순환의 소개
순환(Recursion)이란 어떤 알고리즘이나 함수가 자기 자신을 호출하여 문제를 해결하는 프로그래밍 기법이다.
int factorial(int n) { //팩토리얼 함수
printf("factorial(%d)\n", n);
if (n <= 1)return 1; //순환 호출을 멈추는 부분
else return n * factorial(n - 1); //자기 자신을 순환적으로 호출하는 부분
}순환 알고리즘은 '자기 자신을 순환적으로 호출하는 부분'과 '순환 호출을 멈추는 부분'으로 구성되어 있다.
반드시 순환 호출에는 순환 호출을 멈추는 문장이 포함되어야 한다.
순환과 반복
프로그래밍 언어에서 되풀이하는 방법에는 반복(Iteration)과 순환(Recursion)의 2가지가 있다.
반복이란 for문이나 while문 등의 반복 구조를 사용하여 반복시키는 문장을 작성하는 것으로 간명하고 효율적으로 되풀이를 구현하는 방법이다.
순환은 주어진 문제를 해결하기 위하여 하나의 함수에서 자신을 다시 호출하여 작업을 수행하는 방식이다.
기본적으로 반복과 순환은 문제 해결 능력이 같으며 많은 경우에 순환 알고리즘을 반복버전으로, 반복 알고리즘을 순환 버전으로 바꾸어 쓸 수 있다.
특히 순환 호출이 끝에서 이루어지는 순환을 꼬리 순환(Tail recursion)이라고 하는데, 이를 반복 알고리즘으로 쉽게 바꾸어 쓸 수 있다.
순환은 어떤 문제에서는 반복에 비해 알고리즘을 훨씬 명확하고 간결하게 나타낼 수 있지만 일반적으로 순환은 함수 호출을 하게 되므로 반복에 비해 수행속도 면에서는 떨어진다.(알고리즘을 설명할 때는 순환으로 하고 실제 프로그램에서는 반복 버전으로 바꾸어 코딩하는 경우도 있음)
int factorial_iter(int n) { //반복 팩토리얼
int k,v=1;
for (int k = n; k > 0; k--) {
v = v * k;
}
return v;
}문제의 정의가 순환적으로 되어 있는 경우 순환으로 작성하는 것이 훨씬 더 쉽고 대개 순환 형태의 코드가 더 이해하기 쉽다.
따라서 이런 경우에는 프로그램의 가독성이 증대되고 코딩이 더 간단하지만 실행 시간이 오래걸린다는 단점이 있다.(그러나 적지 않게 순환을 사용하지 않으면 도저히 프로그램을 작성할 수 없는 경우가 종종 있음)
순환의 원리
순환은 일부의 문제를 해결한 다음, 순환 호출을 한다는 특징이 있다.
주어지는 문제를 더 작은 동일한 문제들로 분해하여 해결하는 방법을 분할 정복(Divide and conquer)이라고 하는데, 여기서 중요한 것은 순환 호출이 일어날 때마다 문제의 크기가 작아진다는 것이다.
문제의 크기가 점점 작아지면 풀기가 쉬워지고 결국은 아주 풀기 쉬운 문제가 된다.
ex)팩토리얼 함수 계산, 피보나치 수열, 이항 계수 계산, 각종 이진 트리 알고리즘, 이진 탐색, 하노이탑 문제
순환 알고리즘의 성능
위의 팩토리얼 계산의 반복 알고리즘과 순환 알고리즘의 시간 복잡도는 O(n)으로 동일하지만 순환 호출의 경우 여분의 기억 공간이 더 필요하고, 또한 함수를 호출하기 위해서는 함수의 파라미터들을 스택에 저장하는 것과 같은 사전 작업이 상당히 필요하다. 따라서 실행 시간도 더 걸린다.
결론적으로 순환 알고리즘은 이해하기 쉽다는 것과 쉽게 프로그래밍할 수 있다는 장점이 있지만 대신에 수행 시간과 기억 공간의 이용에 있어서는 비효율적인 경우가 많다.
순환 호출 시에는 호출이 일어날 때마다 호출하는 함수의 상태가 기억되어야 하므로 여분의 기억 장소가 필요한 것이다.
거듭제곱 값 계산
순환적인 방법이 더 빠른 예제를 다루기 위해 숫자 x의 n-거듭제곱 값인 x^n을 구하는 함수를 작성하여보자.
만약에 순환을 생각하지 않고 작성한다면 다음과 같이 작성할 수 있다.
double power_iter(double x, int n) {
double result = 1.0;
for (int i = 0; i < n; i++) {
result *= x;
}
return result;
}다음은 순환의 개념을 사용하여 n거듭제곱 값인 x^n을 구하는 함수를 작성해보자.
double power(double x, int n) {
if (n == 0)return 1;
else if (n % 2 == 0) return power(x * x, n/2);
else return x * power(x * x, (n - 1) / 2);
}순환 알고리즘이 더 복잡해보이고 함수 호출이라는 오버헤드도 있지만 놀랍게도 순환적인 power 함수가 더 빠르다.
그 이유는 한 번의 순환 호출을 할 때마다 문제의 크기는 약 절반으로 줄어들기 때문이다.
순환 알고리즘의 시간 복잡도는 O(log2n), 반복 알고리즘의 시간 복잡도는 O(n)이다.
피보나치 수열의 계산
순환을 사용하게 되면 보통 단순하게 작성이 가능하며 가독성이 높아진다.
그러나 똑같은 계산을 몇 번씩 반복한다면 아주 단순한 경우라 할지라도 계산 시간이 엄청나게 길어질 수 있다.
이러한 예로 피보나치 수열이 있다.
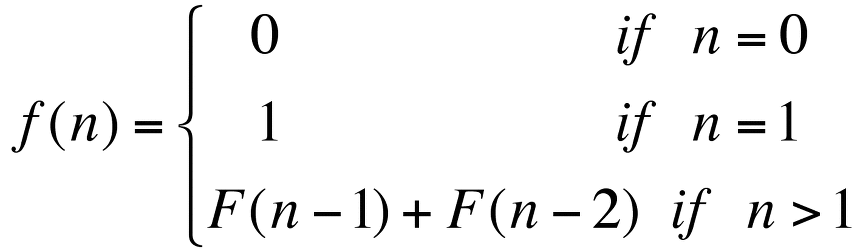
int fib(int n) {
if (n == 0) return 0;
else if (n == 1) return 1;
else return fib(n - 1) + fib(n - 2);
}위의 함수는 매우 단순하고 이해하기 쉽지만 매우 비효율적이다.
그 이유는 중복되는 계산이 존재하기 때문이다.
이러한 현상은 순환 호출이 깊어질수록 점점 심해지기 때문에 상당히 비효율적임을 알 수 있다.
근본적인 이유는 중간에 계산되었던 값을 기억하지 않고 다시 계산을 하기 때문이다.(동적 프로그래밍 Dynamic programming으로 해결 가능)
n이 작을 때는 중복 계산이 비교적 작지만 n이 커지게 되면 엄청난 순환 호출이 필요하게 된다.
따라서 n이 커지면 순환 호출을 사용하여 피보나치 수열을 계산하는 것은 거의 불가능하다.
이 경우에는 순환보다는 반복 구조를 이용하여 프로그래밍하면 제일 좋은 결과를 얻을 수 있다.
int fib_iter(int n) {
if (n < 2) return n;
else {
int result, p1=1,p2=0;
for (int i = 2; i <= n; i++) {
result = p1 + p2;
p2 = p1;
p1 = result;
}
return result;
}
}하노이탑 문제

한 번에 하나의 원판만 이동할 수 있다.
맨 위에 있는 원판만 이동할 수 있다.
크기가 작은 원판 위에 큰 원판이 쌓일 수 없다.
중간의 막대를 임시적으로 이용할 수 있으나 앞의 조건들을 지켜야 한다.
이 문제는 순환적으로 생각하면 쉽게 해결할 수 있다. 순환에서는 순환이 일어날수록 문제의 크기가 작아져야 한다.
n개의 원판이 A에 쌓여 있는 경우,
- 먼저 위에 쌓여 있는 n-1개의 원판을 B로 옮긴다.
- 제일 밑에 있는 원판을 C로 옮긴다.
- B에 있던 n-1개의 원판을 C로 옮긴다.
여기서 문제는 B에 쌓여 있던 n-1개의 원판을 어떻게 C로 옮기느냐이다.
void hanoi_tower(int n,char from,char tmp,char to){
if(n==1){
from에서 to로 원판을 옮긴다.
}
else{
1. from의 맨 밑의 원판을 제외한 나머지 원판들을 tmp로 옮긴다.
2. from에 있는 한 개의 원판을 to로 옮긴다.
3. tmp의 원판들을 to로 옮긴다.
}
}유사 코드 중에서 2.는 한 개의 원판을 이동하는 것이므로 매우 쉽고 문제는 n-1개의 원판을 이동하여야 하는 1.과 3.을 어떻게 해결하느냐이다.
그러나 자세히 보면 1.과 3.은 막대의 위치만 달라졌을 뿐 원래 문제의 축소된 형태라는 것을 발견할 수 있다.
1.은 to를 사용하여 from에서 tmp로 n-1개의 원판을 이동하는 문제이고,
3.은 from을 사용하여 tmp에서 to로 n-1개의 원판을 이동하는 문제이다.
따라서 순환 호출을 사용하면 다음과 같이 다시 작성할 수 있다.
void hanoi_tower(int n, char from, char tmp, char to) {
if (n == 1) printf("원판 1을 %c에서 %c으로 옮긴다.\n", from, to);
else {
hanoi_tower(n - 1, from, to, tmp);
printf("원판 %d을 %c에서 %c으로 옮긴다.\n", n, from, to);
hanoi_tower(n - 1, tmp, from, to);
}
}반복적인 형태로 바꾸기 어려운 순환
팩토리얼 예제에서 다음 문장들의 차이는 무엇일까?
- return n*factorial(n-1);
- return factorial(n-1)*n;
꼬리 순환(Tail recursion)은 1처럼 순환 호출이 순환 함수의 맨 끝에서 이루어지는 형태의 순환이다.
꼬리 순환의 경우, 알고리즘은 쉽게 반복적인 형태로 변환이 가능하지만 2와 같은 머리 순환(Head recursion)의 경우나 방금 살펴본 하노이탑 문제처럼 여러 군데에서 자기 자신을 호출하는 경우(Multi recursion)는 쉽게 반복적인 코드로 바꿀 수 없다.
이런 경우에도 명시적인 스택을 만들어서 순환을 시뮬레이션할 수는 있긴 하다.
만약 동일한 알고리즘을 꼬리 순환과 머리 순환 양쪽으로 모두 표현할 수 있다면 당연히 꼬리 순환으로 작성하여야 한다.
