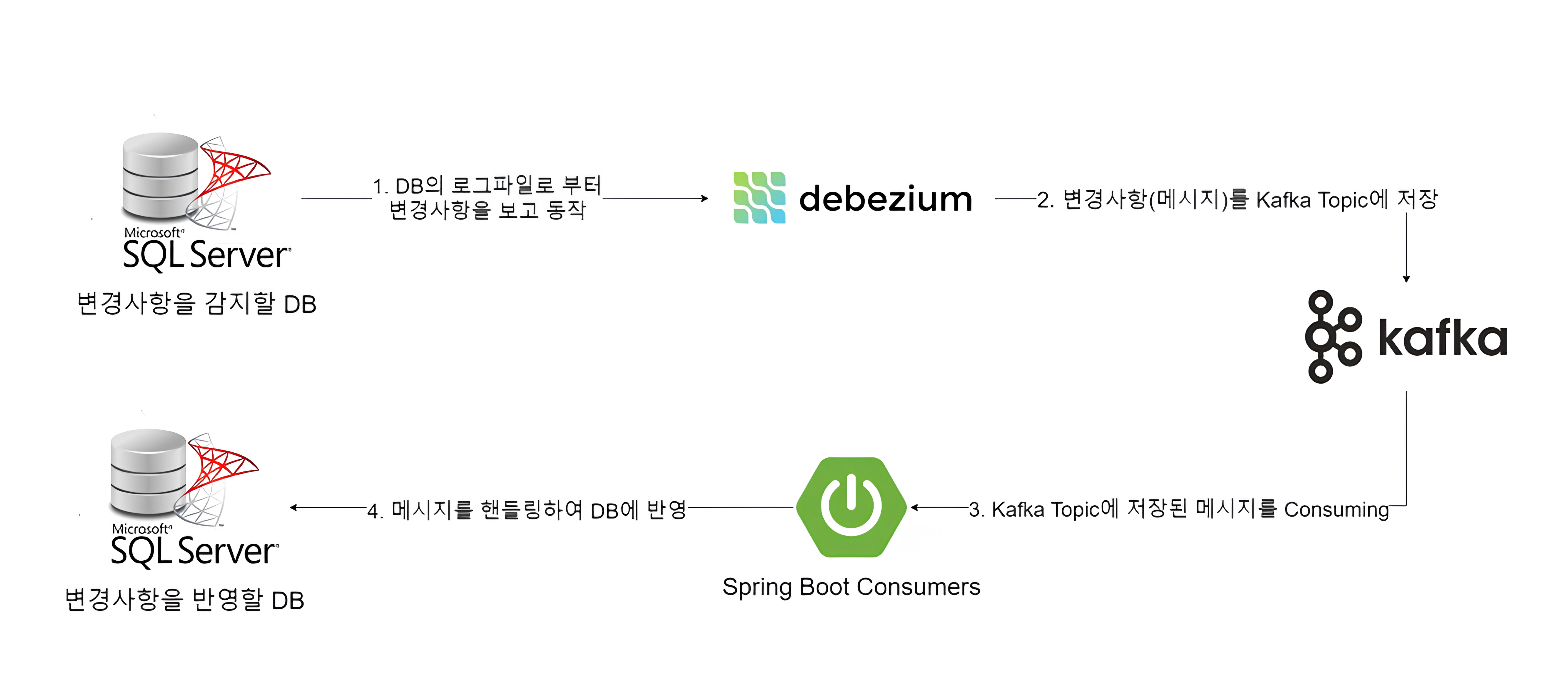
이전 포스팅에서는 개념적인 설명을 했습니다. 이번 포스팅에서는 Kafka CDC를 통해서 어떻게 ETL서비스를 구현했는지 코드상으로 보여드리면서 설명하겠습니다.
Window 환경에서 서비스들을 실행시켜야해서 처음에는 Kafka 서비스들을 실행시키기위한 파일을 다운로드받고 bat파일을 실행시키는 식으로 구성하려고 했습니다. 하지만 Kafka 공식 사이트에서 받은 파일인데도 bat파일에 경로 실수가 있다던지... 다시실행 시킬 때 log파일을 핸들링 하는 과정에서 에러가 발생한다던지... window 환경에서 Kafka를 돌리기에는 안정성이 떨어진다 판단이 되었습니다.
그래서 Docker Desktop을 사용해서 리눅스환경에서 컨테이너를 실행시키는 식으로 개발을 진행하였습니다. 포스팅을 보며 리눅스 서버에서 Kafka를 실행하려는 분들도 쉽게 따라하실 수 있을 겁니다.
📌 Single Broker 형태로 Kafka 서비스들 실행
Kafka를 실행할 때 클러스터안에 여러 Broker를 두어 하나의 Broker가 문제가 생기더라도 다른 Broker가 실행되는 식으로 서비스를 띄워 고가용성과 확장성의 이점을 가질 수 있습니다.
하지만 현재는 Single Broker 형태로 서비스를 실행시켰는데 아직 개발, 테스트 단계이기고 모니터링 시스템도 구축하여 성능체크를 추후에 멀티 Broker 형태로 수정하기로 했습니다.
1. docker-compose.yml 설정 파일 작성하기
- docker-compose.yml
version: '3'
services:
zookeeper:
container_name: zookeeper
image: confluentinc/cp-zookeeper:7.5.4
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
ports:
- "2181:2181"
volumes:
- C:\kafka\zookeeper\data:/var/lib/zookeeper/data
- C:\kafka\zookeeper\log:/var/lib/zookeeper/log
kafka:
container_name: kafka
image: confluentinc/cp-kafka:7.5.4
depends_on:
- zookeeper
ports:
- "29092:29092"
- "9092:9092"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092,PLAINTEXT_HOST://localhost:29092 # 외부에서 접속시 localhost 대신 자신의 ip 주소를 넣어야함
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
volumes:
- C:\kafka\kafka\data:/var/lib/kafka/data
connect:
image: quay.io/debezium/connect:2.4
container_name: connect
ports:
- "8083:8083"
environment:
GROUP_ID: "1"
CONFIG_STORAGE_TOPIC: "my_connect_configs"
OFFSET_STORAGE_TOPIC: "my_connect_offsets"
STATUS_STORAGE_TOPIC: "my_connect_statuses"
ZOOKEEPER_CONNECT: 'zookeeper:2181'
BOOTSTRAP_SERVERS: 'kafka:9092'
depends_on:
- zookeeper
- kafka
links:
- zookeeper
- kafka
kafka-ui:
image: provectuslabs/kafka-ui:v0.7.2
container_name: kafka-ui
depends_on:
- kafka
ports:
- "8090:8080"
environment:
KAFKA_CLUSTERS_0_NAME: Single Cluster
KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafka:9092
KAFKA_CLUSTERS_0_ZOOKEEPER: zookeeper:2181zookeeper 서비스
- zookeeper: 서비스의 이름입니다. 각 서비스는 고유한 이름을 가져야 합니다.
- container_name: 컨테이너의 이름을 지정합니다.
- image: 사용할 Docker 이미지를 지정합니다. 여기서는 Confluent의 Zookeeper 이미지 버전 7.5.4를 사용합니다.
- environment: 컨테이너에서 사용할 환경 변수를 설정합니다.
- ZOOKEEPER_CLIENT_PORT: Zookeeper 클라이언트가 접속할 포트 번호입니다.
- ZOOKEEPER_TICK_TIME: Zookeeper의 기본 시간 단위(tick)입니다.
- ports: 호스트와 컨테이너 간의 포트 매핑을 정의합니다. 2181:2181은 호스트의 2181 포트를 컨테이너의 2181 포트로 매핑합니다.
- volumes: 호스트와 컨테이너 간의 디렉토리 매핑을 정의합니다. 호스트의C:\kafka\zookeeper\data 디렉토리를 컨테이너의 /var/lib/zookeeper/data 디렉토리로 매핑합니다.
kafka 서비스
- depends_on: kafka 서비스는 zookeeper 서비스가 먼저 실행되어야 시작됩니다.
- KAFKA_BROKER_ID: Kafka 브로커의 ID입니다.
- KAFKA_ZOOKEEPER_CONNECT: Zookeeper의 주소입니다.
- KAFKA_ADVERTISED_LISTENERS: Kafka 브로커가 외부에 광고하는 리스너 목록입니다. 로컬과 외부 접근을 위해 두 개의 리스너가 정의되어 있습니다.
- KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: 리스너에 대한 보안 프로토콜 매핑입니다.
- KAFKA_INTER_BROKER_LISTENER_NAME: 브로커 간 통신에 사용할 리스너 이름입니다.
- KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 오프셋 토픽의 복제 인자입니다.
connect 서비스
- image: confluent에서 제공해주는 connect 이미지도 있지만 debezium-connect를 사용하기위한 라이브러리를 추가로 등록해주어야해서 debezium에서 제공하는 이미지를 사용하였습니다.
- GROUP_ID: Kafka Connect 그룹 ID입니다.
- CONFIG_STORAGE_TOPIC: Kafka Connect의 설정을 저장할 토픽입니다.
- OFFSET_STORAGE_TOPIC: 오프셋 정보를 저장할 토픽입니다.
- STATUS_STORAGE_TOPIC: 상태 정보를 저장할 토픽입니다.
- ZOOKEEPER_CONNECT: Zookeeper의 주소입니다.
- BOOTSTRAP_SERVERS: Kafka 브로커의 주소입니다.
kafka-ui 서비스
- image: Kafka UI 이미지 버전 0.7.2를 사용합니다.
- KAFKA_CLUSTERS_0_NAME: Kafka 클러스터의 이름입니다.
- KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: Kafka 브로커의 주소입니다.
- KAFKA_CLUSTERS_0_ZOOKEEPER: Zookeeper의 주소입니다.
2. docker-compose 실행하기
- docker-compose명령어
docker-compose -f docker-compose.yml up -d-f <설정파일> : 작성한 설정으로 docker-compose를 실행한다.
up : docker-compose 를 실행한다.
-d detach 모드로 컨테이너를 백그라운드로 실행하게 해준다.
📌 Microsoft SQL Server 설정
Debezium connector를 사용하여 CDC를 사용하기 위해서는 CDC관련 설정을 활성화 해주어야합니다. 진행 중인 프로젝트에서 Microsoft SQL Server 라는 관계형 데이터베이스를 사용하여 이에 대 설명을 하였습니다.
Debezium connector 공식문서 사이트에 들어가시면 DB의 종류에 따라 필요한 설정이 자세하게 알려주고 있어 공식문서를 보면 다른 DB더라도 쉽게 CDC 관련 설정을 할 수 있을겁니다.
1. 변경사항을 감지할 MsSql 데이터 베이스 및 테이블 생성
- 변경사항을 감지할 데이터베이스와 변경사항을 반영할 데이터 베이스 생성
-- 변경사항을 감지할 데이터베이스
CREATE DATABASE cdc_target_db;
-- 변경사항을 반영할 데이터 베이스
CREATE DATABASE cdc_reflect_db;- 테이블 생성
CREATE TABLE sample_header (
id INT IDENTITY(1,1) PRIMARY KEY,
code NVARCHAR(255),
name NVARCHAR(255)
);2. MsSql CDC 활성화
변경사항을 감지할 데이터베이스만 CDC 활성화를 해주면 됩니다.
- 데이터베이스 CDC 활성화
USE cdc_target_db-- 변경사항을 감지할 데이터베이스
GO
EXEC sys.sp_cdc_enable_db
GO- 캡쳐 인스턴스 생성(데이터 베이스 CDC활성화)
EXEC sys.sp_cdc_enable_table
@source_schema = N'dbo',
@source_name = N'sample_header', -- 테이블명
@role_name = N'sysadmindb_owner@role_nameNULLsysadmindb_owner',
@filegroup_name = N'PRIMARY',
@supports_net_changes = 0
GO📌 Debezium-connector 생성
connector를 생성할 때 REST API를 통해 Connector를 생성할 수 있습니다. 그래서 평소에 자주 쓰던 Postman을 사용하여 debezium-connector를 생성하였습니다.
- conector 생성 요청
8083 포트는 connect서비스의 포트번호 입니다.
POST http://localhost:8083/connectors
{
"name": "debezium-connector",
"config": {
"connector.class": "io.debezium.connector.sqlserver.SqlServerConnector",
"database.hostname": "서버의 ip주소",
"database.connectionTimeZone": "Asia/Seoul",
"database.port": "1433",
"database.user": "yourusername",
"database.password": "yourpassword",
"database.names": "cdc_target_db",
"topic.prefix": "topic_",
"table.include.list": "dbo.sample_header",
"schema.history.internal.kafka.bootstrap.servers": "kafka:9092",
"schema.history.internal.kafka.topic": "schema_history_topic",
"database.encrypt" : false,
"transforms":"unwrap",
"transforms.unwrap.type":"io.debezium.transforms.ExtractNewRecordState",
"transforms.unwrap.drop.tombstones":false,
"transforms.unwrap.add.fields.prefix":"cdc_meta_",
"transforms.unwrap.add.fields":"op,table,lsn,source.ts_ms",
"transforms.unwrap.delete.handling.mode":"rewrite",
"key.converter":"org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable":false,
"value.converter":"org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable":false
}
}
- connector.class: 사용될 커넥터 클래스입니다. 여기서는 Debezium의 SQL Server 커넥터인 io.debezium.connector.sqlserver.SqlServerConnector를 사용합니다.
- database.hostname: 데이터베이스 서버의 IP 주소입니다.
- database.connectionTimeZone: 데이터베이스와의 연결에 사용할 시간대입니다. 이 예에서는 Asia/Seoul로 설정되어 있습니다.
- database.port: 데이터베이스 서버의 포트 번호입니다. SQL Server의 기본 포트는 1433입니다.
- database.user: 데이터베이스에 접속할 사용자 이름입니다.
- database.password: 데이터베이스에 접속할 사용자의 비밀번호입니다.
- database.names: 캡처할 데이터베이스 이름입니다. 이 예에서는 cdc_target_db입니다.
- topic.prefix: Kafka 토픽의 접두사입니다. Debezium은 이 접두사를 사용하여 변경 데이터를 Kafka 토픽에 게시합니다.
- table.include.list: 캡처할 테이블의 목록입니다. 이 예에서는 dbo.sample_header 테이블을 캡처합니다.
- schema.history.internal.kafka.bootstrap.servers: 스키마 변경 이력을 저장할 Kafka 클러스터의 주소입니다. 여기서는 kafka:9092로 설정되어 있습니다.
- schema.history.internal.kafka.topic: 스키마 변경 이력을 저장할 Kafka 토픽입니다. 이 예에서는 schema_history_topic입니다.
- database.encrypt: 데이터베이스 연결이 암호화되어 있는지 여부를 설정합니다. 여기서는 false로 설정되어 있습니다.
- transforms: 변환을 지정합니다. 여기서는 unwrap 변환을 사용합니다.
- transforms.unwrap.type: unwrap 변환의 클래스입니다. 여기서는 io.debezium.transforms.ExtractNewRecordState를 사용합니다.
- transforms.unwrap.drop.tombstones: 삭제된 레코드를 제거할지 여부를 설정합니다. 여기서는 false로 설정되어 있습니다.
- transforms.unwrap.add.fields.prefix: 추가 필드의 접두사입니다. 여기서는 cdcmeta로 설정되어 있습니다.
- transforms.unwrap.add.fields: 추가할 필드 목록입니다. 여기서는 op,table,lsn,source.ts_ms 필드를 추가합니다.
- transforms.unwrap.delete.handling.mode: 삭제된 레코드를 처리하는 방법을 설정합니다. 여기서는 rewrite로 설정되어 있습니다.
- key.converter: Kafka Connect가 키를 변환하는 데 사용할 변환기입니다. 여기서는 org.apache.kafka.connect.json.JsonConverter를 사용합니다.
- key.converter.schemas.enable: 키 변환 시 스키마를 포함할지 여부를 설정합니다. 여기서는 false로 설정되어 있습니다.
- value.converter: Kafka Connect가 값을 변환하는 데 사용할 변환기입니다. 여기서는 org.apache.kafka.connect.json.JsonConverter를 사용합니다.
- value.converter.schemas.enable: 값 변환 시 스키마를 포함할지 여부를 설정합니다. 여기서는 false로 설정되어 있습니다.
속성 값들에 대한 설명은 Dedezium connector 공식문서 사이트를 들어가시면 자세히 확인할 수 있습니다.
📌 Spring Boot 코드 구현
1. kafka 라이브러리 추가
- spring boot에서 kafka를 사용하기 위한 라이브러리
implementation 'org.springframework.kafka:spring-kafka'2. KafkaConsumerConfig 설정
로컬, 테스트, 개발 환경에따라 kafka가 실행되지 않을 수도 있어서 Spring의 @ConditionalOnProperty를 사용해서 쉽게 활성화/비활성화 할 수 있도록 하였습니다.
application.kafka-property.enabled 값을 true로 하면 spring boot에서 kafka와 연결을 하게되고 false 로 하면 연결하지 않게 됩니다.
- yml에 아래 내용추가
application:
kafka-property:
enabled: true
bootstrap-servers: 192.168.50.3:29092
group-id: consumerGroupId
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer- Kafka Topic의 레코드를 Consuming하기 위한 Config 설정
@Configuration
@RequiredArgsConstructor
public class KafkaConsumerConfig {
private final KafkaProperties kafkaProperties;
@Bean
@ConditionalOnProperty(value = "application.kafka-property.enabled", havingValue = "true")
public ConsumerFactory<String, String> consumerFactory() {
Map<String, Object> properties = Map.of(
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaProperties.getBootstrapServers(),
ConsumerConfig.GROUP_ID_CONFIG, kafkaProperties.getGroupId(),
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, kafkaProperties.getKeyDeserializer(),
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, kafkaProperties.getValueDeserializer()
);
return new DefaultKafkaConsumerFactory<>(properties);
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory(
ConsumerFactory<String, String> consumerFactory) {
ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory
= new ConcurrentKafkaListenerContainerFactory<>();
kafkaListenerContainerFactory.setConsumerFactory(consumerFactory);
return kafkaListenerContainerFactory;
}
@Getter
@Setter
@Configuration
@ConfigurationProperties(prefix = "application.kafka-property")
public static class KafkaProperties {
private boolean enabled;
private String bootstrapServers;
private String groupId;
private String keyDeserializer;
private String valueDeserializer;
}
}3. KafkaListener 코드
Topic에 담긴 레코드를 consuming하여 DB에 저장하기할 때 JPA를 사용하는데 이 때 사용될 Entity와 필요한 코드를 작업해줍니다.
Entity 작성
@Table(name = "SAMPLE_HEADER")
@Entity
@DynamicInsert
@DynamicUpdate
@Getter
@Builder
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@AllArgsConstructor(access = AccessLevel.PROTECTED)
public class SampleHeader {
@Id
private Long id;
@Column(nullable = false)
private String code;
private String name;
public SampleHeader setId(Long id) {
this.id = id;
return this;
}
public SampleHeader setCode(String code) {
this.code = code;
return this;
}
public SampleHeader setName(String name) {
this.name = name;
return this;
}
}프로젝트에 따라 필요없는 어노테이션은 생략하셔도 됩니다.
Repository단 작성
public interface SampleHeaderRepository extends JpaRepository<SampleHeader, Long> {
}Service단 작성
@Service
@Transactional
@RequiredArgsConstructor
public class SampleHeaderKafkaService {
private final SampleHeaderRepository sampleHeaderRepository;
public void create(SampleHeaderTopic param) {
var createTarget = param.toEntity();
sampleHeaderRepository.save(createTarget);
}
public void update(SampleHeaderTopic param) {
sampleHeaderRepository.findById(param.getId()).ifPresent(
sampleHeader ->
sampleHeader
.setName(param.getName())
.setCode(param.getCode()));
}
public void delete(SampleHeaderTopic param) {
sampleHeaderRepository.findById(param.getId())
.ifPresent(sampleHeaderRepository::delete);
}
}수정, 삭제시에 해당 레코드가 존재하지 않을 경우 예외를 던져야 재시도를 하는데 샘플 코드여서 DB데이터를 지웠다 다시 테스트하기도해서 예외를 던지지 않고 존재할 때만 로직을 수행하도록 개발 하였습니다.
DTO 작성
- Topic의 변경 옵션(생성, 수정, 삭제, 조회)을 Enum으로 작성
@Getter
public enum CdcMetaOperation {
CREATE("c", "생성"),
READ("r", "읽기"),
UPDATE("u", "수정"),
DELETE("d", "삭제"),
;
private final String code;
private final String topicCode;
private final String displayValue;
CdcMetaOperation(String topicCode, String displayValue) {
this.code = this.name();
this.topicCode = topicCode;
this.displayValue = displayValue;
}
public static CdcMetaOperation fromTopicCode(String topicCode) {
return Stream.of(values())
.filter(enumTopicCode -> topicCode.equalsIgnoreCase(enumTopicCode.topicCode))
.findFirst()
.orElseThrow(
() -> new IllegalArgumentException("No Enum specified for this code: " + topicCode));
}
}- Topic의 Meta 데이터를 받을 DTO작성
@Getter
@Setter
@NoArgsConstructor
public class CommonSyncTopic {
@JsonProperty("__deleted")
private Boolean __deleted;
private String cdcMetaOp;
private String cdcMetaTable;
private LocalDateTime cdcMetaSourceTsMs;
public Boolean IsDeleted() {
return __deleted;
}
public CdcMetaOperation getCdcMetaOperation() {
return CdcMetaOperation.fromTopicCode(cdcMetaOp);
}
public String getCdcMetaTable() {
return cdcMetaTable;
}
public LocalDateTime getCdcMetaSourceTsMs() {
return cdcMetaSourceTsMs;
}
}- Topic에 있다는 sample_header 테이블의 변경상항을 받을 DTO작성
@Getter
@Setter
@NoArgsConstructor
public class SampleHeaderTopic extends CommonSyncTopic {
private Long id;
private String code;
private String name;
public SampleHeader toEntity() {
return SampleHeader.builder()
.id(id)
.code(code)
.name(name)
.build();
}
}
KafkaListener 작성
@Slf4j
@Component
@RequiredArgsConstructor
public class SampleConsumer {
private final SampleHeaderKafkaService sampleHeaderKafkaService;
@KafkaListener(topics = "tapex_topic_.cdc_target_db.dbo.sample_header", autoStartup = "${application.kafka-property.enabled:false}")
public void sampleHeaderKafkaListener(ConsumerRecord<String, String> consumerRecord) {
String value = consumerRecord.value();
if (value == null) {
return;
}
try {
var sampleHeaderTopic = JacksonUtils.getTopicObjectMapper()
.readValue(value, new TypeReference<SampleHeaderTopic>() {
});
handleSampleHeaderTopic(sampleHeaderTopic);
} catch (JsonProcessingException ex) {
log.error("jsonProcessingException", ex);
}
}
private void handleSampleHeaderTopic(SampleHeaderTopic sampleHeaderTopic) {
switch (sampleHeaderTopic.getCdcMetaOperation()) {
case CREATE -> sampleHeaderKafkaService.create(sampleHeaderTopic);
case UPDATE -> sampleHeaderKafkaService.update(sampleHeaderTopic);
case DELETE -> sampleHeaderKafkaService.delete(sampleHeaderTopic);
}
}
}📌 CDC 동작 테스트
그럼 이제 cdc_target_db(변경사항을 감지할 데이터베이스) 에 데이터가 insert, update, delete 이벤트가 발생했을 때 토픽에 레코드가 생성되고 spring boot에서 consuming을 하면서 cdc_reflect_db(변경사항을 반영할 데이터베이스)에 잘 저장되는지 확인 해보겠습니다.
INSERT 동작 테스트
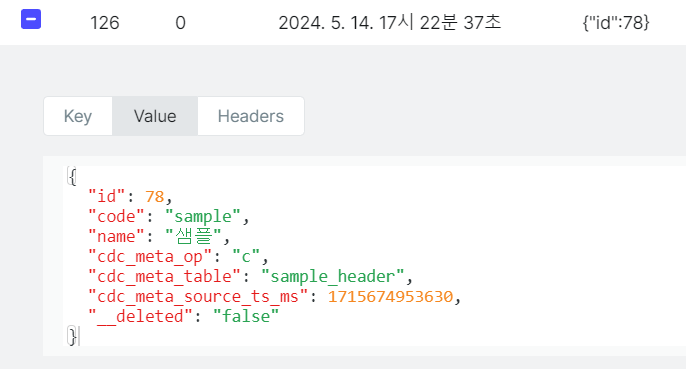
- cdc_target_db에 insert문 실행
insert into sample_header (code, name) values ('sample', '샘플');- spring boot 디버그 모드로 topic에서 consuming된 INSERT 데이터 확인
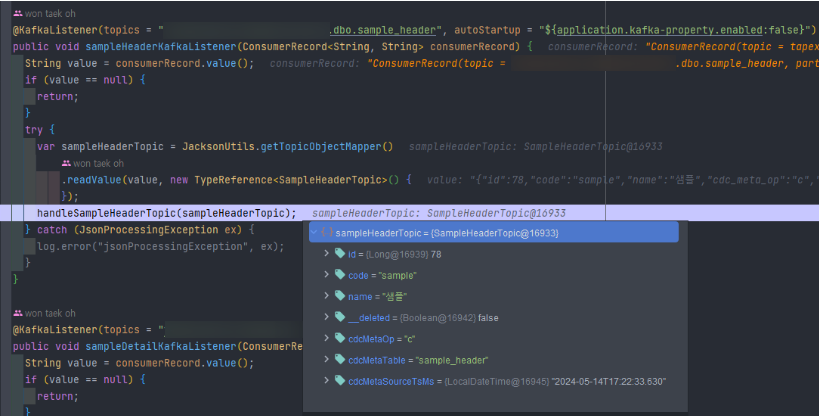
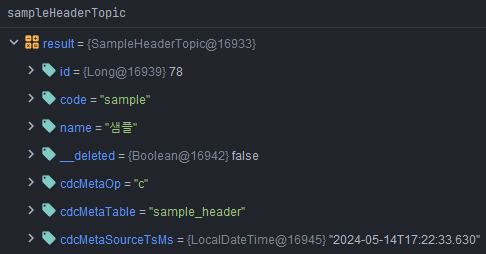
- insert문의 데이터들을 확인할 수 있습니다.
- insert 된 데이터 여서 cdcMetaOp 값이 c 인것을 확인할 수 있습니다.
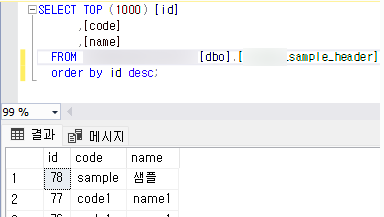
- cdc_reflect_db에 반영된 insert 데이터
UPDATE 동작 테스트
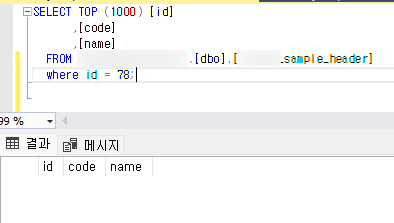
- cdc_target_db에 update문 실행
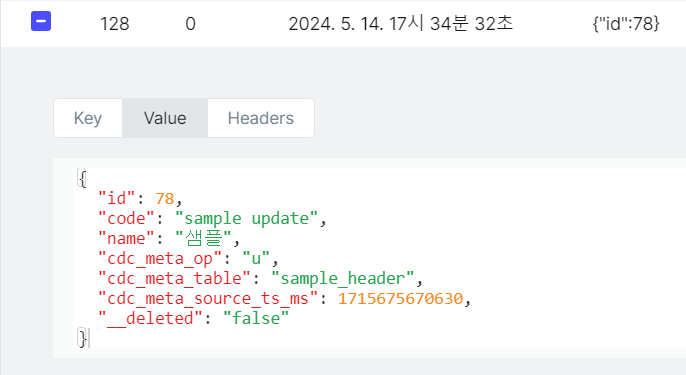
update sample_header set code = 'sample update' where id = 78;- spring boot 디버그 모드로 topic에서 consuming된 UPDATE 데이터 확인
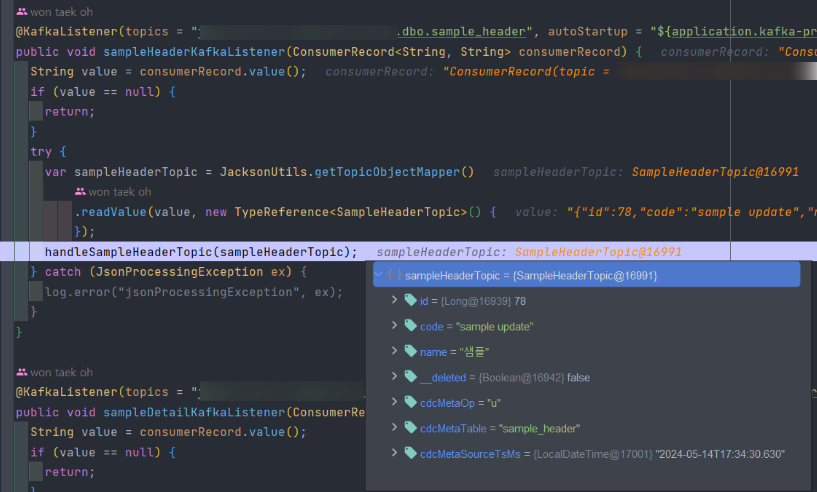
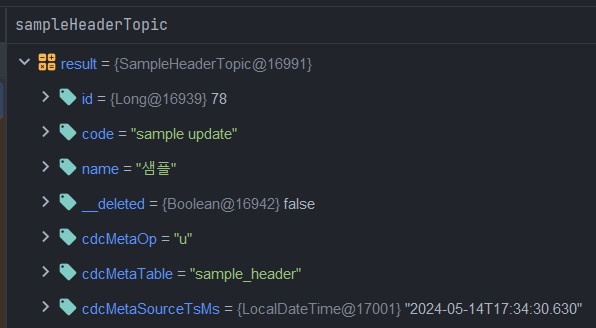
- update문의 데이터들을 확인할 수 있습니다.
- update 된 데이터이기 때문에 cdcMetaOp 값이 u 인것을 확인할 수 있습니다.
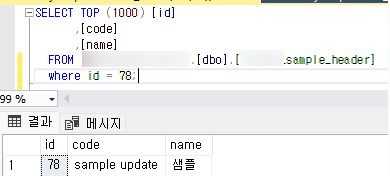
- cdc_reflect_db에 반영된 update된 데이터
DELETE 동작테트
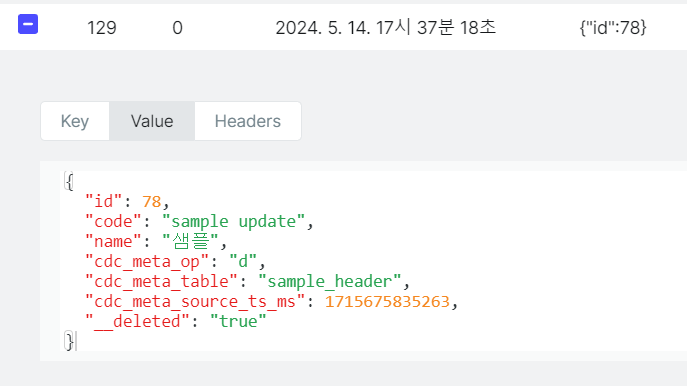
- cdc_target_db에 delete문 실행
delete from sample_header where id = 78- spring boot 디버그 모드로 topic에서 consuming된 delete 데이터 확인
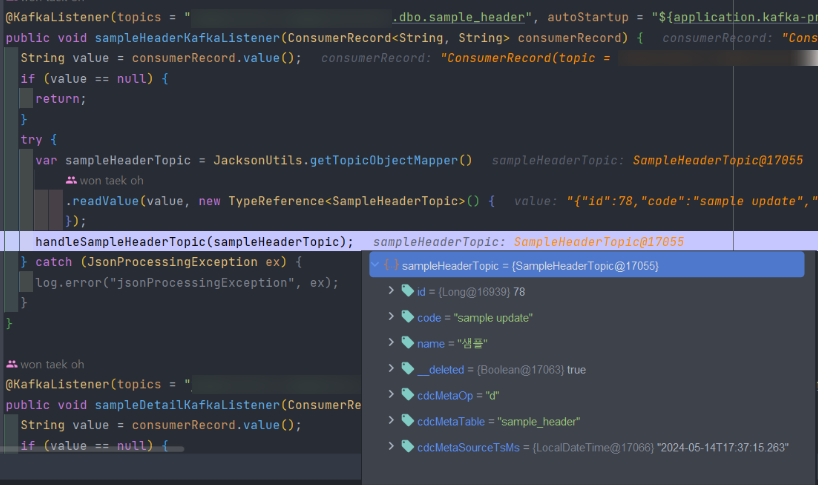
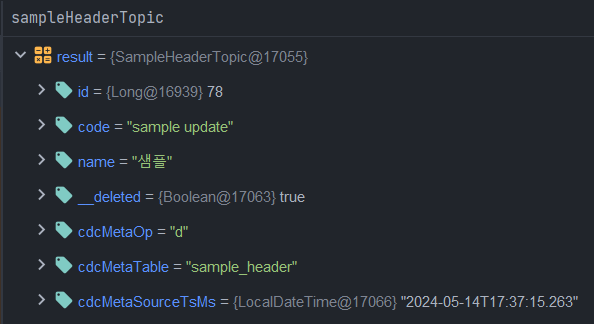
- delete문의 데이터들을 확인할 수 있습니다.
- delete 된 데이터이기 때문에 cdcMetaOp 값이 d 인것을 확인할 수 있습니다.
- delete 된 데이터이기 때문에 __deleted 값이 true인것을 확인할 수 있습니다.
- cdc_reflect_db에 delete문이 반영되어 데이터가 없음
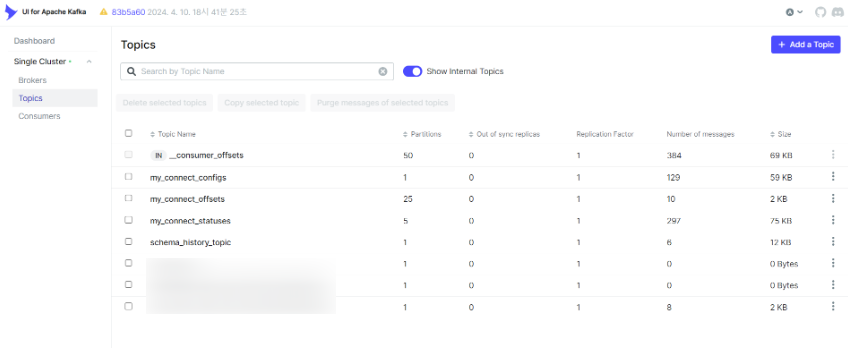
Kafka Ui를 통해 토픽, 메시지 등을 확인
kafka ui를 통해 토픽, 변경된 레코드(메시지), 컨슈머 등등 다양한 정보들을 확인할 수 있습니다. docker-compose를 통해 8090포트로 실행했기 때문에 http://localhost:8090 으로 들어가면 확인할 수 있습니다.
-
토픽 정보
-
메시지(레코드) 정보
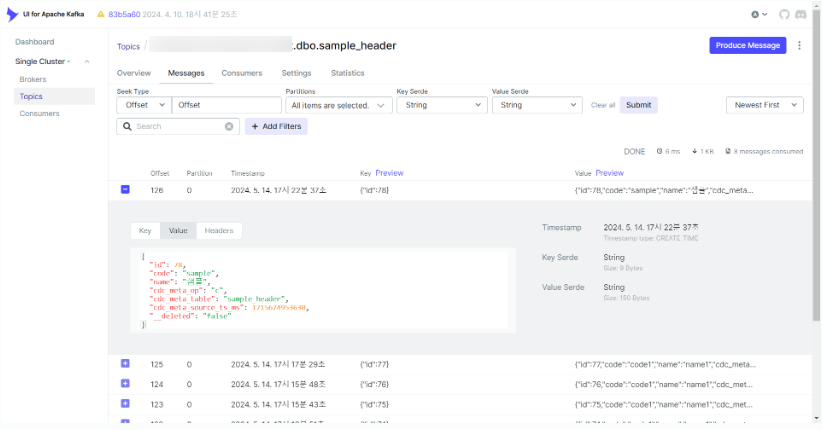
-
INSERT 이벤트로 Producing된 메시지 정보
-
UPDATE 이벤트로 Producing된 메시지 정보
-
DELETE 이벤트로 Producing된 메시지 정보
💣 트러블 슈팅
SQL Server Agent running status query must return exactly one value
Postman으로 connect를 등록했을 때 발생한 에러로 SQL Server 에이전트를 실행시키지 않아서 발생한 에러였습니다.

Caused by: java.lang.IllegalStateException: No thread-bound request found
Consuming을 하는 Spring Boot 프로젝트에서 DB에 저장을 시도할 때 Auditing을 하면서 DB에 저장을 하는데 이 때 SecurityContextHoler를 사용하도록 개발을 하였습니다. 하지만 Kafka Listener를 통해서 저장을 시도하는 요청은 web요청이 아니기 때문에 발생한 에러였습니다.
지금은 Kafka에서 Consuming하는 코드와 Api 서버 코드를 하나의 프로젝트에서 개발하였는데 추후에 멀티모듈로 분리하여 따로 코드를 관리하 수 있도록 리팩터링할 예정입니다.
💣 Window 환경에서 download받아서 실행 했을 때 발생한 트러블 슈팅
docker로 kafka를 실행하려 하기전 kafka 공식 사이트에서 파일을 download 받아서 Window환경에서 실행했을 때 발생한 에러들 입니다. 파일자체에 잘못된 부분이 많아서 고생많이 했습니다.... Window서버는 관심이 없는건가...ㅠㅠ
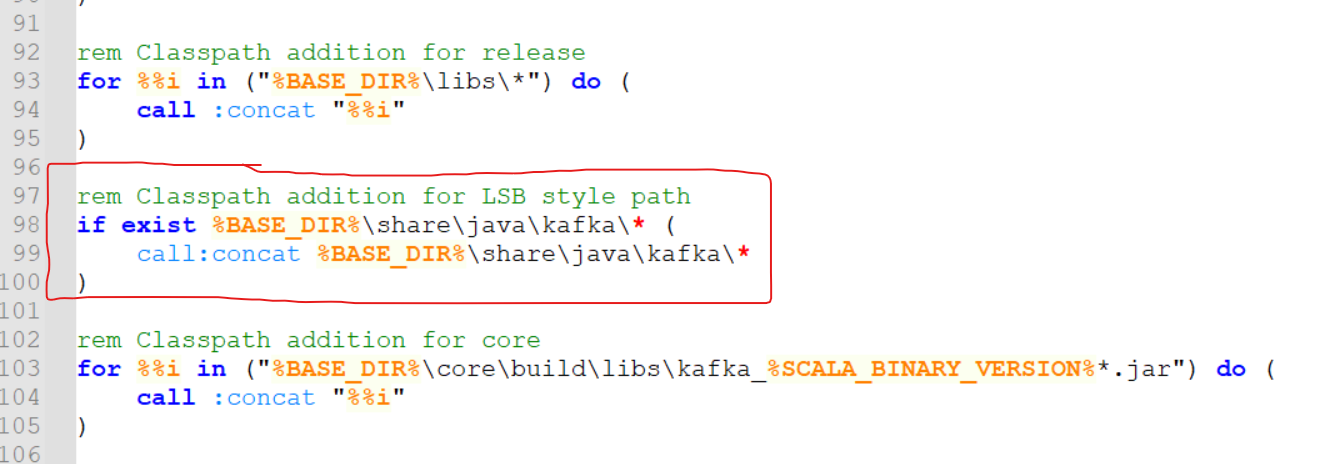
Could not find or load main class org.apache.kafka.connect.cli.ConnectDistributed
confluent-7.6.0\bin\windows\kafka-run-class.bat 파일의 아래의 빨간색 표시의 코드 추가
java.io.FileNotFoundException
//기존 코드
IF ["%KAFKA_LOG4J_OPTS%"] EQU [""] (
set KAFKA_LOG4J_OPTS=-Dlog4j.configuration=file:%BASE_DIR%\config\connect-log4j.properties -Dlog4j.config.dir=%BASE_DIR%/config
)
//수정한 코드: config패키지 자체가 없는데...개발진들이 실수한거같다(window는 신경을 안쓰는건가...)
IF ["%KAFKA_LOG4J_OPTS%"] EQU [""] (
set KAFKA_LOG4J_OPTS=-Dlog4j.configuration=file:%BASE_DIR%\etc\kafka\connect-log4j.properties
)ERROR Shutdown broker because all log dirs in C:\tmp\kafka-logs have failed
kafka 서비스를 실행할 때 발생한 에러로 C:\tmp\kafka-logs 경로 하위의 파일을 삭제하고 다시 실행하니 에러가 해결! 되긴했는데... log 파일을 삭제하는건 좀 아니다싶어서 리눅스 환경에서 환경을 구축하기로 했습니다.
아래는 같은 에러난 블로그 글들인데 다른 방법은 찾지 못했습니다.
[에러해결] ERROR Shutdown broker because all log dirs in C:\tmp\kafka-logs have failed
[KAFKA] Failed to clean up log for __consumer_offsets, Shutdown broker because all log dirs in
Failed to find any class that implements Connector and which name matches io.debezium.connector.sqlserver.SqlServerConnector
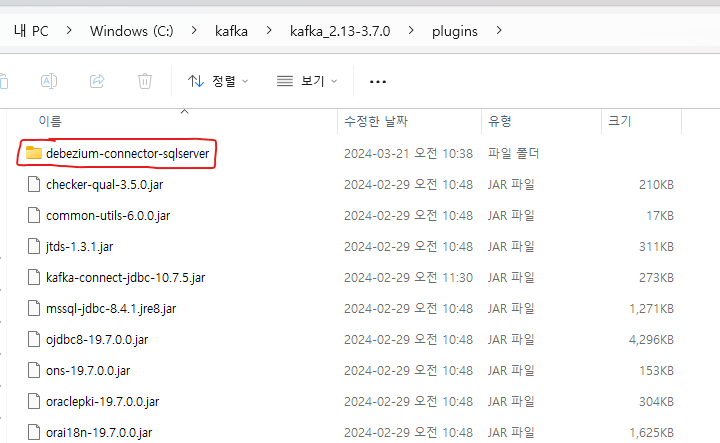
Debezium을 다운로드받고 jar파일을 플러그인을 모아둔 패키지에 옮겼는데 계속해서 플러그인을 찾지 못하는 현상이 발생했습니다.
jar파일만 옮기면 되는줄 알았는데 debezium-connector 라이브러리를 사용하기 위해선 패키지 통채로 옮겨야 가능하더라고요 하하.
✨ 마무리
새로운 기술스택을 공부하면서 실무에 도입해보니 어려움도 많았지만 재밌는 경험이었습니다. 실제 서비스를 하려면 아직 모니터링이나 멀티 브로커, 멀티 모듈 등등 개선해 나아가야할 점이 많습니다... Kafka 도입기 시리즈를 통해 Kafka 기술사용하며 격은 일, 에러를 계속해서 포스팅 하도록 하겠습니다.
