A Tutorial on Energy-Based Learning
0. About
- EBM에 대해서 제대로 공부하기 위해서, 그 origin부터 들어가려고 하는중
- 2006년 얀 르쿤의
A Tutorial on Energy-Based Learning의 리뷰 - 100% 리뷰 보다는 스킴 위주, 내 사견으로 재해석한(?) 리뷰
1. Introduction: Energy-Based Models
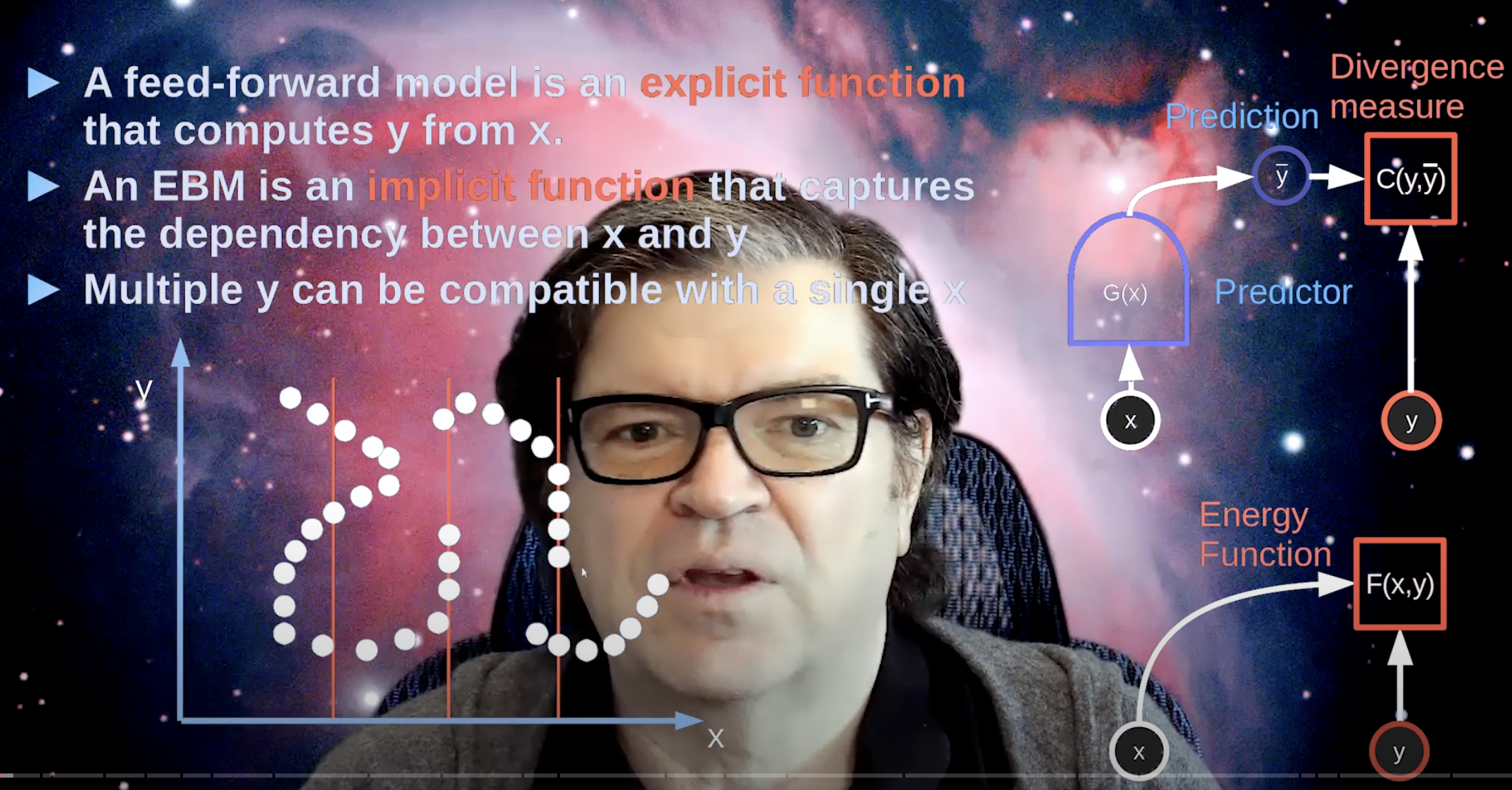
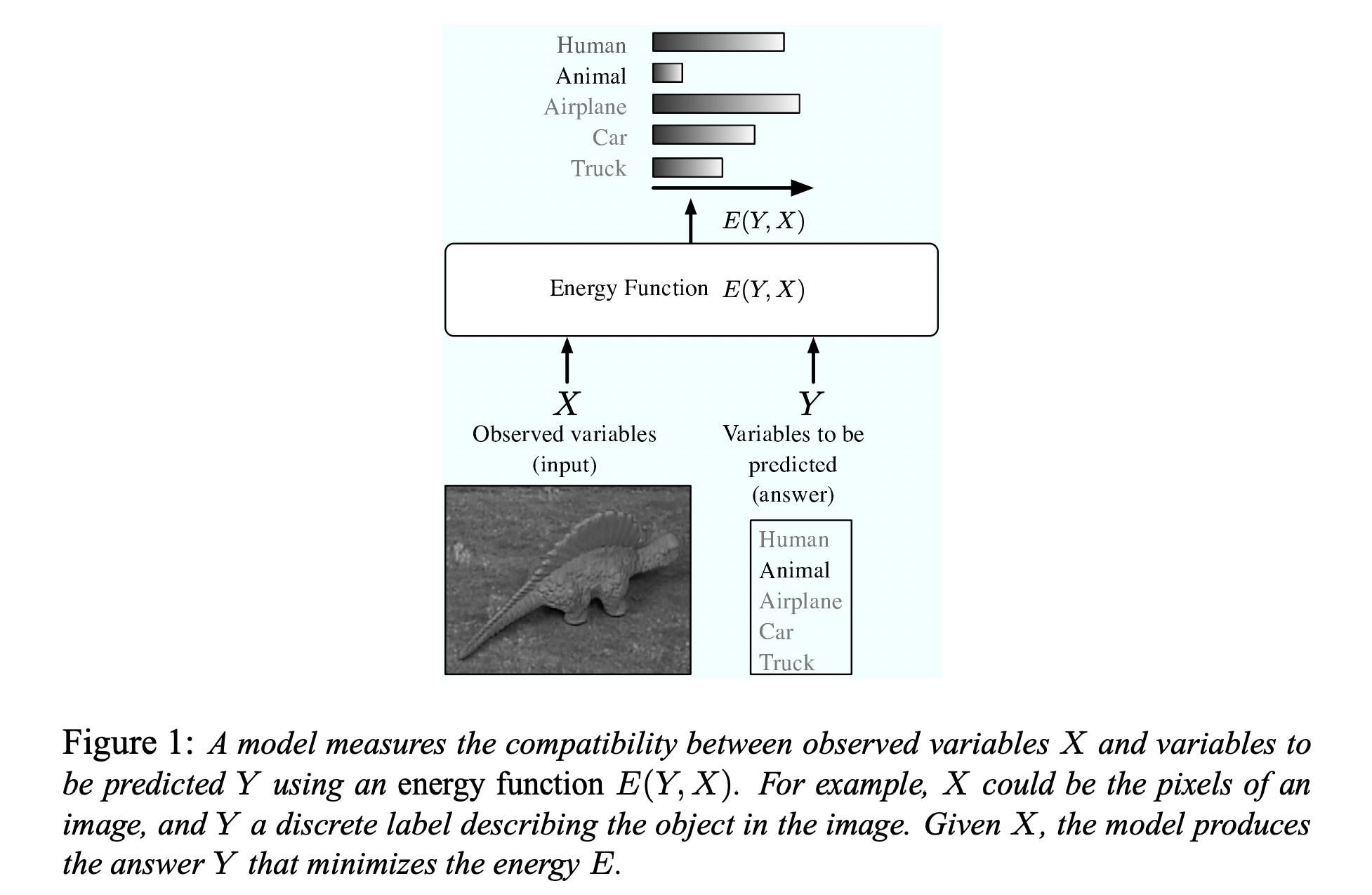
Energy-Based Models (EBMs) capture dependencies by associating a scalar energy (a measure of compatibility) to each configuration of the variables.
Energy란 스칼라 값으로 표현되는 compatibility 정도임;- ML(또는 statiscal modeling)을 variables 사이의 dependencies를 encoding하는 과정이라고 보았을 때, variable간의 호환 정도를 energy라는 스칼라 값으로 나타내는 것임.
- low energy ~ 높은 안정성(호환성), high energy ~ 낮은 안정성(호환성)
- 이러한 관점에서 보았을 때, 다음 용어들을 energy로 다시 설명할 수 있음.
inference:
Observed variables ()로부터, 에너지를 최소화 시키는 remaning variables () 의 값을 찾는 것. that minimizeslearning:
좋은 energy function 를 찾는 과정; remaining variable이 정답일 경우 낮은 에너지를, 오답일 경우 높은 에너지를 할당하도록.loss function:
학습중에 minimize되는 값으로, energy function의 quality 측정- 그럼 사실상 energy function이랑 loss랑 동일 한 것 아니냐? - 실제로 가장 간단한 형태의 loss function은 energy function 그 자체로 쓸 수 있다. 동일한 개념은 아님.
loss에는 regularizer와 같은 prior knowledge가 포함 될 수 있음.
- 에너지를 화학 등에서 사용되는 결합 에너지 그래프 처럼 생각하면 직관적으로 이해가 쉬울듯! (위 그림) 결국 좋은 에너지 함수 모델링을 하는 것이 목표!
- 또는 간단하게 각 prediction에 대한 entropy로 대충 생각해도 큰 문제가 없어 보인다. 굉장히 비슷하게 설명이 되는 것 같다.
2. Loss and Architecture
- 이 부분은 흔한 딥러닝 기초 파트와 거의 유사하기에, 기존에 다루지 않는 부분만 남기겠음.
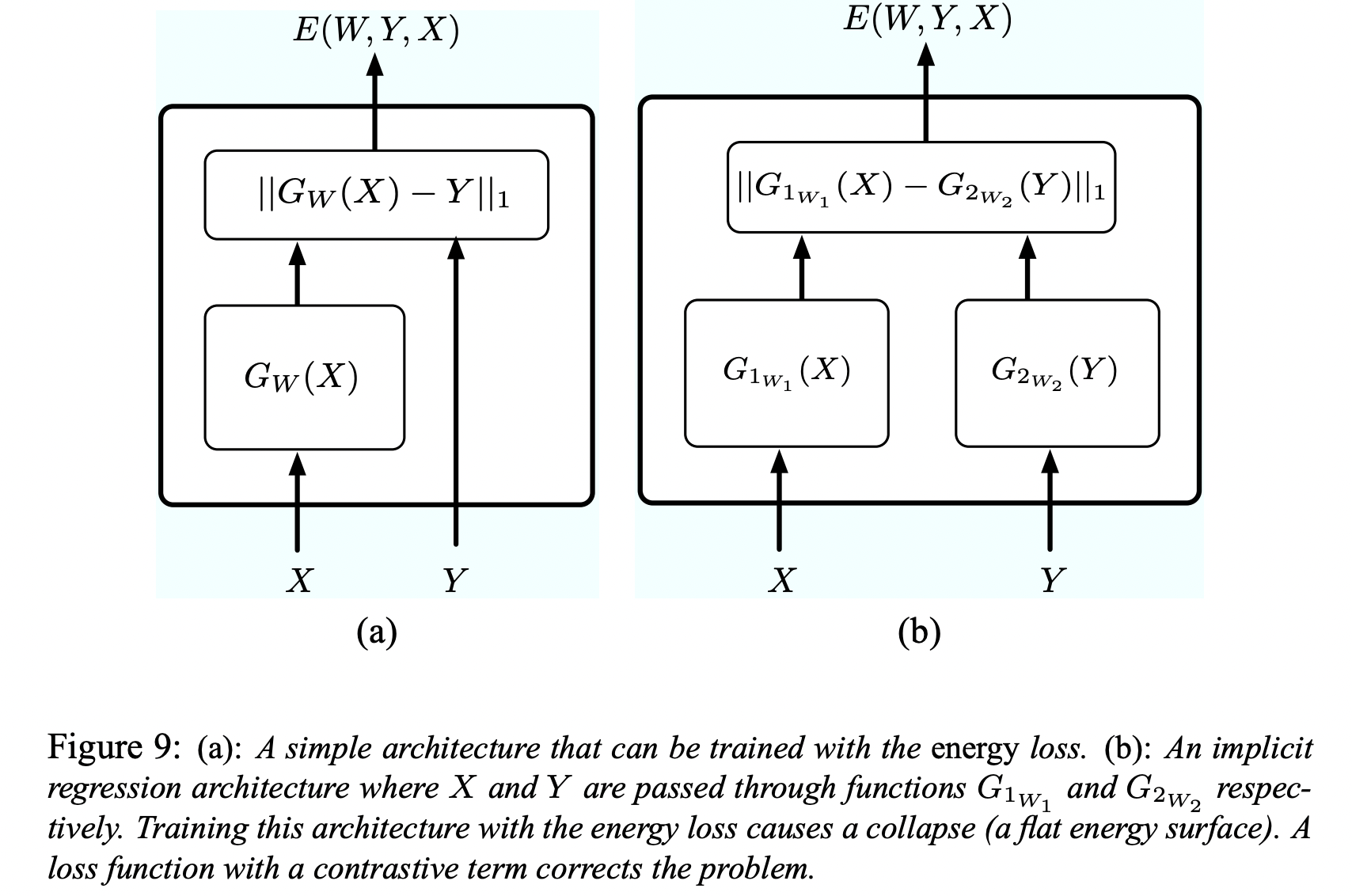
- JEPA에서 봤던 아이디어인데, 여기서 유래 한 것 같다. 에 대한 인코더 또한 사용하여 임베딩간의 compatibability를 energy function 로 사용할 수 있다. 이를
Implicit Regression이라고 한다. - 가끔 와 사이의 dependencies가 to 의 함수로만 설명 하기 힘든 경우가 있다. 예를 들어, "" 처럼. 에 대해 호환성이 높은(낮은 에너지를 가진) multiple 를 허용할 때, 가능한 디자인이다.
3. Good Loss functions for EBMs
- 그럼 좋은 Loss Function (energy function의 퀄리티를 측정)의 조건은 뭘까? 정답 쌍(, )에 낮은 에너지를 잘 할당하는지 만으로는 좋은 loss라고 평가할 수는 없다. 적절히 calibration되어
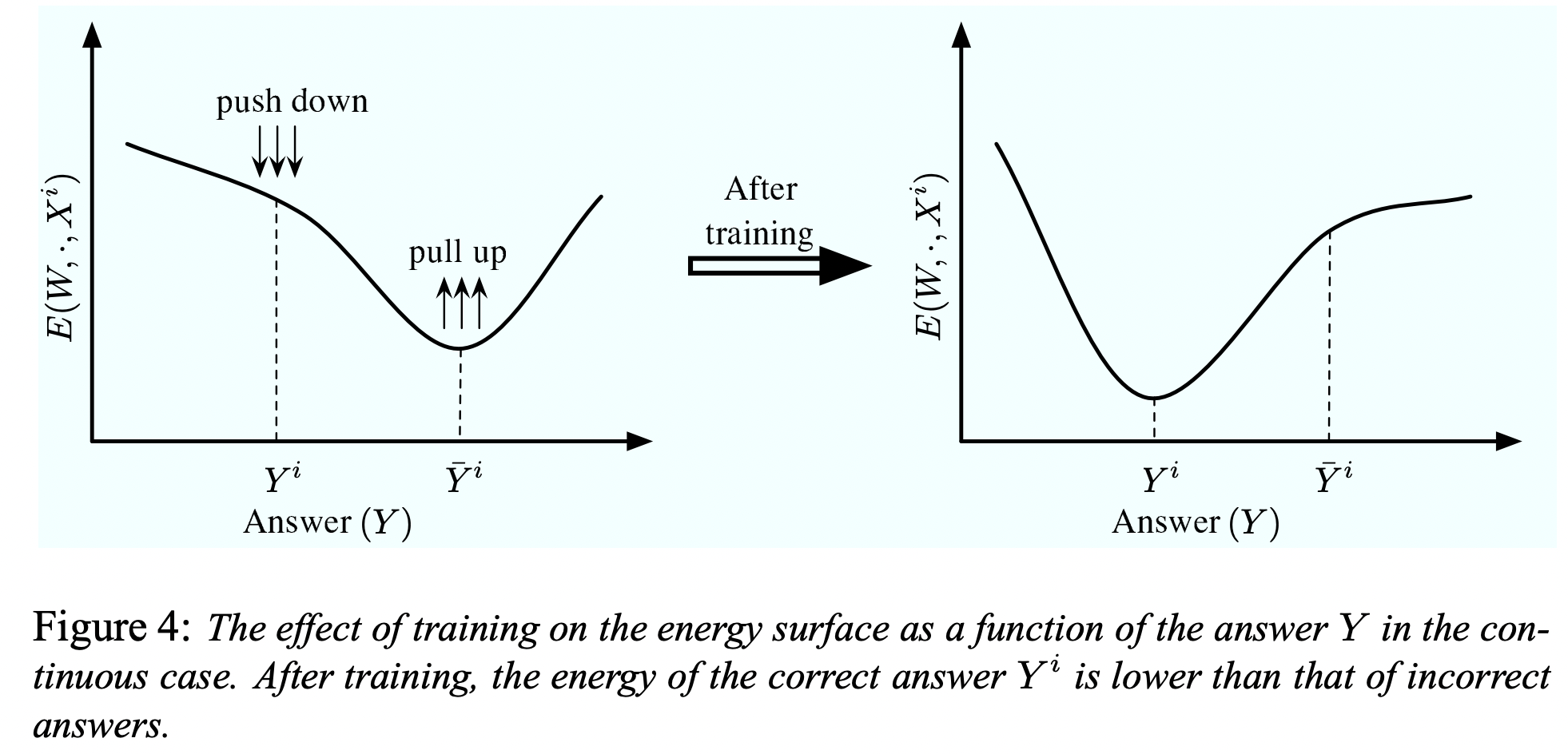
thresholding이 가능한지, 두번째나 세번째로 좋은 답을 찾을 수 있는지 (ranking)등 다양한 조건이 있을 수 있다. Collapse of Energy: 경계해야 할 것 중에 하나가 energy가 collapse 되는 것이다. 이것은 energy surface가 flat하게 되고, 어느 데이터 포인트에서나 값이 zero가 되는 현상을 말한다. 즉, 틀린 페어에 대해서 높은 에너지가 적절히 할당되지 않는다면 모든 x, y 페어에 대해서 에너지가 낮게 배정될 수 있다.- 이 이야기는 흔히 simCLR, CLIP등에서의 infoNCE 파트 설명과 같다. contrastive learning은 반드시 negative pair에 대한 loss가 걸려야만 하며, negative pair를 위해 큰 배치가 필요하다.
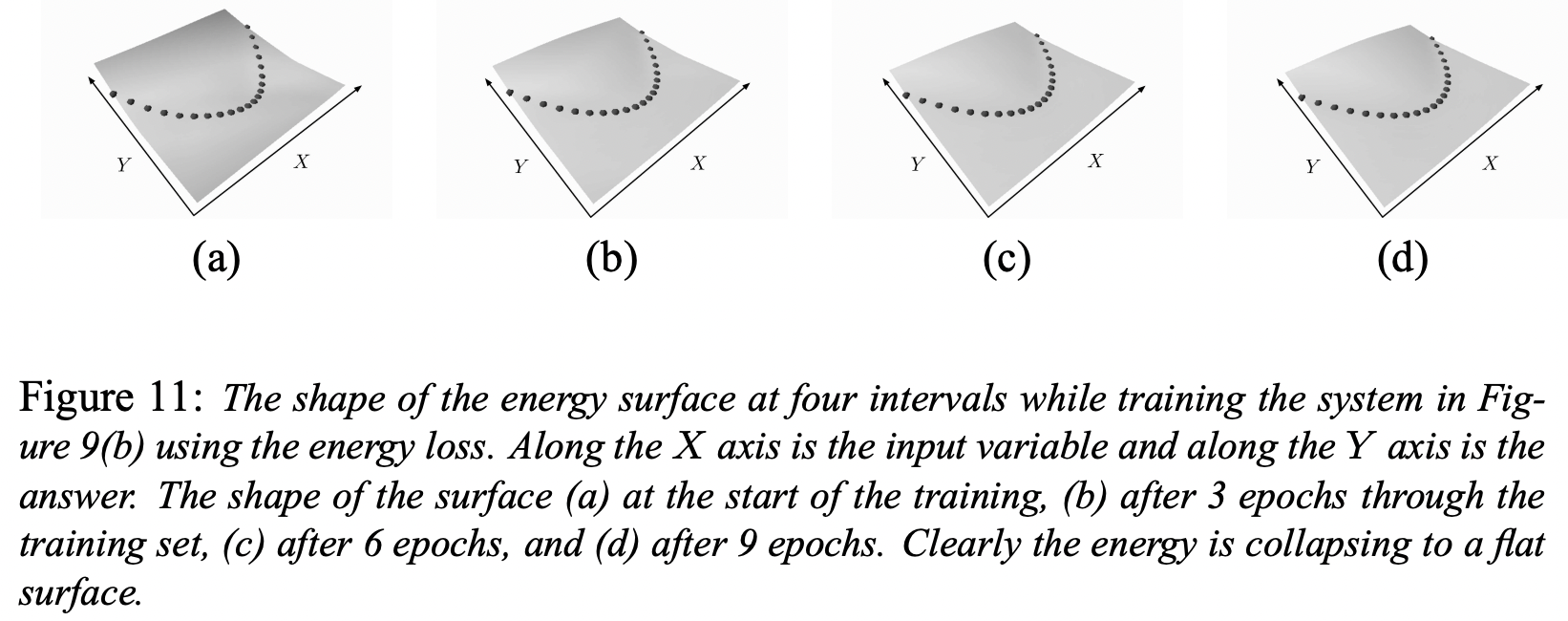
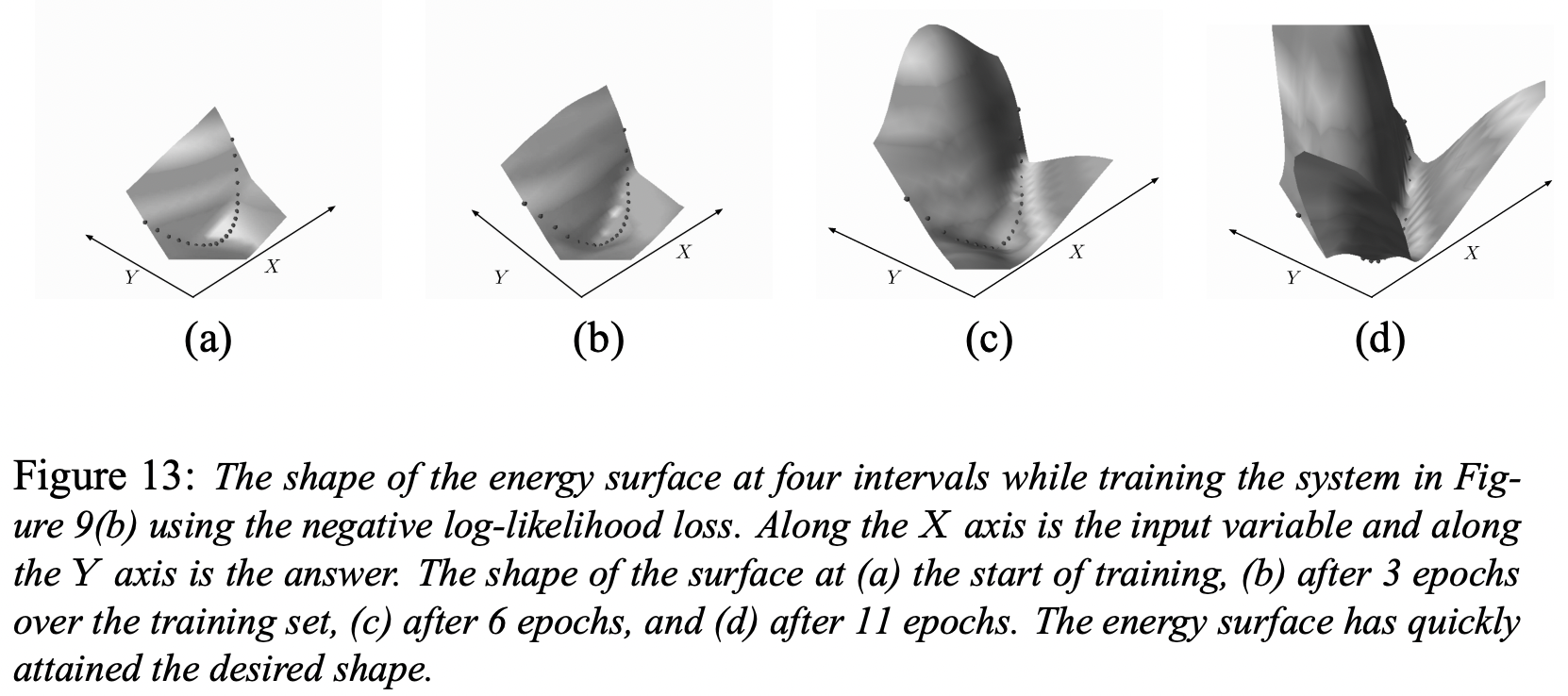
- 두 그림은 차례로 energy collapse가 일어난 케이스와 그렇지 않은 케이스를 보여준다. 후자는 NLL loss (또는 cross-entropy)를 사용했는데, 이는 collapse를 방지 할 수 있는 좋은 function이다. desired answer에 대해서는 energy를 pull-down 시키는 term과 모든 케이스에 대해 energy를 push-up 시키는 term이 둘다 존재하기 때문이다.
- 그럼 이런 식으로 EBMs에 대해서 좋은 energy function인지 측정하는 조건들을 좀더 formal하게 표현해보자.
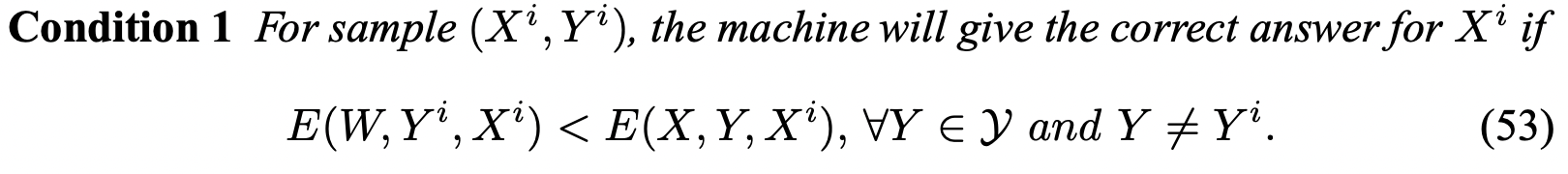
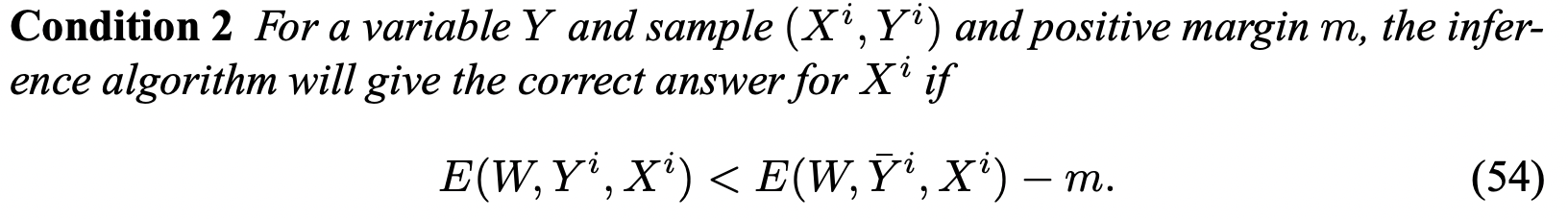

- 첫 번째 조건은, train dataset에 있는 정답쌍 () 페어의 에너지가 다른 모든 가능한 의 에너지 보다 작아야 한다는, 당연한 얘기이다. (정의)
EBM for Generative model
- EBM을 가장 직관적으로 이해하게 해준 것은 다음의 튜토리얼이었다.
- Unsupervised manner로 EBM을 코드로 구현한 다음 튜토리얼을 참고하기를 추천한다: https://uvadlc-notebooks.readthedocs.io/en/latest/tutorial_notebooks/tutorial8/Deep_Energy_Models.html
