[논문리뷰] Instant Continual Learning of Neural Radiance Fields
1. Abstract & Introduction
- 기존의 NeRF들은 scene optimization을 위해서 모든 training view에 동시에 access 해야한다. 하지만, 그런 방식은 새로운 view가 지속적으로 추가되는 환경 (real-world 로봇 어플리케이션)에서는 불가능하다.
- 그냥 NeRF를 새 이미지가 들어올때마다 naive하게 추가 학습시킨다면?>
catastrophic forgetting 때문에 기존의 knowledge가 깨져버린다.
- 이 연구는
replay-based 방식으로 NeRF를 continual learning 하는 프레임워크를 제시한다. + explicit, implicit의 hybrid representation과 함께
replay-based: previous task에서의 정보를 어떠한 형태로든 저장해서 이어지는 태스크를 학습할때 이 정보를 활용하는 방식 -> 이걸 NeRF에 적용한 선행연구는 메모리와 시간이슈가 있었음 -> 새로운 적용방식 필요- 키 아이디어: "학습된 NeRF 자체가 이전의 모든 images들에 대한 compressed representation이다" -> 즉, 이전 태스크까지 학습된 모델을 copy해서
oracle로써 pseudo GT RGB값을 querying할 수 있다.
- 또한, decoder MLP의 크기를 크게 줄여
catastrophic forgetting을 방지하였다 <- NeRF의 frequency encoding을 multi-resolution hash encoding로 바꿈으로써
- 5s만에 새로운 view를 학습가능하다
continual learning
- partial training data is available at each stage of training - 보통 3가지 접근
- 1)
Parameter isolation: 각 태스크별로 sub-network학습
- 2)
Parameter regularization: old knowledge를 가진 중요한 파라미터를 identify해서 쉽게 업데이트 되지 않도록 regularize
- 3)
Data replay: previous task의 data를 일부 저장해서 old와 new 모두에 대해서 학습시키기
- 이 연구는 data replay와 유사하다: data가 아닌 self-distillation 활용
SLAM
- NeRF를 continual learning하는 것은 SLAM과 유사하다
- SLAM처럼 하는 NeRF는 data replay에 해당 -> data를 explicit하게 저장하는거는 메모리 비용이 크다
3. Continual Learning setting
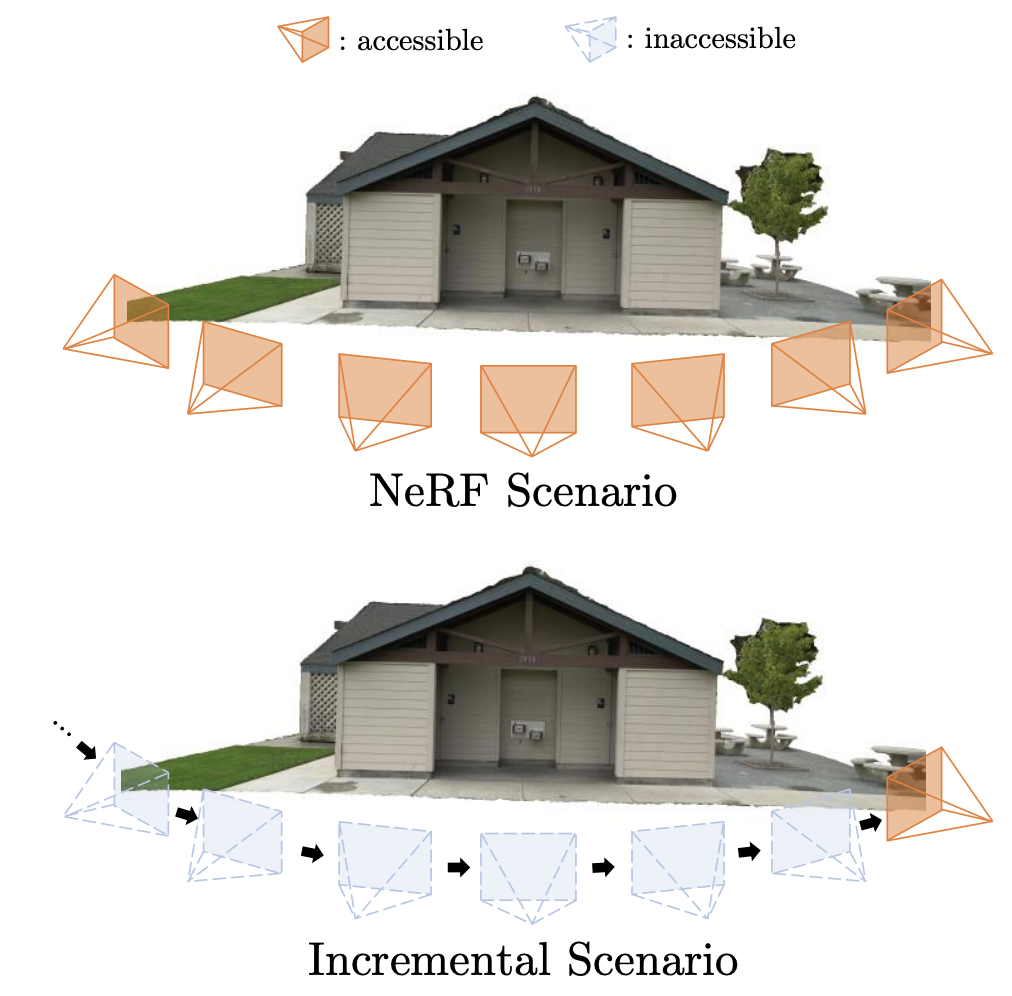
- sequential manner로 view가 들어온다. 가장 최근의 view에 (batch) 접근할 수 있지만, 그 이전의 view는 다시는 볼 수 없다.
- 하지만, 이 논문에서는 image는 접근 불가능하지만, 이전의 ray information은 접근가능하다고 가정했다 (매우 작은 메모리)
4. InstantNGP (InstantNeRF)
- InstantNGP(SIGGRAPH 2022, 2200인용)
- NVIDIA에서 연구한 memory & time efficient NGP (NeRF포함)
- 기존 NeRF는 어느 포인트를 input으로 할 때, fourier또는 positional encoding 방식을 사용한다. 이는 포인트에 대해서 비교적 풍부한 정보를 담지 못한다
- 제안한 Multi-resolution Hash Grid Encoding은 공간적으로 다양한 정보가 풍부하게 포함된 벡터를 생성한다. (높은 표현력)
- 이미 인코딩된 좌표가 고도로 풍부한 정보를 포함하기에, MLP가 배워야 할게 적어 작고 효율적인 MLP를 사용할 수 있다. (1 + 2 layer)
- 작은 MLP는 빠른 rendering속도, 빠른 학습 수렴을 유도한다.
- 심지어 5초 학습에도 어느정도 수준의 성능이 나오며, 5분 학습하면 n시간 학습한 NeRF, mip-NeRF보다 PSNR이 높게 나온다 ㄷㄷㄷ
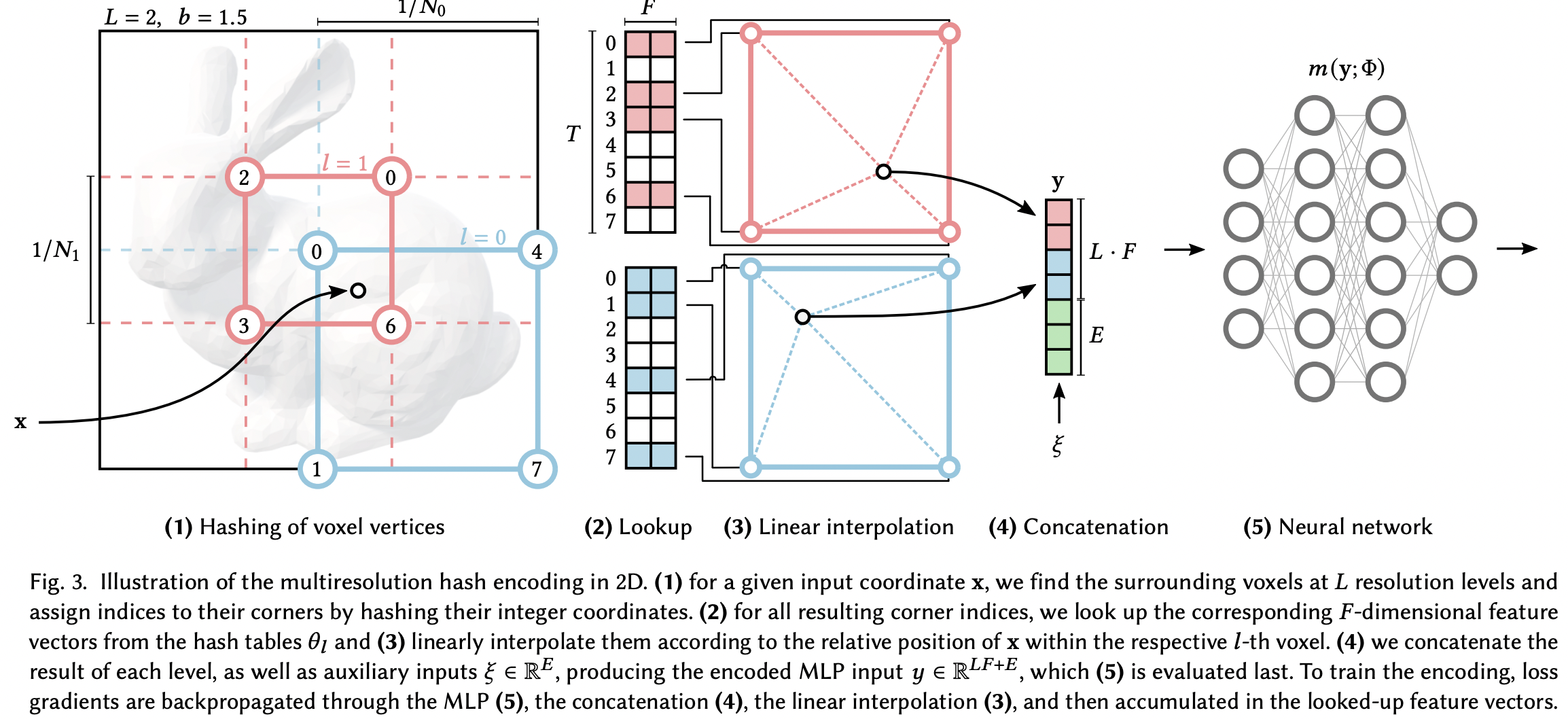
- feature encoding을 위해서 그 포인트가 속한 multi-level의 voxel로 부터, 그 해시값에 맞는 feature vector을 각각 linear interpolation한이후 그걸 concat하고 auxilary까지 concat해서 만든다.
- NeRF를 학습시키면 MLP부터 해시테이블에 value까지 학습됨
- 해시충돌이 발생할 경우, 그 포인트는 collision의 평균으로 수렴하게 된다(그래디언트가 중복 적용). 따라서 해시테이블이 클수록 smoothen되는 경우가 적어진다.
5. multi-resolution hash encoding
- InstantNGP 방식을 따라 사용했음, MLP를 크게 reduce할 수 있어 catastrophic forgetting을 완화할 수 있음.
- 이 해시테이블에 있는 feature value는 이번 view에서 해당하는 voxel이 등장할때만 업데이트(그래디언트가 전달)된다. 따라서, 적어도 feature encoding 과정은 예전에 배운 knowledge가 이번 뷰에서 등장하지 않으면 업데이트 되지 않는다는 장점이 있다!
- 마찬가지로 해시테이블이 클 수록 forgetting정도가 줄어든다.
- 음... 새로운 해석 이외의 새로운 노벨티는 없는거 같다.
6. Memory replay through NeRF distillation
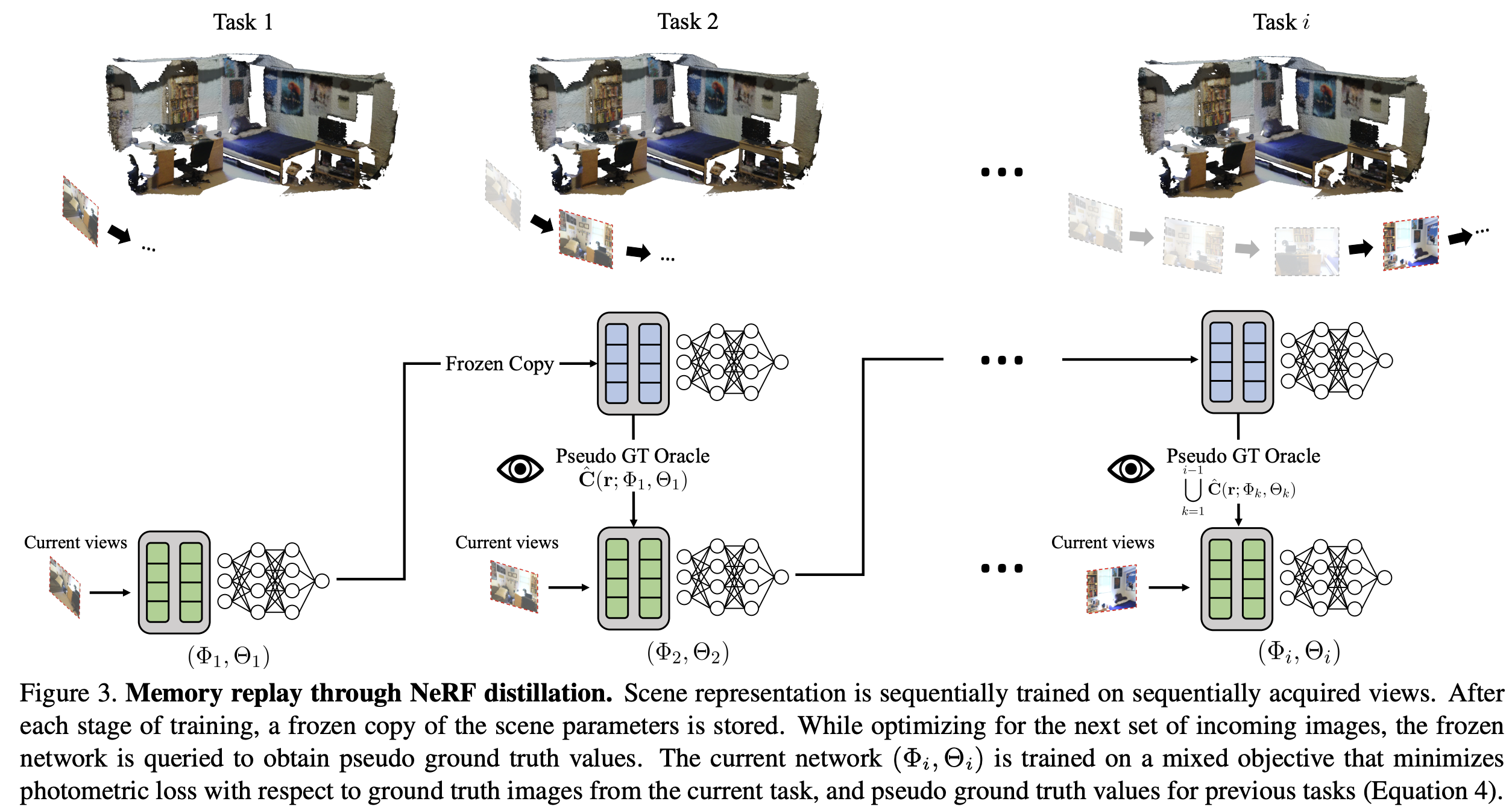
- previous data에 접근할 수 없으니, previous data를 생성하는 방식으로 학습함. 즉, 이전 태스크까지 만들어진 NeRF자체를 생성모델로 간주하고, 기억하고 있던 ray information을 기존 모델에 넣어서 나온 RGB 이미지를 pseudo GT로 사용하는 거임
- 그냥 예전에 봤던 이미지를 다시 접근 못하는 태스크지, 매번 MLP는 새로 학습시키는게 맞음. 대신 InstantNeRF가 원래 5초면 어느정도 수준의 fitting이 됬던거임 (...)
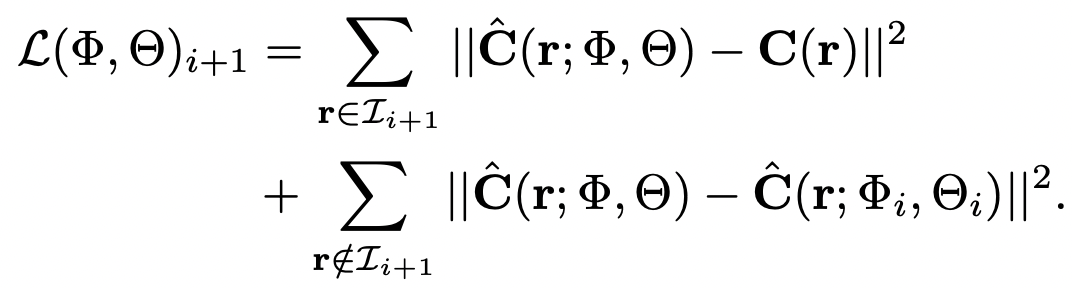
7. Experiment
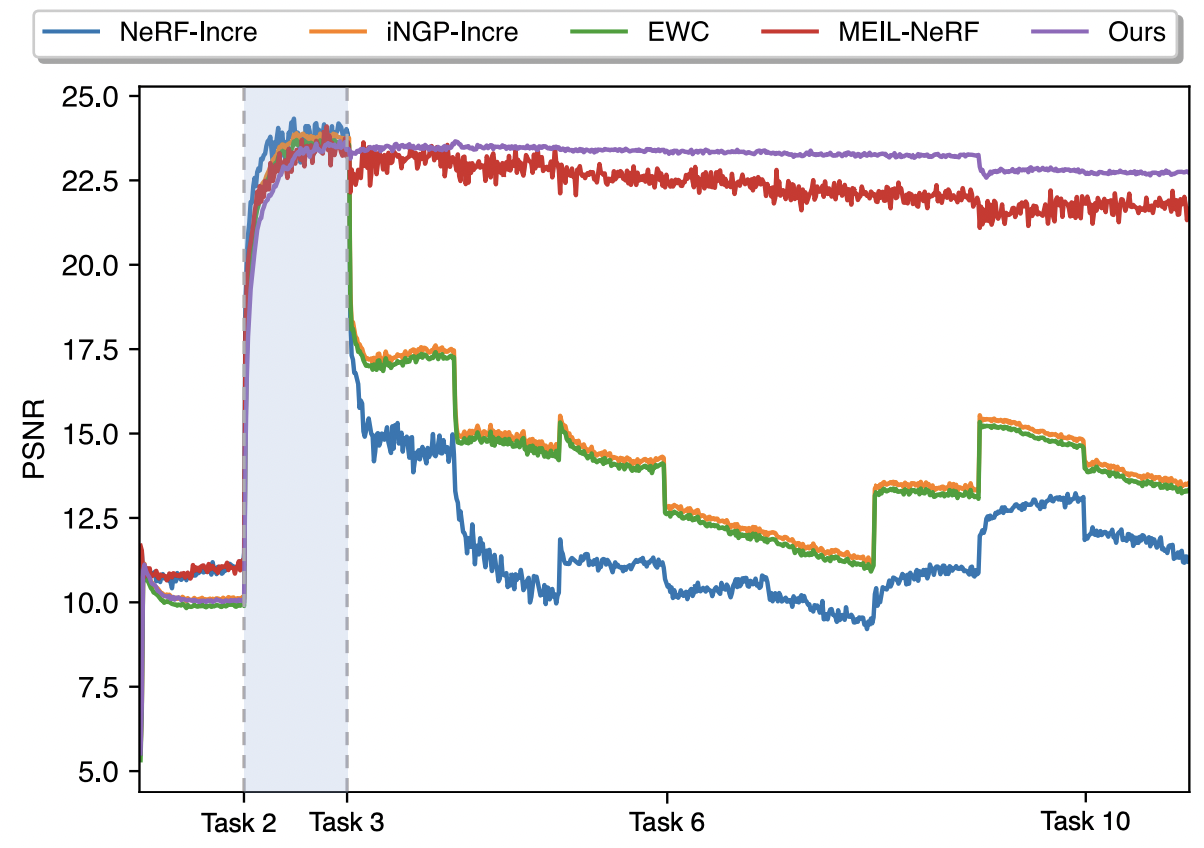
- naive한 continual NeRF나 feature regualrization (EWC) 등에 비해 월등히 좋은 성능을 보여줌
- 같은 주제를 다룬 MEIL-NeRF에 비해서도 더 빠른 피팅 시간내에서 성능이 잘나옴. 근데 얘넨 ray information도 접근안하는 세팅이라서.. 오히려 여기서 배울점이 더 많을지도..?
8. 의견
- 아... continual learning이 N개로 쌓은 지식위에 1개의 지식을 더하는 느낌인줄 알았는데.. 그게 아니고 N개의 데이터에 다시 접근 못하는 상황이고 다시 첨부터 학습하는게 continual이었구나... 물론 로봇 디바이스에 예전에 찍은 영상들을 안들고 있어도 된다는 장점은 있지만.. 그게 그렇게 무거울거 같진 않은데 (...)
- 덕분에 InstantNeRF라는 아주 중요하면서도 흥미로운 논문을 읽게 되었네요
- GS로 확장하는 방안에서.. GS는 애초에 N개로 학습된상태에서 새 이미지가 들어와도 처음부터 학습할 필요가 없는데?
- continual이 무슨 태스크인지 몰랐을 뿐, 이전 데이터를 다시 접근 못하는 세팅에서 GS를 어떻게 할 것인가는 연구 주제가 될 수는 있을듯? (얘랑 동일한 접근)
