**논문 : "A Survey of Context Engineering for Large Language Models" (2025)
https://arxiv.org/abs/2507.13334
📑 논문 개요
1. 서론 (Introduction)
- 대규모 언어모델(LLM)의 성능은 입력으로 제공되는 **맥락(Context)**에 의해 결정된다.
- 초기에는 단순한 프롬프트(지시문) 설계만으로 모델을 활용했지만, 오늘날의 복잡한 응용에서는 외부 지식, 장기 기억, 도구 활용 등이 통합된 **맥락 엔지니어링(Context Engineering)**이 필수적이다.
- 이 논문은 개별적으로 흩어진 연구들을 **통합적 분류 체계(Taxonomy)**로 정리하여 연구자와 엔지니어가 참고할 수 있는 로드맵을 제시한다.
2. 기본 구성 요소 (Foundational Components)
2.1 Context Retrieval & Generation
- 단순한 지시문 설계(프롬프트 엔지니어링)를 넘어, Zero-shot / Few-shot 학습, Chain-of-Thought, Tree-of-Thought 기법 등을 활용해 더 깊은 추론을 가능하게 한다.
- 외부 데이터베이스, 지식 그래프, 문서 검색을 통해 부족한 정보를 동적으로 불러와 모델의 지식 한계를 보완한다.
- 나아가 여러 정보 조각을 조립하여 **동적 맥락 조립(Dynamic Context Assembly)**을 수행, 작업에 최적화된 입력을 구성한다.
2.2 Context Processing
- 긴 문서나 수십만 토큰의 입력을 처리하기 위해 효율적 주의(attention) 기법, 압축 기법, 스트리밍 처리가 개발되고 있다.
- LLM이 자기 출력을 스스로 검토하고 수정하는 Self-Refinement 기법은 오류를 줄이고 응답의 신뢰성을 높인다.
- 단순 텍스트를 넘어 멀티모달(이미지, 음성, 비디오 등) 데이터를 함께 처리하거나, **구조적 데이터(표, 그래프, 데이터베이스)**를 효과적으로 다루는 방법론도 포함된다.
2.3 Context Management
- 모델이 처리할 수 있는 입력 길이는 제한되어 있어, 메모리 계층 구조와 저장 아키텍처 설계가 필요하다.
- 오래된 정보를 잊고 중요한 정보를 유지하기 위해 맥락 압축(Context Compression) 기법이 사용된다.
- 이 과정을 통해 모델은 제한된 자원 내에서 최적의 정보 밀도를 유지하며 응답 품질을 보장할 수 있다.
3. 시스템 구현 (System Implementations)
3.1 Retrieval-Augmented Generation (RAG)
- LLM 내부 지식만으로는 부족하기 때문에, 외부 문서 검색을 통해 답변의 신뢰성을 높이는 구조다.
- 단순 검색 기반 RAG에서 발전해 모듈형 RAG(plug-and-play 구조), 에이전트 기반 RAG(상황에 따라 검색 전략 선택), 그래프 기반 RAG(지식 관계 구조 활용) 등 다양한 형태로 진화했다.
3.2 Memory Systems
- LLM이 단발성 대화가 아닌 지속적인 상호작용을 위해서는 **단기 메모리(대화 맥락)**와 **장기 메모리(사용자 기록, 지식 저장)**가 필요하다.
- 예를 들어 MemGPT, MemoryBank와 같은 시스템은 마치 인간의 기억처럼 중요한 정보를 저장·검색·갱신할 수 있다.
- 하지만 여전히 평가 지표 부족, 메모리 불일치 문제 등 해결해야 할 과제가 많다.
3.3 Tool-Integrated Reasoning
- 모델이 단순 텍스트 생성만 하는 것이 아니라, **외부 도구(계산기, 데이터베이스, API 등)**를 호출해 문제를 해결하는 방식이다.
- 함수 호출(Function Calling) 메커니즘을 통해 LLM은 필요한 시점에 적절한 도구를 불러와 답변을 강화할 수 있다.
- 이로써 단순 대화형 모델이 아니라, 환경과 상호작용하는 지능형 에이전트로 발전한다.
3.4 Multi-Agent Systems
- 여러 개의 LLM 에이전트가 협력하여 더 복잡한 문제를 해결하는 구조이다.
- 이를 위해서는 통신 프로토콜, 역할 분담 및 조율(Orchestration), **협력 전략(Coordination Strategies)**이 필요하다.
- 대표적으로 AutoGen, CrewAI, CAMEL 같은 시스템이 연구되고 있으며, 이는 인간 조직처럼 다중 에이전트의 협력적 문제 해결을 가능하게 한다.
4. 평가 체계 (Evaluation)
- 컴포넌트 수준 평가: 예를 들어 긴 맥락 처리 능력, 검색 품질, 압축 효율 등을 개별적으로 검증한다.
- 시스템 수준 평가: RAG, 멀티에이전트 등 복합 시스템에서 실제 문제 해결력이 얼마나 향상되는지를 평가한다.
- 평가에는 GAIA, WebArena, SWE-Bench 같은 벤치마크 데이터셋이 사용되며, 여전히 편향, 안전성, 강건성을 측정하는 방법론은 발전 중이다.
5. 미래 연구 방향 (Future Directions & Challenges)
5.1 기초 연구 과제
- 이론적 기반: 컨텍스트 최적화를 수학적/정보이론적으로 정립하는 것이 필요하다.
- 스케일링 법칙: 모델 크기뿐 아니라 맥락 길이 확장에 따른 성능 변화 규칙을 규명해야 한다.
5.2 기술 혁신
- 차세대 아키텍처: Transformer를 넘어서는 새로운 구조(예: State-Space Model)가 연구되고 있다.
- 복잡한 그래프 기반 추론과 맥락 조립 최적화가 주요 과제로 떠오른다.
5.3 응용 지향 연구
- 도메인 특화 맥락 엔지니어링: 의료, 법률, 과학 등 전문 영역에 맞춘 시스템 필요.
- 대규모 다중 에이전트 협력과 인간-AI 협력 모델이 중요한 연구 주제가 될 전망이다.
5.4 사회적 고려
- 실제 서비스 배포 시 확장성과 비용 효율성이 요구된다.
- 동시에 보안, 안전성, 윤리성 문제를 반드시 해결해야 하며, 책임 있는 개발이 강조된다.
6. 결론
- Context Engineering은 LLM을 단순한 언어 생성기에서 상황 인식이 가능한 지능형 시스템으로 발전시키는 핵심 원리이다.
- 연구자에게는 통합 연구 프레임워크, 엔지니어에게는 실용적 설계 지침을 제공하며, 앞으로 AI 발전의 중심축이 될 것으로 전망된다.
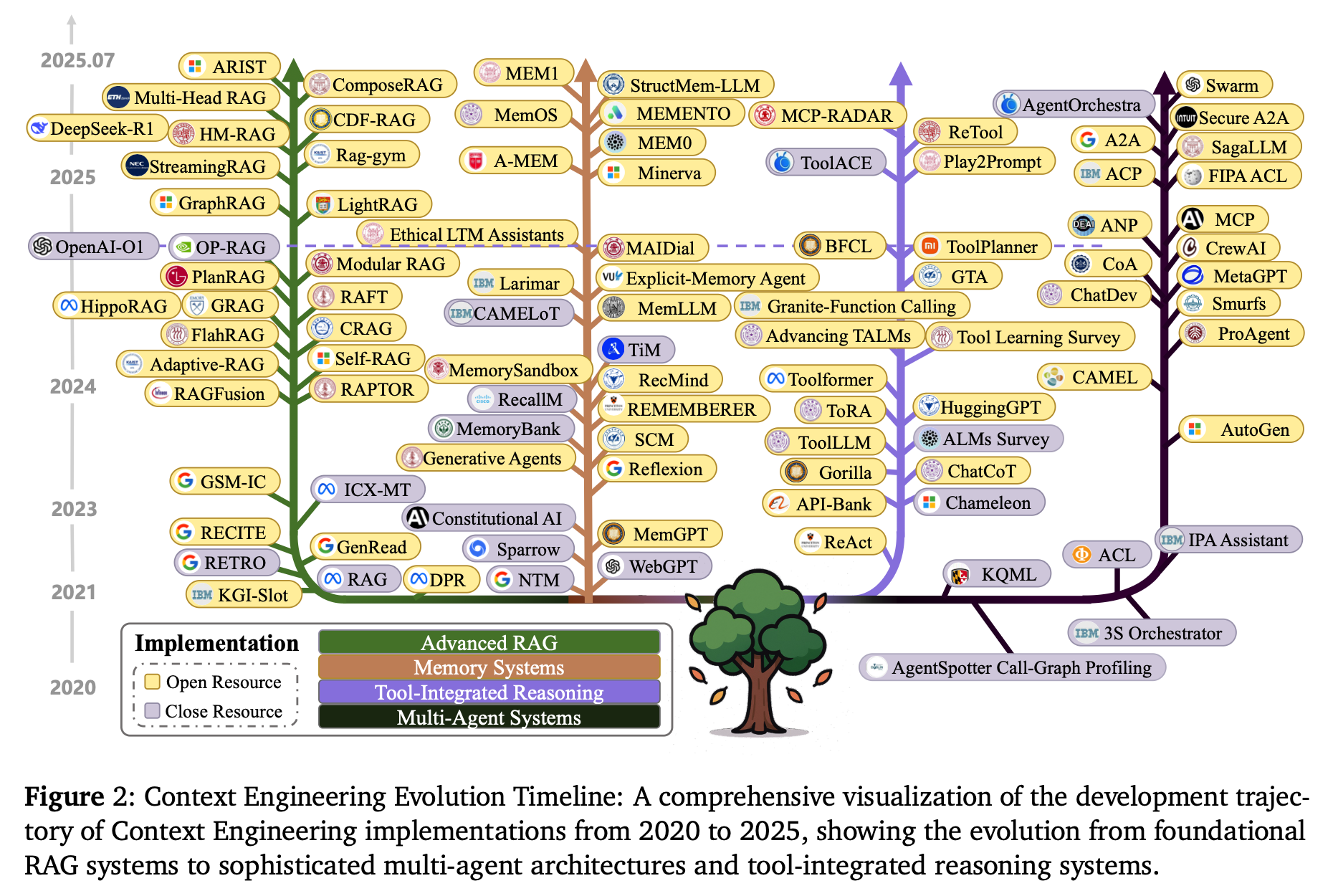
Context Engineering Evolution Timeline은 논문에서 2020년부터 2025년까지의 연구 흐름을 한눈에 보여주는 도표이다. 이 타임라인은 단순한 프롬프트 엔지니어링에서 출발하여 RAG, 메모리 시스템, 도구 통합 추론, 다중 에이전트 시스템으로 발전해온 과정을 정리하고 있다.
📊 Context Engineering Evolution Timeline (상세 설명)
1. 2020–2021: 초기 단계 – RAG와 메모리 개념의 태동
- RAG (Retrieval-Augmented Generation): LLM의 한계를 보완하기 위해 외부 문서 검색과 결합한 초기 RAG 시스템들이 등장.
- NTM (Neural Turing Machine) 같은 신경망 기반 메모리 구조 개념이 다시 주목을 받으며, LLM에 ‘기억’을 심으려는 시도가 시작됨.
- 이 시기는 아직 “Prompt Engineering” 중심이었으나, 점차 컨텍스트를 동적으로 다루는 개념이 연구되기 시작했다.
2. 2022: RAG와 메모리 시스템의 본격화
- RETRO, DPR 같은 대규모 검색 기반 학습 시스템이 발표되며 RAG의 효과가 입증되었다.
- Explicit-Memory Agents(예: MEM0, MEM1)라는 개념이 등장, LLM이 대화나 작업에서 과거 정보를 참조할 수 있는 기초 연구가 진행되었다.
- 이 시기에 “프롬프트 엔지니어링만으로는 한계가 있다”는 인식이 확산되었다.
3. 2023: Tool-Integrated Reasoning과 자기반성적 추론
- ReAct, Toolformer, Gorilla 같은 시스템이 등장하여 LLM이 단순 텍스트 생성기에서 벗어나 외부 도구와 상호작용할 수 있게 됨.
- 자기반성(Self-Refinement) 기법(예: Reflexion)이 등장, 모델이 스스로 출력을 평가하고 개선하는 시도가 본격화됨.
- 이때부터 LLM은 단순 응답기가 아니라, **능동적 문제 해결자(Agent)**로 진화하기 시작했다.
4. 2024: 다중 에이전트 시스템(Multi-Agent Systems, MAS)의 부상
- AutoGen, CAMEL, CrewAI 같은 MAS 프레임워크가 발표되어 여러 LLM 에이전트가 역할을 나누어 협력하는 방식이 연구됨.
- **Agent Communication Protocols (예: A2A, ACP, ANP)**이 등장해, 에이전트 간 협력과 조율(Orchestration)을 가능하게 했다.
- MAS 연구는 단일 모델이 할 수 없는 복잡한 문제 해결을 가능하게 하며, 조직화된 AI 팀 개념이 본격화되었다.
5. 2025 (현재): 고도화와 융합 단계
- Graph-RAG, Modular RAG, Adaptive-RAG 같은 고도화된 검색·지식 조립 시스템이 등장. → 단순한 검색이 아니라, 지식 구조화·최적화까지 포함.
- MemoryBank, MemGPT, MEMENTO 같은 장기 메모리 시스템이 발전하여, LLM이 과거 대화를 영속적으로 저장·검색 가능.
- Granite-Function Calling, ToRA, API-Bank와 같은 고도화된 도구 활용 메커니즘이 보편화됨.
- **다중 에이전트 오케스트레이션(예: SagaLLM, 3S Orchestrator)**이 제안되어, MAS가 실제 대규모 환경에서도 적용 가능해짐.
- 현재 연구의 흐름은 “맥락을 더 잘 다루는 AI”에서 나아가, 스스로 맥락을 조립하고, 기억하고, 협력하는 지능형 에이전트 생태계로 확장되고 있다.
🧭 종합 정리
- 2020–2021: 초기 RAG, 메모리 개념 등장
- 2022: RAG·메모리 본격 연구
- 2023: 도구 활용, 자기반성(Self-Refinement) 기법 확산
- 2024: 다중 에이전트 시스템(MAS) 부상
- 2025: 고도화·융합 단계 (Graph-RAG, Memory Systems, MAS 오케스트레이션)
즉, 5년간의 흐름은 Prompt → RAG → Memory → Tool Integration → Multi-Agent Systems로 이어지는 발전의 연속이며, 이를 논문은 Context Engineering의 진화 과정으로 정리하고 있습니다.

Hello, I'm Terry! 👋 Enjoy every moment of your life! 🌱 My current interests are Signal processing, Machine learning, Python, Database, LLM & RAG, MCP & ADK, Multi-Agents, Physical AI, ROS2...