자료구조
1.[자료구조] 1. 자료구조와 알고리즘

사람들이 사물을 정리하는 것과 마찬가지로 프로그램에서 자료(Data)들을 정리하는 여러가지 구조컴퓨터 프로그램은 논리적으로 따져보면 '자료구조'와 '알고리즘'으로 구성되어있다.자료구조와 알고리즘은 밀접한 관계가 있고 자료구조가 결정되면 그 자료구조에서 사용할 수 있는
2.[자료구조] 2. 순환
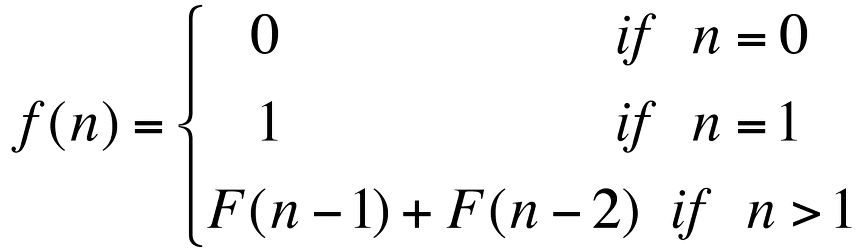
순환의 소개 순환(Recursion)이란 어떤 알고리즘이나 함수가 자기 자신을 호출하여 문제를 해결하는 프로그래밍 기법이다. 순환 알고리즘은 '자기 자신을 순환적으로 호출하는 부분'과 '순환 호출을 멈추는 부분'으로 구성되어 있다. 반드시 순환 호출에는 순환 호출을
3.[자료구조] 3. 배열, 구조체, 포인터
배열 배열(Array)이란 여러 개의 동일한 데이터 타입의 데이터를 한 번에 만들 때 사용된다. 각각의 변수를 선언하는 것보다 배열을 사용하면 인덱스 번호를 가지고 작업을 할 수 있기 때문에 인덱스 번호에 따라 효율적으로 루프를 설정하여 여러 상황에서 간단한 코드를
4.[자료구조] 4. 리스트
리스트의 소개 리스트(List) 또는 선형 리스트(Linear list)는 우리들이 자료를 정리하는 방법 중의 하나이다. 우리는 일상생활에서 많은 리스트를 사용하고 있고 리스트에는 보통 항목들이 차례대로 정리되어 있다. 리스트의 항목들은 순서 또는 위치를 가진다.
5.[자료구조] 4. 리스트 part 2

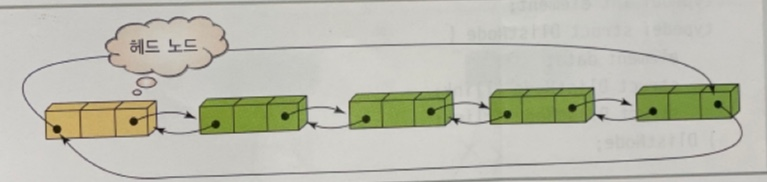
원형 연결 리스트란 리스트의 마지막 노드의 링크가 NULL이 아닌 첫 번째 노드 주소가 되는 리스트이다.원형 연결 리스트의 장점이라면 한 노드에서 다른 모든 노드로의 접근이 가능하다는 것이다.하나의 노드에서 링크를 계속 따라가면 결국 모든 노드를 거쳐서 자기 자신으로
6.[자료구조] 4. 리스트 part 3
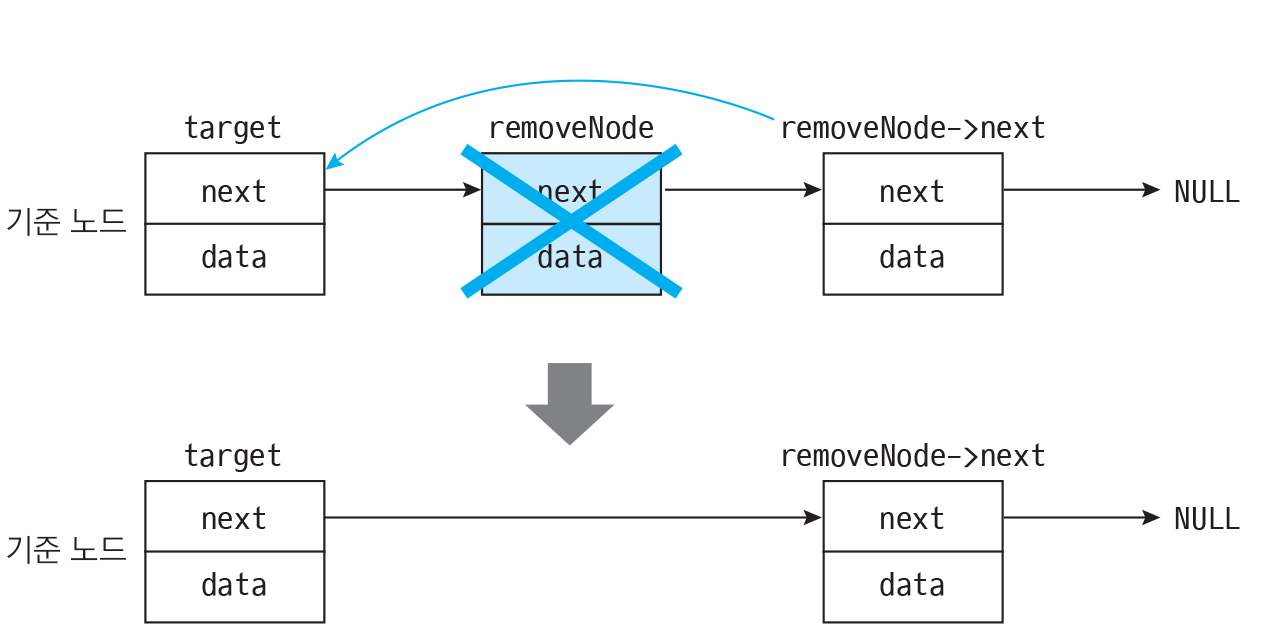
단순 연결 리스트에서의 어떤 노드에서 후속 노드를 찾기는 쉽지만, 선행 노드를 찾으려면 구조상 아주 어렵다.단순 연결 리스트의 경우에는 헤드 포인터부터 시작해서 탐색을 하여야 한다.원형 연결 리스트라고 하더라도 거의 전체의 노드를 거쳐서 돌아와야 한다.따라서 응용 프로
7.[자료구조] 4. 리스트 응용

다항식은 단순 연결 리스트로 표현 가능한데, 이 경우에 각 항이 하나의 노드로 표현된다.각 노드는 계수(coef)와 지수(expon) 그리고 다음 항을 가리키는 링크(link)필드로 구성되어 있다.각 다항식은 다항식의 첫 번째 항을 가리키는 포인터로 표현된다.ListN
8.[자료구조] 4. 연결 리스트로 구현된 리스트

이번 절에서는 연결 리스트를 이용하여 리스트 ADT를 구현하여보자.여기서는 연결 리스트 중에서 단순 연결 리스트를 사용한다.선형 리스트의 여러 가지 연산 중에서 add 연산과 delete 연산을 중점적으로 설명하고자 한다.먼저 연결 리스트의 삽입 함수인 insert_n
9.[자료구조] 5. 스택
스택 추상 데이터 타입 스택(stack)은 가장 최근에 들어온 데이터가 가장 위에 있고, 또 먼저 나가게 된다. 이런 입출력 형태를 후입 선출(LIFO : Last-In First-Out)이라고 한다. 스택은 이러한 후입 선출의 형식으로 입출력이 일어나는 자료 구
10.[자료구조] 5. 스택 part 2
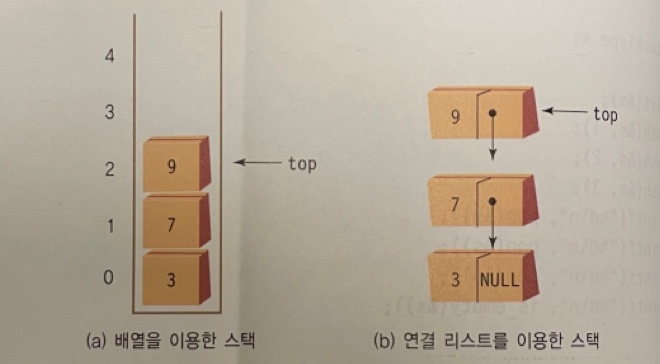
이러한 스택이나 큐를 연결된 스택(linked stack)이라고 한다.제공되는 외부 인터페이스는 완전히 동일하다. 달라지는 것은 스택의 내부 구현이다.연결 리스트를 이용하여 스택을 만들게 되면 크기가 제한되지 않는다는 큰 장점이 있다.동적 메모리 할당만 할 수 있으면
11.[자료구조] 스택 응용 - 괄호 검사
프로그램에서는 여러 가지 타입의 괄호들이 같은 타입으로 쌍으로 존재하여야 한다.프로그램에서는 대괄호\[], 중괄호{}, 소괄호() 등이 사용되는데 괄호의 검사 조건은 다음의 3가지 이다.왼쪽과 오른쪽의 괄호의 개수가 같아야 한다.같은 타입의 괄호에서 왼쪽 괄호는 오른쪽