H-CAST
0. about
- CAST는 안다는 가정하에 작성
- 벤치마크를 믿기 힘들어, related work에 집중
1. Abstract & Introduction
Hierarchical classification는 분류 트리를 예측하는 태스크: 각 레벨에서의 accuracy와 레벨 사이의 consistency 모두 중요함- 각 레벨별 classifier 학습 -> accuracy, not consistency
- finest 레벨만 학습 -> consistency, not accuracy
- 이는 레벨별로 multi-task classification으로 생각하면 안되고, 서로 타협해야한다. 우리의 insight는, semantic granuarity에 따라 일관된 segmentation을 기반으로 hierarchical recognition을 수행하는 것이다.
fine-grained recognition은fine image segmentation을,coarse-grained recognition은coarse image segmentation을 필요로 할것이라는 직관이 있다. 이에,fine-to-coarseinternal visual parsing을 수행하는 CAST를 확장해, 하나의 모델로 hierarchical recognition이 가능하다.Tree-path KL Divergence Loss제안: 레벨 사이의 consistence를 enforceFPA(Full-Path Accuracy) metric 제안 - accuracy와 consisteny 모두 측정
- accuracy 뿐만 아니라 consistency도 중요한 이유: test-time에 GT가 없을때, 특정 레벨에서 예측이 맞다고 하더라도 다른 라벨과 consistent하지 않으면 신뢰 하기가 어렵기 때문: (e.g., Ruby-throated Hummingbird - Plant)
- Why taxonomy tree challenging?: Coarse와 Fine 사이의 대결
- all-level pred 학습하는건 single-level pred 학습시에 비해 성능이 degrade
inconsistency among hierarchy classifiers: level에 따라 이미지에서 classifier가 attend 해야하는 영역이 다르기 때문
2. Related Work

2.1. Your 'Flamingo' is My 'Bird' (CVPR'21 oral)
Multi-granularity label framework제안- fine-grained classification를 single-label task에서 multi-label로 재구성
- 사전정의된 label hierarchy를 이용해서 재구성
- 이유1: practical - 설문조사를 바탕으로, 사람들이 fine-grained (expert) label만 주면 당황하지만 coarse-to-fine label을 더 선호함
- 이유2: performance - fine-grained, multi-label 모두에서 sota를 찍음.
- 실험적으로 다음과 같은 중요한 발견을 함:
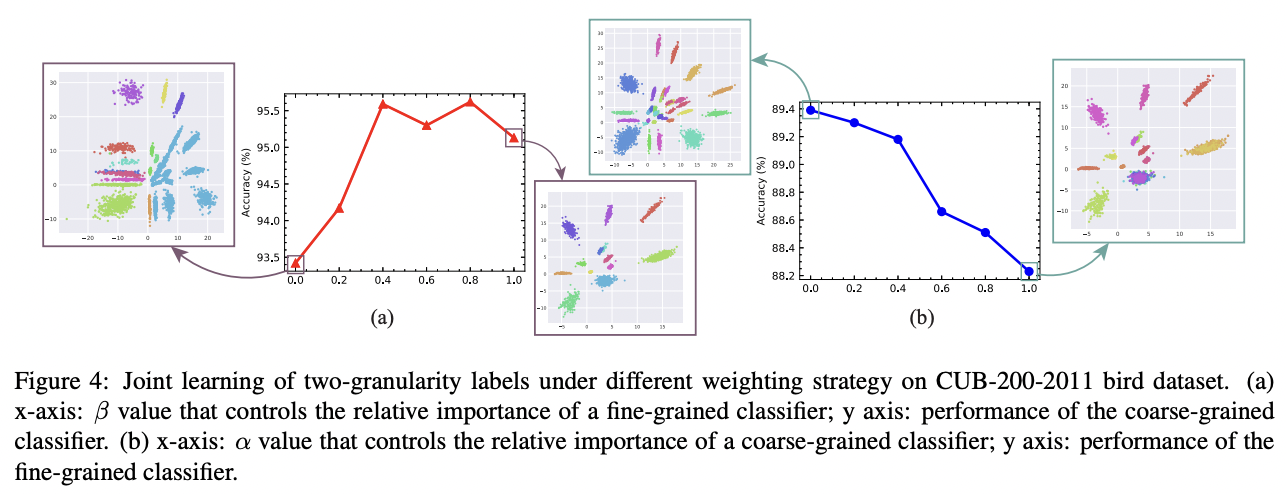
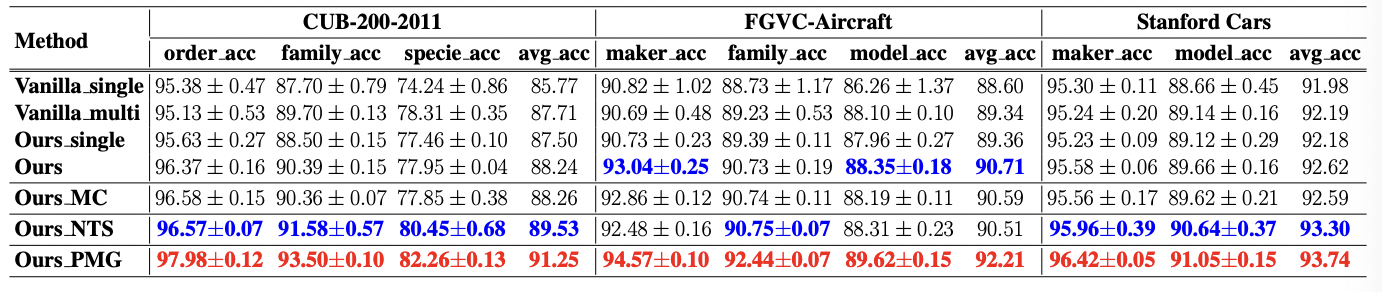
Coarse-level label prediction exacerbates fine-grained feature learning, yet fine-level feature betters the learning of coarse-level classifier.
-
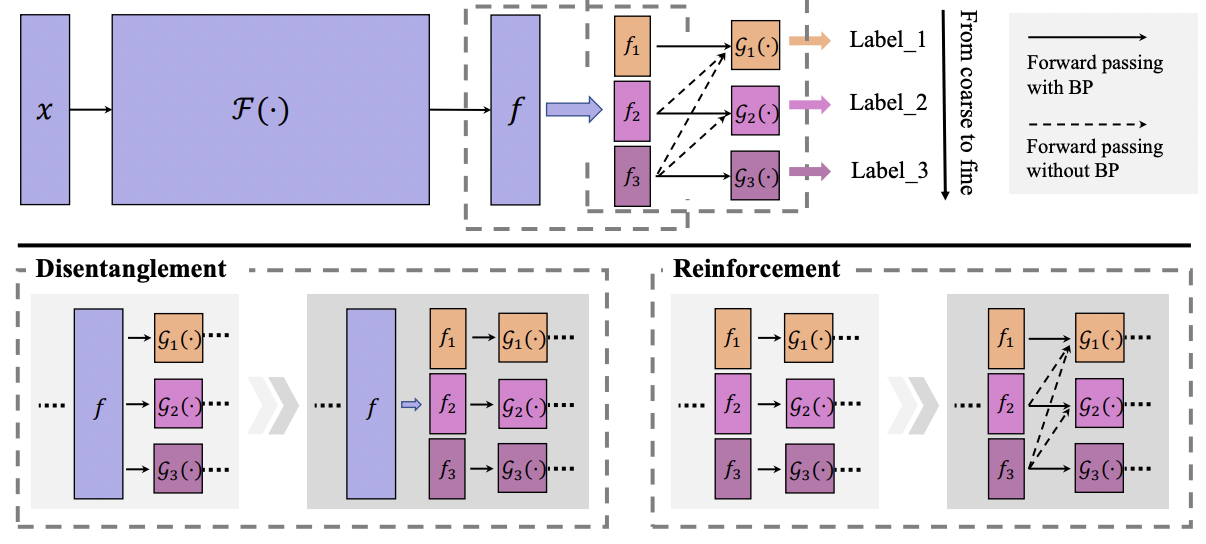
따라서 (1) level-specific classifier를 각각 두어 coarse와 fine을 distengle 하고 (2) finer-grained features가 coarser-grained prediction에 관여하게 만듬.
-
결과는 두 태스크 모두에서 기존 방법에 결합해서 sota.. 하지만 multi-label과 FGVC 성능 차이가 왜 이렇게 많이 나는지는 미스테리... image resolution 문제인가..?? 정답
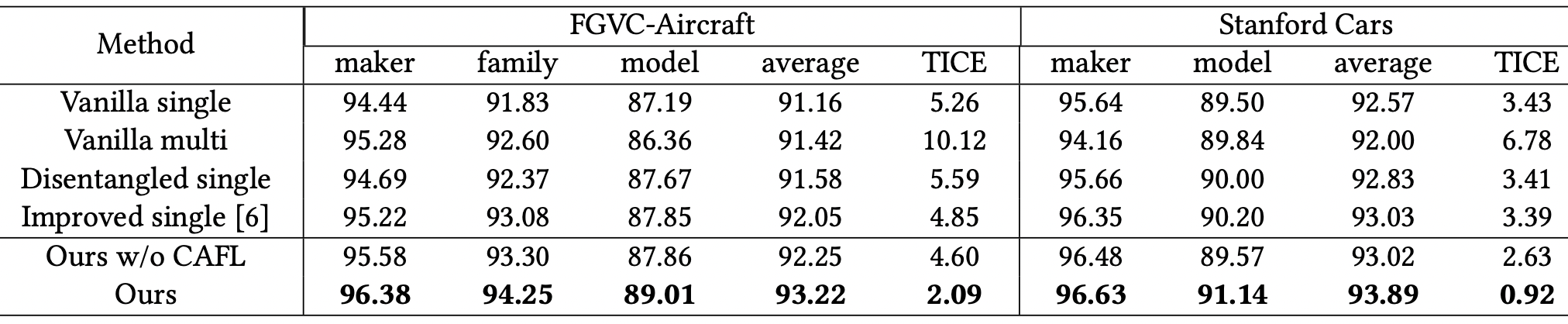
2.2. CAFL (ACM'23)
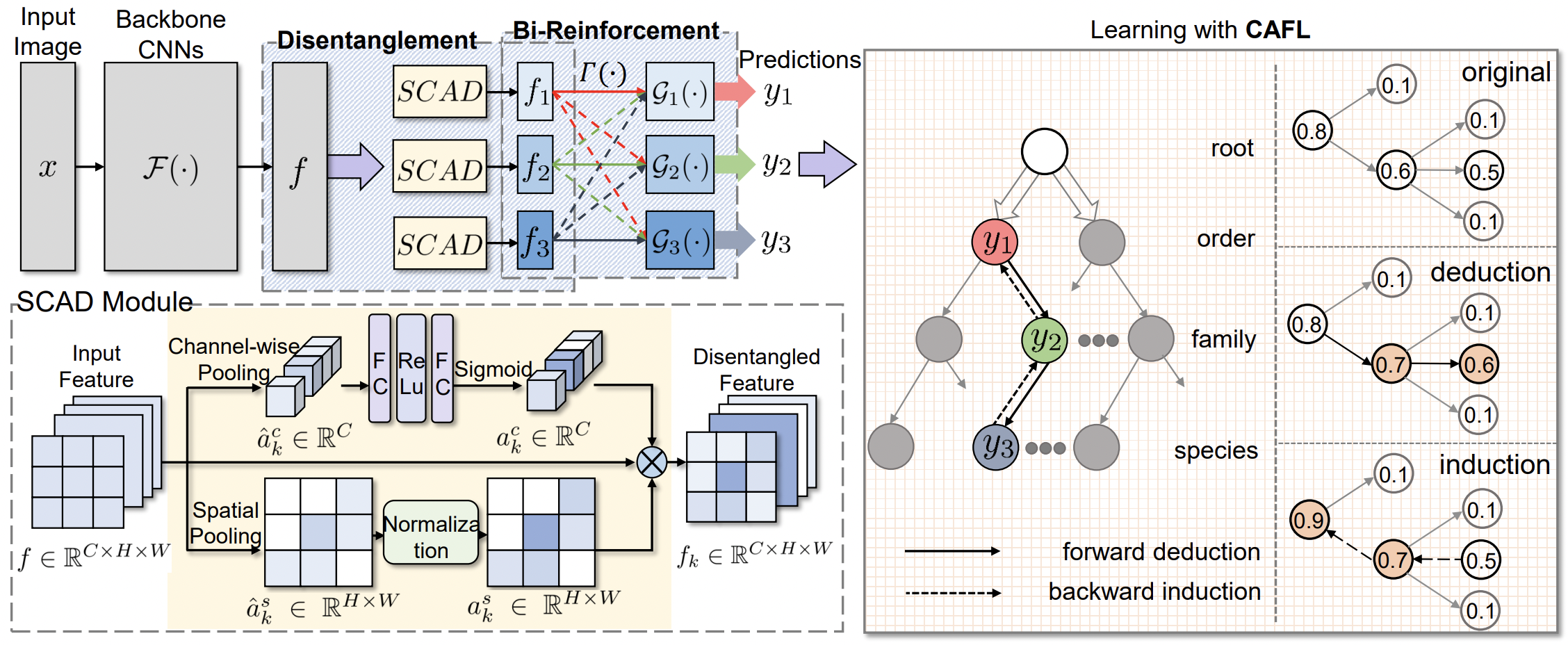
- CAFL은 위 플라밍고 논문의 extension임.
- SCAD 라는 모듈로 그냥 feature를 더 explicit하게 disentengle 시킴. 마찬가지로 coarse가 fine을 hurt시키는 confrontation 고려
- 하지만, reinforcement는 bi로 적용하도록 변형됨. 잘 entangle 된듯?
The global and general features are also helpful in fine-grained prediction and are utilized in many existing method.
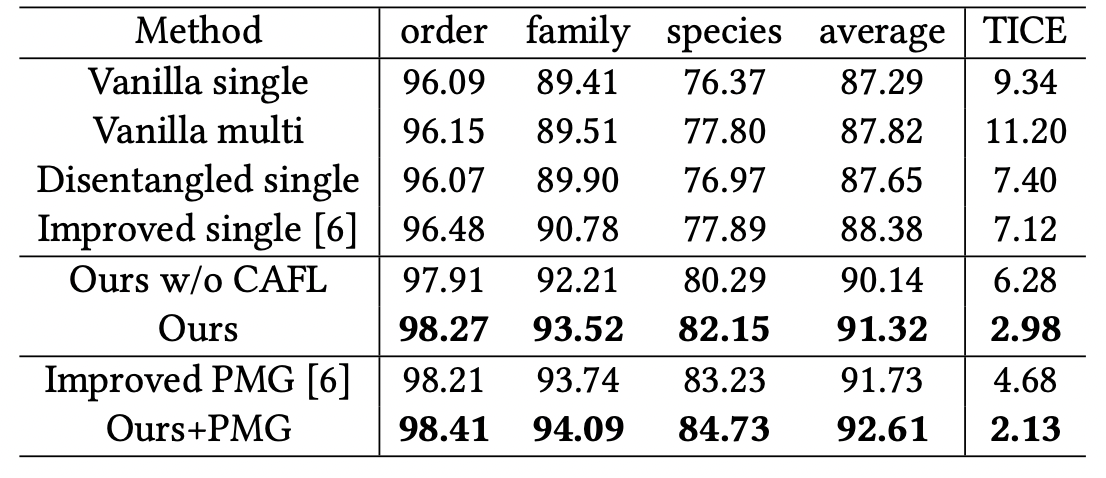
- CAFL이라는 explicit 하게 prediction을 조정하는 방법 사용: coarse-to-fine deduction + fine-to-coarse induction
TICEmetric (Tree-based Inconsistency Error Rate) 제안
2.3. 기타
- 다른 접근도 보통 레벨별로 classifier가 있고, 어떻게 효율적으로 트리 관계를 모델에게 bias로 제공할까를 고민하는 방법들임
- where-to-focus가 성능이 높은듯: H-CAST보다도 더 /
wAP제안
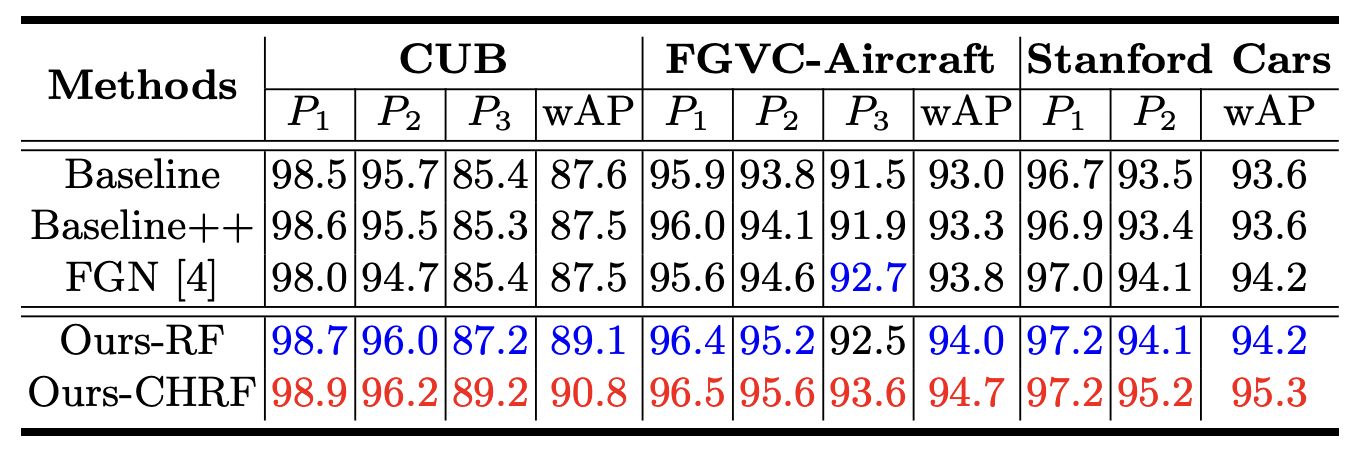
- PIM이 CUB SOTA임. Swin-T로 이룬게 놀라움 ㄷㄷ. 22년에 나오고도 더 이상 개선되지 않는거 보면 더 이상 풀 이유가 없는 태스크 같긴함. PIM에 graph-like 방식이 있는 것도 보임.
3. Method
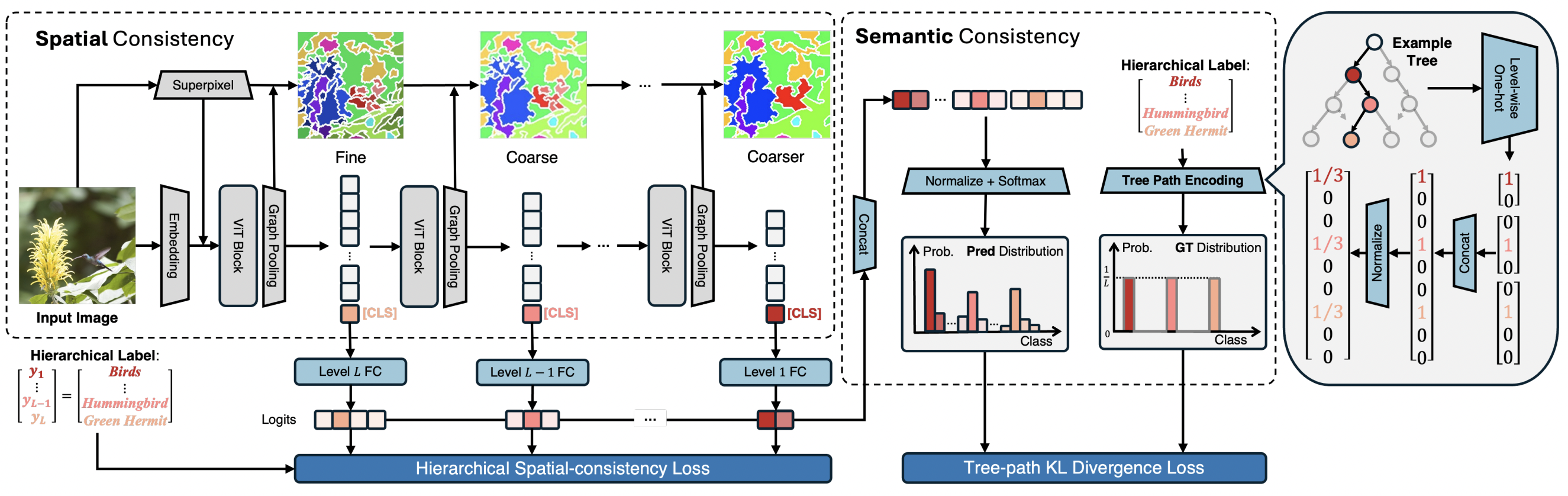
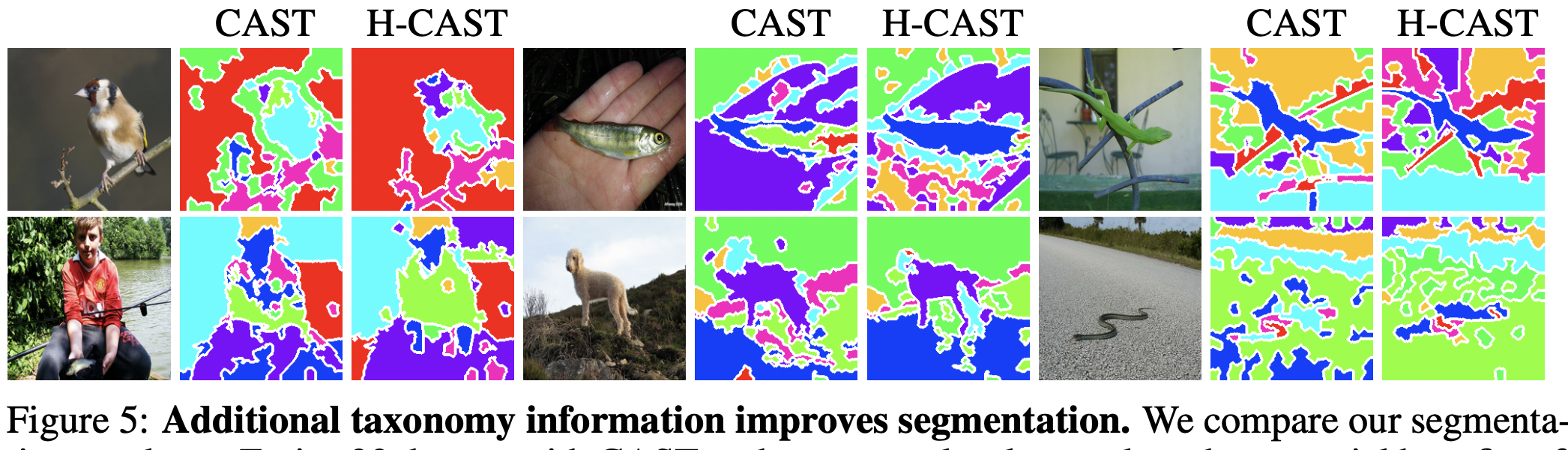
3.1. Spatial Consistency
- 그냥 CAST의 stage 별로
fine-to-coarse로 각각 예측 하도록 함. - to maintain a coherent focus during hierarchical recognition and ensure spatial consistency.
3.2. Semantic Consistency
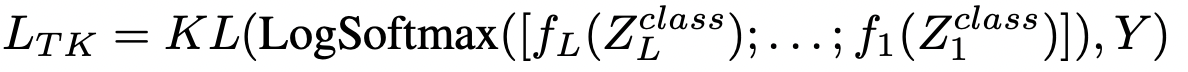
- This loss penalizes predictions that do not align with the taxonomy by simultaneously training on multiple labels within the hierarchy.
4. Experiment
4.1. Dataset
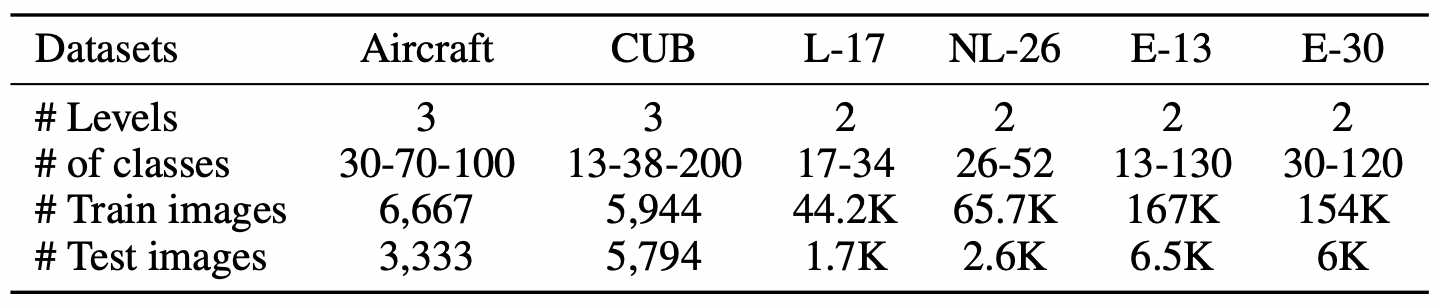
Aircraft,CUB은 fine-grained에서 유명.stanford Car은 너무 쉬운 태스크가 되서 뺐나? 생각중CUB은 원래 2-level인데, Flamingo 논문에서 3-level로 재정의함 (38)- 뒤 4개는 ImageNet subset인
BREED로, 상대적으로 앞 두 개 보다는 large한 데이터셋에서 보여주려고 가져온듯. wordnet 기반 hierarchy
4.2. metric
level accuracy: level별로 각각 accuracywAP: L개의 level이 있을때, 단순히 1/L로 level accuracy를 평균 내는게 아니라, 클래스 개수에 비례해서 weighted average accuracy를 구한 값. 즉, finer level이 클래스 개수가 더 많으니 그 만큼 accuracy를 많이 반영함. 꽤 괜찮은 메트릭인듯TICE: prediction이 pre-defined tree에서 가능한 경로인지를 재는 메트릭으로, consistency만 재는 메트릭임. 그러나 아래의 FPA가 있는한 사실상 필요 없는 지표에 가까움. inconsistent ratio를 재므로, 0에 가까울수록 좋은 지표.FPA: 이 논문에서 새로 제안한 메트릭. 그냥 모든 레벨에서 제대로 맞췄으면 맞다고 측정해주는, 사실상 이 태스크를 가장 잘 설명하는 하나의 메트릭인듯.

- 물론, FPA 하나로만 모델 성능을 완전히 평가할 수는 없음. FPA는 아쉽게 틀린것과 완전히 틀린 경우를 구별하지는 못하니 <- level accuracy나 wAP에 드러남.
4.3. Result
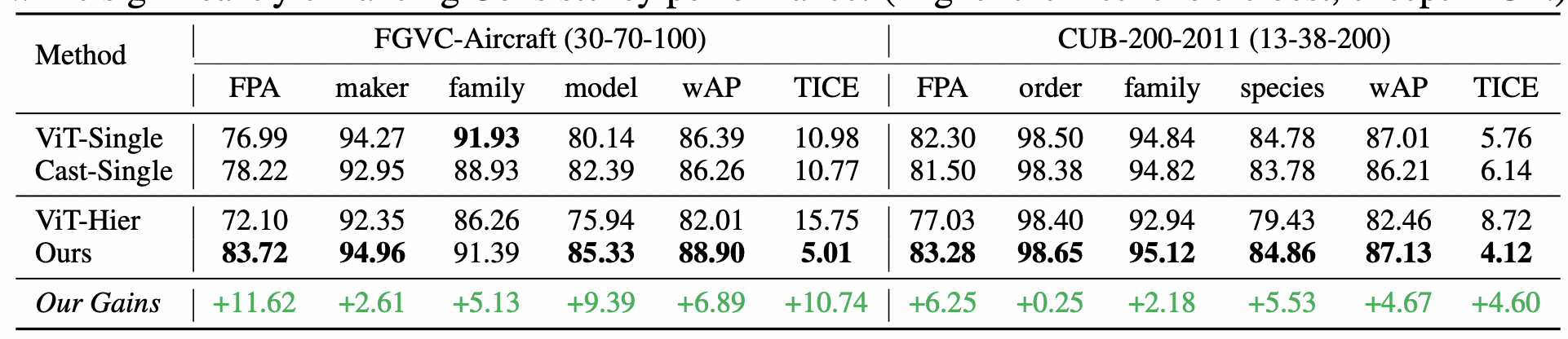

- ViT랑만 비교한게 아쉬움. (where-to-focus 한테 짐)
- iNaturalist 결과? 정말 resnet-152보다 4%나 낮은 65.5%인지?
- single은 레벨별로 각각 모델을 학습 시킨 것이라고 함. 따라서 베이스라인의 celing performance라고 볼 수도 있음. (cooperate vs confrontation ?) 각각의 성능이 높더라도 결국 consistency가 낮음 (하지만 각각 성능이 굉장히 높다면 consistency가 높을 수도..?)
- ViT-single 결과가 믿기 힘듬. CUB-species의 성능이 84.78인데, 너무 낮음. ViT-S 모델을 224로 쓴게 성능 드랍의 주 원인으로 보임. 좀 더 확인할 필요는 있을듯. 정말로 448이 중요한 키 일지도?
- ViT-Hier에서 성능이 떨어진 이유: confrontation
- 확실히 SOTA 찍기 보다는 ViT와의 차이점, consistence segmentation 등의 차이만 비교하려고 한 느낌이 강함.
- BREED 결과는, imagenet subset이라 그런지 둘다 from scratch에서 실험 - pre-trained weight가 없을때도 our method 우월성 보여줌.
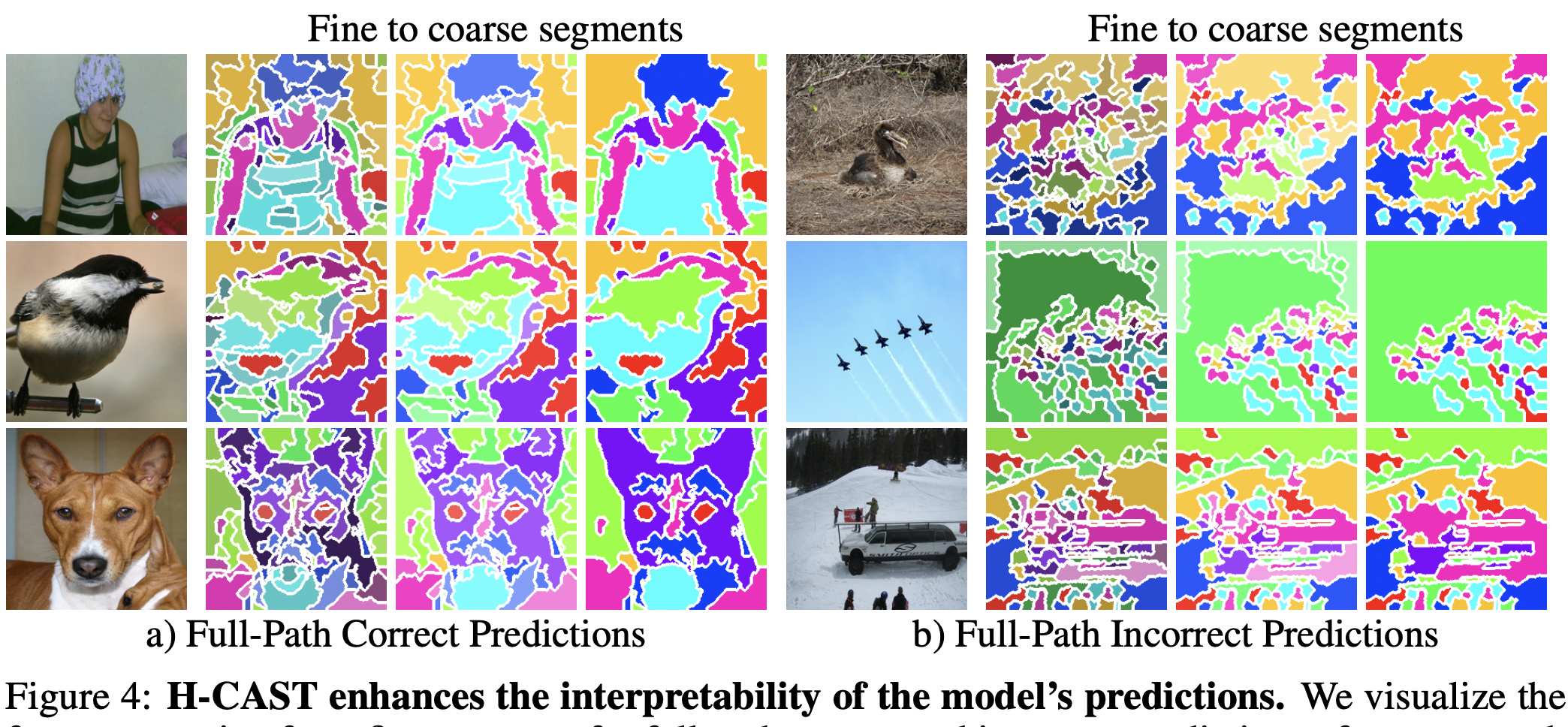
- 질문: H-CAST식 학습을 완료한 이후에, deployment시에는 finest 예측만 수행하고, 역추적하는게 성능이 가장 높고 빠르지 않을까 ??
5. Fine-to-Coarse VS Coarse-to-Fine
- 전통적인 CNN은, 초반 블럭에서 Coarser를 배움
- 이와 다르게, H-CAST는 초반에 fine, 후반에 coarse를 예측함. 따라서 뭐가 우월한지 테스트해봄
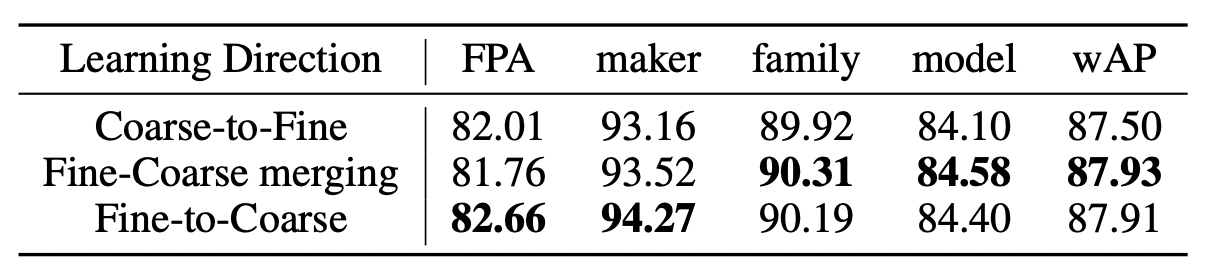
- 내가 아는 상식과 달라 혼란 스럽지만, 다음과 같은 이유를 주관 추측중.
- Flamingo에서 말한 것 처럼, Coarse feature은 fine prediction을 hurt 할 수 있지만, fine feature은 Coarse feature에 긍정적인 영향을 줄 수 있음. H-CAST 구조는 fine은 Coarse에 영향을 주지만, Coarse는 fine에 영향을 주지 않음.
- 이 말은 즉, 어쩌면 "ruby-throated humming bird"를 맞추는데 있어서 모델이 이것이 "bird"인지 아닌지 파악하는게 중요한게 아니고, 핵심 cue의 단서로만 추측하고 있는 것임일 수도 있음. (빨간 목 부분만 보고 작은 cue에 오버 피팅?)
- 동시에 학습 단계에서, 초반 블럭은 모든 라벨의 supervision이 전부 전달됨. 즉, "ruby-throated humming bird"를 맞추기 위해서 학습 되지만, 동시에 'bird'의 확률을 높이기 위해서도 학습이 되는 것임. 따라서 초반 블럭 (ViT 블럭 5개 통과) 한 상태에서도 이미 fine한 prediction에는 충분한 블럭 수 였을 수도 있음.
- 그렇다면, top-down information이 생각만큼이나 유용하지 않을 지도 모름 ㅜ
- top-down이 제대로 쓰이려면, genuinely하게 understanding하는 large model에서 더 유용할지도 라는 생각이 듬 ㅠㅠ.
6. 기타 특징