0. 리뷰 이유
- Feed-Forward GS모델중에 GS param을 input으로 직접 업데이트하는 방식중 하나여서
- 최신 모델인 Mamba를 채택한것두 매력포인트; 많은 량의 가우시안 처리 가능; O(n)
1. GAMBA 요약: abstract & introduction
- 풀고자하는 문제: how to immediately generate 3D Gaussians, effeciently?
- e.g., transformer-based: 3DGS requires lots number, but quadratic
- i.e., end-to-end feed-forward single image to 3D reconstruction model
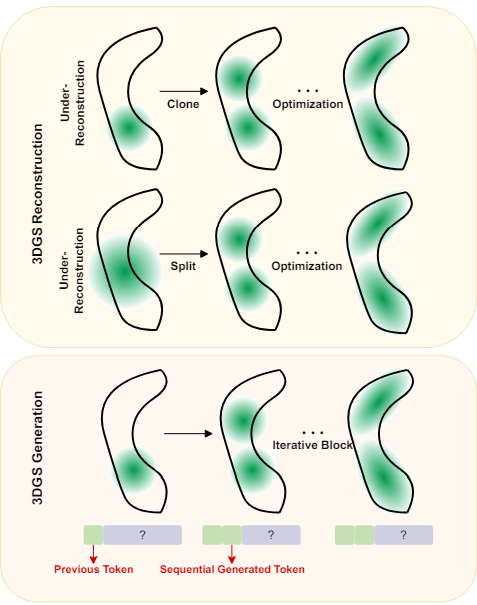
- densification과정을 sequential prediction으로 conceptualized함 -> Mamba
- (1) GambaFormer사용: linear time scailability: 많은 수의 gaussian 처리
- (2) Robust Gaussian Constraints
- 0.05s 시간에 3d reconstruction (1000x)
- Gamba is trained on 16 NVIDIA A100 (80G) GPUs with a batch size of 256 over
approximately 40 hours for totally 400 epochs
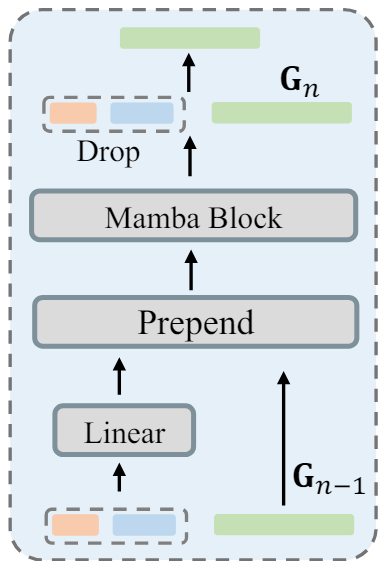
- GambaFormer의 input token은 3개의 token으로 이루어져 있다.
- C=768?, D=512, K=576, H,W= 512, p=8, L=16384,
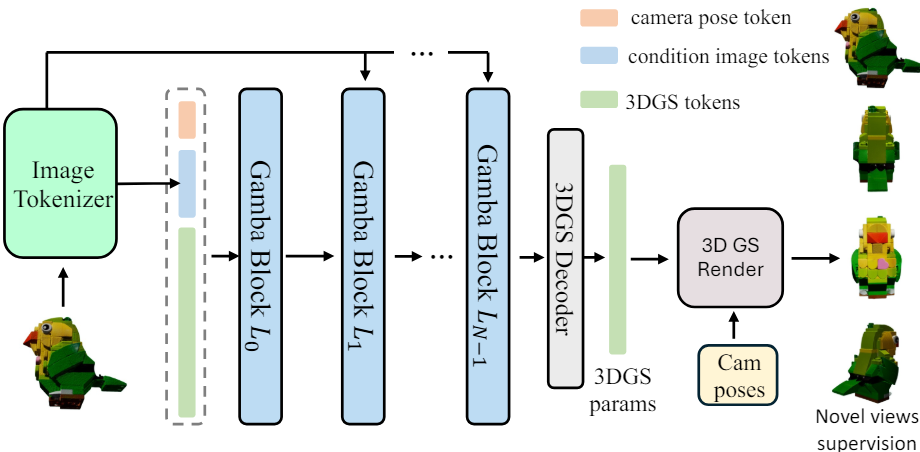
3.1. Condition image tokens X (K x C)
- input image를 Image Tokenizer(=DINOv2 ViT)로 sequence of tokens(K x C)로 만듬
- DINO는 LRM에서 잘 동작했기 때문에 사용하였음
3.2. Condition camera tokens T (1 x C)
- LRM에서 했던 것 처럼, camera features가 들어가야한다. (single에서 왜..??)
- camera extrinsic 12 param(rotatation, translation) + camera intrinsic 4 param
- MLP (16->C)를 통해서 채널 C의 단일 토큰을 만듬
3.3 3DGS tokens G (L x D)
- linear complexity 덕분에 long sequence 가능 L = 16384
- camera pose와 image 각 픽셀을 뭔가 해서 Conv를 거쳐서 feature map을 만듬
- 위 feature map을 4가지 scan 방식으로 flatten함 : L = 4 x h x w = 4 x (H/p) x (W/p)
- learnable embeeding(L x D)를 더해 최종적으로 G (L x D)를 얻는다.
- N=14의 Gamba block이 stack됨

- 그림과 수식대로, condition token은 각자 Linear layer (P)를 통해 C차원에서 D차원으로 변환된다. 그러면 G랑 차원이 맞아서 그대로 앞에 추가(prepend) 할 수 있다.
- prepend이후에 (1+K+L)xD의 토큰들은 Mamba연산(M)을 진행한다.
- Drop은 그냥 prepend시킨 condition token들을 치워주는 거다;;
- 그냥 G를 업데이트하는데 있어서 cross-attention이 아닌 방식으로 넣었다 뺏다 하는 느낌
5. Gaussian Decoder