[논문리뷰] Depth-Regularized Optimization for 3D Gaussian Splatting in Few-Shot Images
0. 리뷰 이유
- 이경무 교수님께서 교신저자인데 제목도 흥미로워서 열어봤는데 메인 figure가 보자말자 너무 잘 와닿았고 내가 가지고 있던 가려움을 긁어주는 느낌이었다.
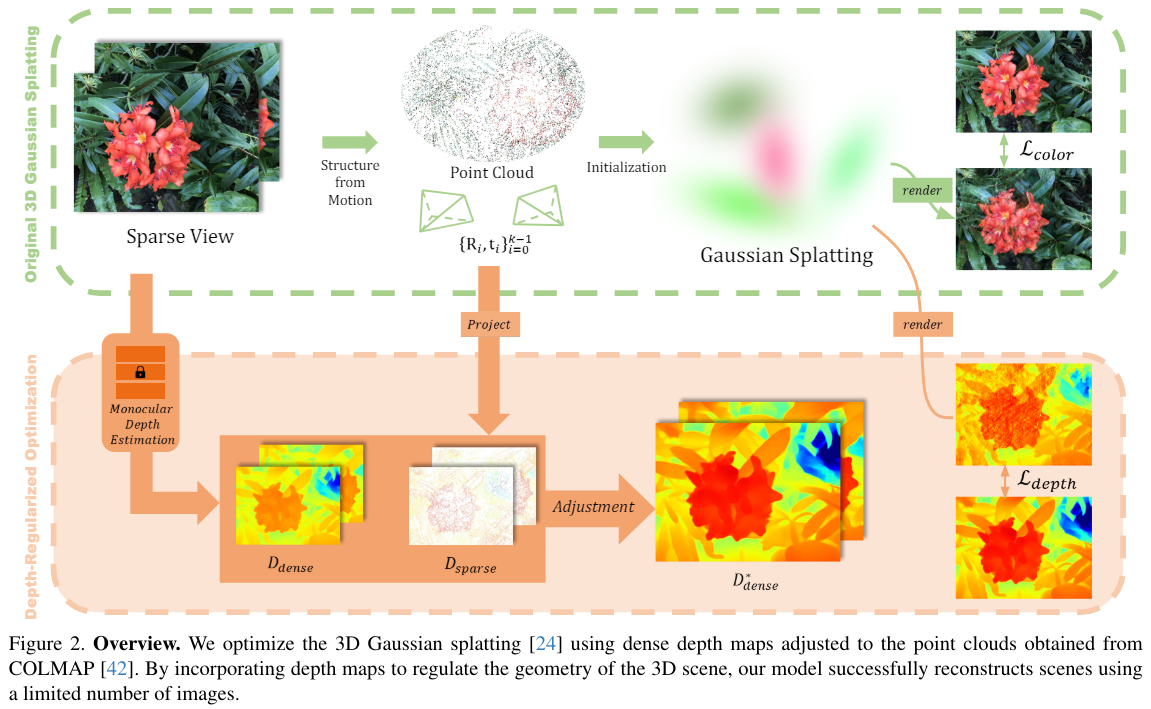
- monocluar depth estimation 결과를 이용해서 clone 할 시에 gaussian 중심을 regularize한다는 논문은 본적이 있는데(=FSGS) 그런 논문을 볼 때 그럼 그 성능의 upperbound는 deth estimation network의 성능이라는 생각이 들었었다. 또한, 성능이 아무리 개선되더라도(e.g., depth anything v2), 심지어 사람보다 성능이 아무리 좋다고 하더라도 single image로 부터 알 수 없는 깊이 정보가 있을 수 있는데, 결국 한계가 있다는 생각이 들었다.
- 그런데 이 그림처럼 network로 dense하지만 실제와 다를 수도 있는 depth maps를 구축하고, 적은 포인트밖에 없지만 비교적 실제에 가까운 point cloud로 조정을 해서 만든 dense maps는 정말로 regularization하기 적합한 map이라는 생각이 들었다.
1. Abstract & Introduction
- few-shot images만 가능한경우, GS는 training view에 overfitting되기 쉽다
- 이 연구에서는
adjusted depth map를 geometric referece로써 추가적인 unsupervised smooth constraint로 써서 해결했다. - 이 map은 pre-trained
monocluar depth estimation model의 예측결과를SfMpoints와 align해서 adjust된 map이다. - 결과적으로
floating artifacts들을 효과적으로 줄였고, NeRF-LLFF 데이터셋에서 기존 3DGS보다 robust한 성능을 보여주었다. early stopstrategy를 새로 제안한다 - depth loss가 떨어지면 학습중단?
2. related-work: few-shot 3d reconstruction
- 기존의 많은 few-shot 3D reconstruction 방법들은 depth를 cue로써 활용했다.
1. surface smoothness constraint
2. sparse depth supervision from COLMAP
3. dense depth map from additional sensors
4. dense depth map from pre-trained depth-estimation model - 이 방식들은 depth cue를 이용해서 model의 globality를 regularize하는 것이다. geometry prior가 global geometry를 보장해주는 것.
- few-shot setting에서,
strong locality때문에 3DGS는 floating artifact를 만든다. 게다가 SfM points도 적어 좋은 depth guidance주기엔 부족하다
From NeRFs to Gaussian Splats, and Back
- 본 논문에 언급된 내용은 아니지만 내가 넣은 추가

- 3DGS는 NeRF와 비교했을때, generalization을 잘 못한다고 한다(=local training views에만 overfitting되기 더 쉽다). 벤치마크에서는 둘다 성능이 좋아보이지만, 그것은 training view와 test view가 유사해서 그런 것이다. 실제로 3DGS는 training view와 꽤 다른 view에서 보면 artifact가 많이 보인다고 한다(also 융희 said). 실제로 3DGS로 depth map을 찍어보면 비합리적인 경우가 많고, few images일 때 특히 심하다. 반면 NeRF는 limited views로 더 나은 geometry를 stable하게 recover한다고 한다. (preserve depth structure)
- 저 논문에서는 SH를 예측하는 NeRF를 학습시키고 그 NeRF를 10초안에 GS모델로 변환하면 depth도 비교적 잘 추정한 (global하게 geometry가 잘 보존된) 잘 generalize된 GS를 만든다고 한다.(NeRFGS)
- NeRFGS로 다시 NeRF로 돌아가는 GSNeRF도 있다. 이러면 우선 3DGS의 큰 용량을 많이 줄일 수 있다. 또한, NeRF->GS->NeRF에서 GS 상태에서 특정 가우시안들을 삭제함으로써 특정 물체를 삭제한다면, NeRF editing 또한 가능하다.
3. Method
Overview
- 장의 few-shot setting에서 SfM으로 camera pose, point cloud를 얻는다.
- point cloud 를 각 view 에 대해 pixel space로 projection시켜 few visible points에 대한 sparse dpeth인 를 얻을 수 있다. 를 이용해 depth estimation으로 얻은 depth map을 adjust한 를 얻는다.
- gaussian을 업데이트할때, 를 이용해 geometry에 regularization을 건다.
- adjcaent pixels의 depth사이에 smoothness regualrization도 건다.
- few-shot setting을 위한 optimization option을 수정도 하였다.
최종 Loss식은 다음과 같다
1. Preparing Dense Depth Prior
- 는 를 image plane으로 projection시켜, 의 값을 가진다. density는 다양한 view의 수에 의존한다. (가령 19장으로 SfM한 경우 0.04%의 valid pixel을 커버하기도 한다)
- monocular depth estimation model을 라고 하자. (ZoeDepth)
- train image 에 대한 depth map 를 adjust한 값을 이라고 둘 수 있다. 는 scale factor, 는 offset 이라고 했을때,
- SfM point들로 depth guidance를 받아, 최적의 , 값을 결정한다.
- SfM point 대해서, 는 그 point의 SfM 신뢰도 이다. SfM reprojection error의 역수로 계산되는 값이다. 즉, 가 낮은 point 에 대해서는 좀 덜 중요하게 추정해도 되는 듯 하다. (..?)
- 이 해를 푸는 방법은 논문에 없음. GD인지 grid search인지 matrix solving인지
- 결국, 를 regularization에 활용한다.
- sfm guidance로 depth map의 scale ambiguaty를 해결한다고 주장한다. object사이에 뭐가 앞이고 뒤인지 구별되는 상황에서 상대거리 -> 절대거리로 바꿔주는 느낌인듯. 단순히 두 스칼라로 조정하는 것이니 SfM에 온전히 의존할 수 없고 결국 depth estimation model의 성능이 중요할 듯 하다.
2. Depth Rendering through Rasterization
- 각 뷰마다 rendered depth 를 L1 Loss로 로 regularize한다.
- 그러면, 현재 gaussian들로 view 에 대해서 rendered depth map 는 어떻게 구할까?
- NeRF에서 depth implementation에서 영감을 받아, 다음과 같이 계산. 원래 image rendering 공식에서 color 를 depth 로만 바꾸고, normalize한 것임 (분모파트)
- 여기서, 는 -th 가우시안의 중심과 -th camera의 image plane 사이 거리임.
- normalize 이유? - 부족한 수의 primitives 때문에 integration이 제대로 이루어지지 않았을 수도 있기에
- 이 Loss가 geometry의 guidance를 제공해서 overfitting을 완화한다.
3. Unsupervised Smoothness Constraint
- 가 아무리 COLMAP으로 조정되었다고 해도, multi-view consistency에서 (특히 detailed areas에서) conflict를 이끌 수 있는 rough guide이다
- Unsupervised monocular depth estimation with leftright consistency(2017)에 영감을 받아,
geometry smoothness를 위한 unsupervised constraint를 제안Points in similar 3D positions have similar depth on the image plane
- 이웃한 픽셀끼리는 둘 중 하나가 edge가 아닌 이상 비슷한 depth를 가져야 한다는 믿음으로 smoothing. 현실과 완벽히 align되지는 않지만, 효과적인 regularization이라고 한다.
Canny edge detector를 이용해서 edge를 찾고, 두 픽셀 가 모두 edge에 없음을 로 나타낸다. 그럼, 모든 pixel 와 그 주변의 pixel 에 대해서
4. Modification for Few-Shot Learning
- SH의 maximum degree를 1로 세팅했다 - few-shot에서의 부족한 정보가 high frequency 영역을 담당하는 SH coefficients가 오버피팅되는걸 방지하기 위해서
- moving averaged depth loss를 학습 종료로 사용했다 - color loss에 overfitting되는 것이기에, splat이 depth guide로 부터 deviate하면 오버피팅이 시작된다는 신호로 알고 학습을 종료한다.
- opacity reset 과정을 삭제했다 - 정보가 부족한 상황에서 opacity reset은 local optima에 빠지거나 모든 splat이 삭제되도록 만들 수 있다.
4. Result
qual

음 그렇다!
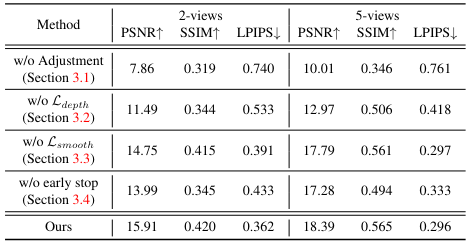

- 아래 테이블은 차례로 PSNR/SSIM/LPIPS를 2-3-4-5 view로 나타낸 것임.
- (row1) depth loss를 거는 와중에 adjustment를 하지 않으면 성능이 처참하다. depth estimation과 COLMAP사이의 misalignment는 학습을 완전히 망가뜨린다고 한다.
- (row2) depth supervision 없이 smooth loss만 거는것은 딱히 성능이 좋지 않다. 5-view 기준으로 baseline보다 성능이 낮게 나왔다.
- (row3) smooth loss도 추가적인 geometry cue로써 성능 향상에 유의미한 기여를 한다.
- (row4) early stop이 내 생각보다 성능에 영향을 많이 주었다. overfitting이 진짜 심각한 문젠가보다.
- oracle; - estimated depth 대신에 전체 train과 test이미지로 optimize한 pseudo GT depth map을 사용한 경우. oracle과 비교함으로써 precise depth의 중요성을 강조하려고 했음.
