Numpy
- Numerical Python
- 벡터, 행렬 연산을 위한 수치해석용 파이썬 라이브러리
- 다차원 배열 지원
- 빠른 수치 계산, 벡터화 연산, 브로드캐스팅 기법 등을 통한 다차원 배열과 행렬 연산에 필요한 다양한 함수 제공, 데이터 수집 및 연산에 최적화
- 다수의 과학 연산 라이브러리들이 Numpy 기반
- scipy, matplotlib, pandas, scikit-learn, statsmodels
Numpy 데이터 구조


Numpy 배열 (ndarray)
- Numpy에서 제공하는 자료 구조, N차원 배열 객체
- 같은 타입의 값들만 가질 수 있음
- 축별 데이터 개수는 모두 동일
배열 생성 함수
array(iterable [, dtype])
# 3개의 2차원 배열 생성
A1 = np.array([[1, 2, 3], [4, 5, 6]])
A2 = np.array([[7, 8, 9], [10, 11, 12]])
A3 = np.array([[13, 14, 15], [16, 17, 18]])- iterable 객체가 가진 원소들로 구성된 numpy 배열 생성
- 원하는 값들로 구성된 배열을 만들 때 사용
- 다차원 배열을 만들 경우 축 별 데이터 개수가 동일하도록 해야함
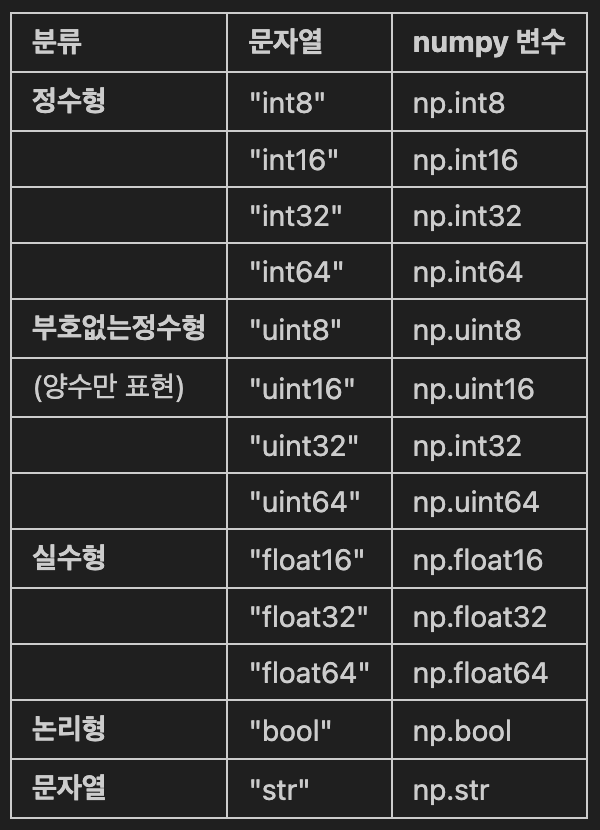
- 생성 시 데이터타입 설정이 가능
- 한 배열 내 여러 개의 데이터 타입이 존재할 시 우선순위가 높은 데이터 타입으로 통일 *데이터 타입 우선순위: bool < int < float < complex < str < object
동일한 값들로 구성된 배열 생성
- 0벡터 배열 생성
zeros(shape [, dtype])shape=[int]: 1차원 배열, 원소 개수 [int]개 생성shape=(tuple): 다차원 배열의 각 축별 size 지정
(ex) shape = (4, 5, 2) ⇒ 각각의 축 데이터가 4, 5, 2개인 3차원 배열 생성dtype=””: 데이터 타입 지정, 생략 시 float64
- 1벡터 배열 생성
ones(shape [,dtype])shape =,dtype =동일
- 원하는 값으로 채운 배열 생성
full(shape, fill_value [, dtype]))shape =,dtype =동일fill_value =: 채울 값
난수(Random)를 원소로 하는 ndarray 생성
np.random.seed(시드값)
- 난수 발생 알고리즘이 사용할 시작값(=시드값) 설정
- 시드값 설정 시 항상 일정한 순서의 난수 발생
- 시드값은 숫자 아무거나 상관 X, 특정 숫자에 시드값을 심어둔다고 생각하면 편함
- 랜덤함수는 특정 숫자부터 시작하는 일렬의 수열을 만들어 값을 제공하는 함수로, 시작 숫자는 실행할 때마다 바뀌어 다른 값들이 나옴. 그러나 np.random.seed(시드값)을 통해 시작값을 고정시키면 항상 시작값이 같으므로 같은 값들이 순서대로 제공됨
- 서칭하다 레딧에서 좋은 비유를 발견해 첨부 🔗 링크
“
random.seed()는 무작위 숫자 책을 특정 페이지로 펼치는 거랑 같아. 그 페이지의 숫자들은 여전히 무작위지만, 어떤 페이지를 펼쳤는지 기억하면 항상 같은 무작위 숫자들을 얻을 수 있지. 파이썬에서는, 코드가 매번 실행할 때마다 일관된 결과를 낸다는 뜻이야. ”
⇒ 어떤 페이지 = 시드값, 특정 페이지의 무작위 숫자 = 시드값에 저장된 숫자들로 이해할 수 있음# 난수를 원소로 하는 배열 A5 생성 np.random.seed(0) # 시드 설정 A5 = np.random.rand(1, 5) # 1행 5열 배열 생성 A5 # 출력값 array([[0.5488135 , 0.71518937, 0.60276338, 0.54488318, 0.4236548]]) # 난수를 원소로 하는 배열 A6 생성 np.random.seed(0) # 시드 설정 A6 = np.random.rand(2,5) # 2행 5열 배열 생성 A6 # 출력값 - 시드에 저장되었던 5개의 숫자는 유지되고, 그 다음 행의 숫자들은 새롭게 생성됨 array([[0.5488135 , 0.71518937, 0.60276338, 0.54488318, 0.4236548 ], [0.64589411, 0.43758721, 0.891773 , 0.96366276, 0.38344152]])
정규분포
- 연속 확률 분포 중 하나
- 평균 근처에 가장 많은 값들이 모여 있고 평균으로부터 표준편차만큼 멀어질 수록 적게 분포됨
- 정규분포에서는 1표준편차 범위에 전체 데이터의 68%가, 2표준편차 범위에 95% 정도가, 3표준편차 범위에 99.7%가 분포되어 있음
- 표준정규분포 : 평균 0, 표준편차 1인 정규 분포
각종 Numpy 메소드
- 정규분포를 따르는 난수 배열 생성
np.random.normal(loc=0.0, scale=1.0, size=None)- loc : 평균
- scale : 표준편차
- loc, scale 생략 시 표준정규분포를 따르는 난수 생성
- 임의의 정수를 가지는 배열 생성
np.random.randint(low, high=None, size=None, dtype='int32')- low ~ high 사이의 정수 리턴. high는 미포함
- high 생략 시 0 ~ low 사이 정수 리턴. low는 미포함
- size : 배열의 크기. 다차원은 튜플로 지정 기본 1개
- dtype : 원소의 타입
- 샘플링(표본 추출)
np.random.choice(a, size=None, replace=True, p=None)- a : 샘플링대상. 1차원 배열 또는 정수 (정수일 경우 0 ~ 정수, 정수 불포함)
- size : 샘플 개수
- replace : True-복원추출(기본), False-비복원추출
- p: 샘플링할 대상 값들이 추출될 확률 지정한 배열
ndarray 배열 저장
- 한개 파일에 한개 배열 저장
np.save("파일경로", 배열)- 배열을 raw 바이너리 형식으로 저장(확장자: .npy)
- 한개 파일에 여러개 배열 저장
np.savez("파일경로", 이름=배열, 이름=배열, ...)- 여러개의 배열을 한개 파일에 저장 (확장자: .npz)
- 내부적으로 압축 후 저장
ndarray 배열 불러오기
np.load("파일경로")
- 파일에 저장된 배열을 불러오기
- npz의 경우 저장된 배열들을 묶어서 반환, 저장할 때 배열에 지정한 이름을 이용해 조회
배열 인덱싱
배열[index]
- 다차원 배열의 경우 , 를 구분자로 축별 index 지정 필요
import numpy as np
a = np.arange(30).reshape(5, 6)
a[0] # (0축: 5, 1축: 6) => 0축 기준 첫번째 값을 조회
a[1, 3] # a[0축 index , 1축 index]
a[[1, 1, 3], [1, 4, 4]] # [1, 1], [1, 4], [3, 4]]배열 슬라이싱
ndarry[start : stop : step]
- start : 시작 인덱스. 기본값 0
- stop : 끝 index. stop은 포함하지 않는다. 기본값 마지막 index
- step : 증감 간격. 기본값 1
- 다차원 배열은 , 로 축을 구분한 후 다중 슬라이싱 사용
# 2차원 배열 a의 0축: 1~3, 1축: 1~4
a[1:4, 1: 5]