개선 배경
저번 글에서는 쿼리 개선 전에 다른 병목을 제거한 최적의 설정을 찾았다.
결과적으로 Tomcat 스레드 풀의 크기를 100, HikariCP의 풀 크기를 40으로 설정하기로 결정했다.
평균 응답 시간은 위와 같이 1.4초로, 꽤나 개선되었지만 여전히 사용자가 체감하기에는 느리다.
또 다른 병목의 원인
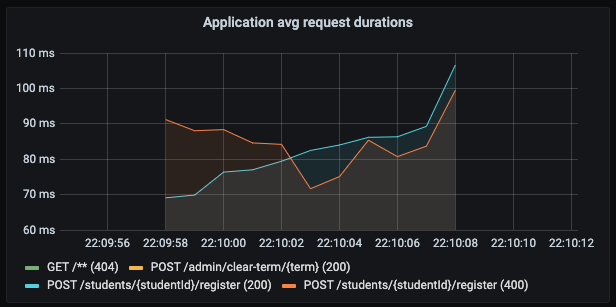
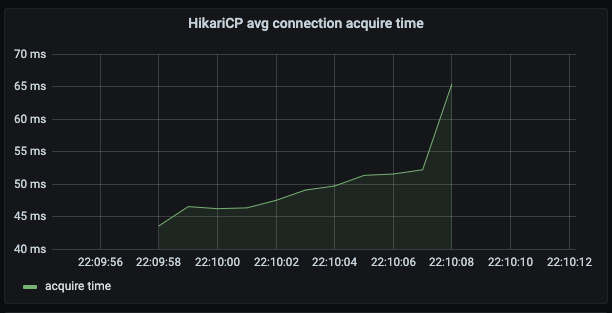
서버 애플리케이션 측 응답 시간은 여전히 빠르다.
허나 이는 병렬화에 관한 문제로, 하드웨어 성능을 더 이상 높이기는 어렵다. 금전적인 문제가 생기기 때문이다.
또 다른 방법으로 수평적 확장이 있을 수 있다. 그러나 이 역시 새로운 인스턴스를 빌려야 하므로 돈이 든다.
사실 자원이 부족하더라도 응답 시간을 개선할 방법은 여전히 존재한다.
문제의 원인이 부족한 병렬 작업이기 때문에, 서버 측 응답 시간을 조금만 개선해도, 수 많은 요청들이 그만큼 덜 기다리게 된다.
따라서 클라이언트 측 응답 시간이 크게 향상될 수 있다는 것이다. 이러한 사실은 저번 글에서 풀 크기 튜닝을 거치면서 배웠다.
그래서 이번엔 애플리케이션 로직을 개선해보기로 한다.
가장 먼저 문제가 될 수 있는 것은 역시 DB Connection이다. 여전히 요청 처리 시간의 많은 부분을 DB Connection 획득에 사용하고 있다.
이를 완화하는 방법으로는 풀 크기 튜닝도 있지만, 이번에는 보다 근본적으로 접근해서, DB에 보내는 쿼리를 최적화해보고자 한다.
MySQL Slow Query Log 활용하기
쿼리 개선에 앞서, 문제가 될만한 쿼리를 확인할 방법을 찾아야 했다. 실시간으로 SQL 별 실행 시간을 측정하고 시각화하는 방법이 필요했다.
MySQL의 공식 문서를 읽어본 결과, 최신 버전에서는 모두 Performance Schema의 테이블로 관련 기능들이 병합되었고, 시각화하기 위해서는 이 테이블의 데이터를 가공해야만 하는 것으로 보였다.
그러나 이 기능은 굉장히 로우 레벨을 다루고 있고 익숙해지는 데에 시간이 걸릴 것 같았다. 내가 필요한 기능은 그저 쿼리 실행 시간에 대한 통계일 뿐이다.
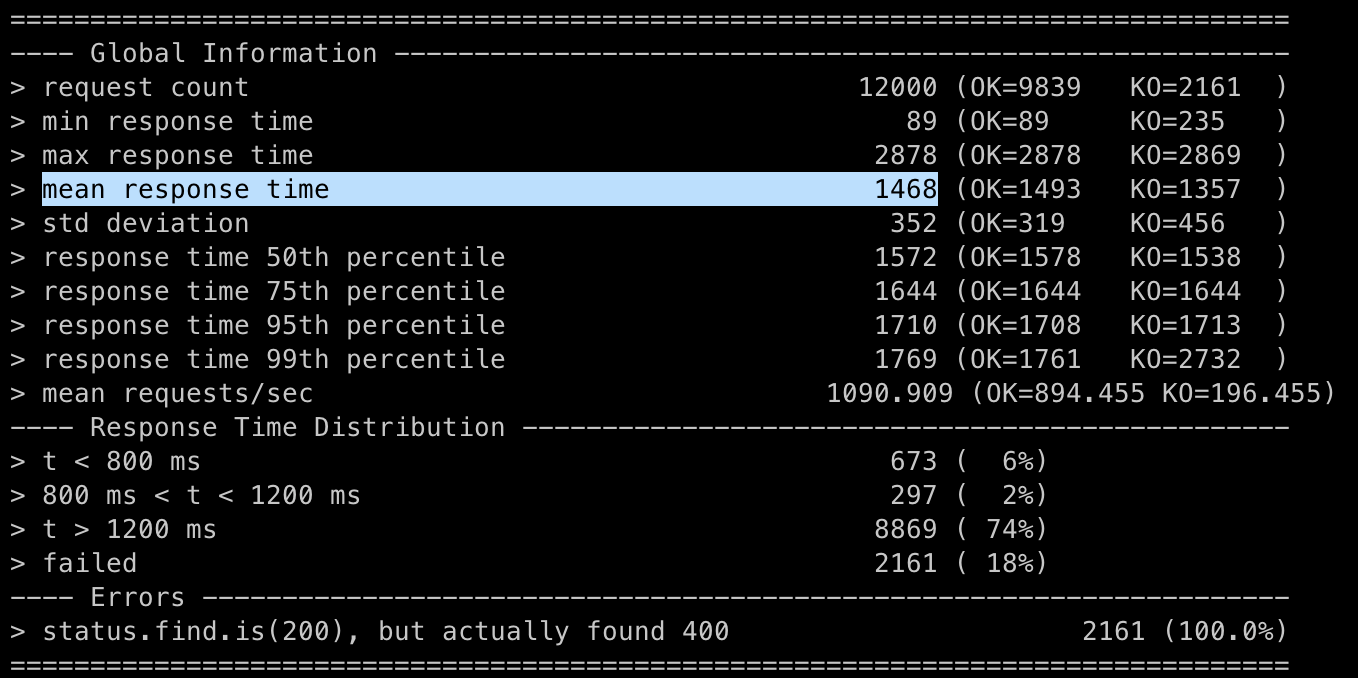
따라서 Slow Query Log라는 기능을 활용하기로 했다. 이 기능은 특정 한계치보다 오래 걸리는 쿼리들을 기록해두는 것으로, mysqldumpslow 명령어로 간단히 통계를 낼 수도 있다.
한계치를 조금 작게 설정해두고 이 기능을 활용하면, 각 SQL의 전반적인 성능을 쉽게 확인할 수 있다.
$ sudo mysqldumpslow -s at /var/lib/mysql/mysql_slow.log
Reading mysql slow query log from mysql_slow.log
Count: 9839 Time=0.00s (42s) Lock=0.00s (0s) Rows=0.0 (0), root[root]@localhost
commit
Count: 1 Time=0.00s (0s) Lock=0.00s (0s) Rows=0.0 (0), root[root]@localhost
set global slow_query_log = N
Count: 262 Time=0.00s (0s) Lock=0.03s (7s) Rows=1.0 (262), root[root]@localhost
select lecture0_.id as id1_0_, lecture0_.capacity as capacity2_0_, lecture0_.credit as credit3_0_, lecture0_.lecture_number as lecture_4_0_, lecture0_.level as level5_0_, lecture0_.liberal_art_area as liberal_6_0_, lecture0_.name as name7_0_, lecture0_.num_available as num_avai8_0_, lecture0_.subject as subject9_0_, lecture0_.term as term10_0_ from lecture lecture0_ where lecture0_.id=N for update
Count: 96 Time=0.00s (0s) Lock=0.00s (0s) Rows=0.0 (0), root[root]@localhost
rollback
Count: 765 Time=0.00s (0s) Lock=0.00s (0s) Rows=0.0 (0), root[root]@localhost
update lecture set capacity=N, credit=N, lecture_number='S', level=N, liberal_art_area=null, name='S', num_available=N, subject='S', term='S' where id=N
Count: 12000 Time=0.00s (3s) Lock=0.00s (0s) Rows=29.7 (356976), root[root]@localhost
select lecturereg0_.id as id1_1_, lecturereg0_.grade as grade2_1_, lecturereg0_.lecture_id as lecture_3_1_, lecturereg0_.student_id as student_4_1_ from lecture_registration lecturereg0_ inner join lecture lecture1_ on lecturereg0_.lecture_id=lecture1_.id where lecturereg0_.student_id=N and lecture1_.term<>'S'
Count: 11705 Time=0.00s (3s) Lock=0.00s (0s) Rows=2.0 (23575), root[root]@localhost
select lecturereg0_.id as id1_1_, lecturereg0_.grade as grade2_1_, lecturereg0_.lecture_id as lecture_3_1_, lecturereg0_.student_id as student_4_1_ from lecture_registration lecturereg0_ inner join lecture lecture1_ on lecturereg0_.lecture_id=lecture1_.id where lecturereg0_.student_id=N and lecture1_.term='S'
Count: 26 Time=0.00s (0s) Lock=0.00s (0s) Rows=0.0 (0), root[root]@localhost
SET autocommit=N
Count: 2247 Time=0.00s (0s) Lock=0.00s (0s) Rows=0.0 (0), root[root]@localhost
insert into lecture_registration (grade, lecture_id, student_id) values (null, N, N)
...평균 수행 시간이 높은 순으로 출력시켜봤다.
commit이나 rollback 등 어쩔 수 없는 쿼리들도 보이는 반면, Lock으로 동시성을 떨어트리거나 만번 이상 호출된 쿼리들도 볼 수 있었다.
개선의 여지가 있는 SQL 문을 정리해봤다:
select * from 강의 where id=? for update: 수강할 Lecture 조회, x-lock 적용select * from 수강_이력 where id=? and 학생_id=? and 학기<>?: 수강 이력 조회 (재수강 제약조건)select * from 강의_스케줄 where 강의_id=?: 강의의 일정(시간대)들 지연 로딩
간단히 해결할 수 있는 문제들부터 먼저 해결해보자.
즉시 로딩과 지연 로딩
select * from 강의_스케줄 where 강의_id=?: 강의의 일정(시간대)들 지연 로딩
Count: 150 Time=0.00s (0s) Lock=0.00s (0s) Rows=0.0 (0)
@Entity
class Lecture(
/* ..fields.. */
) {
@OneToMany(mappedBy = "lecture", cascade = [CascadeType.ALL])
val schedules: MutableSet<Schedule> = mutableSetOf()
/* ..fields and methods.. */
}Hibernate에서 @OneToMany의 로딩 방식은 기본적으로 지연 로딩이다. 필요한 순간 쿼리가 발생하여 캐싱해두는 식이다.
이때 지연 로딩을 통해 추가 쿼리를 발생시키는 Entity가 있는데, 바로 Lecture다. 강의 Entity는 강의 스케줄 Entity와 1:N 관계를 맺고 있다.
이때 유효한 시간표인지 검사하는 제약조건에서 강의 스케줄을 필요로 하므로, 여기서 추가 쿼리를 발생시키고 있다. 이를 즉시 로딩으로 바꾸면 한 번에 가져와 불필요한 추가 쿼리를 만들지 않을 것이다.
@OneToMany(mappedBy = "lecture", cascade = [CascadeType.ALL], fetch = FetchType.EAGER))Lecture와 Schedule 간의 @OneToMany 관계에 FetchType.EAGER를 적용시키고 테스트해봤다.
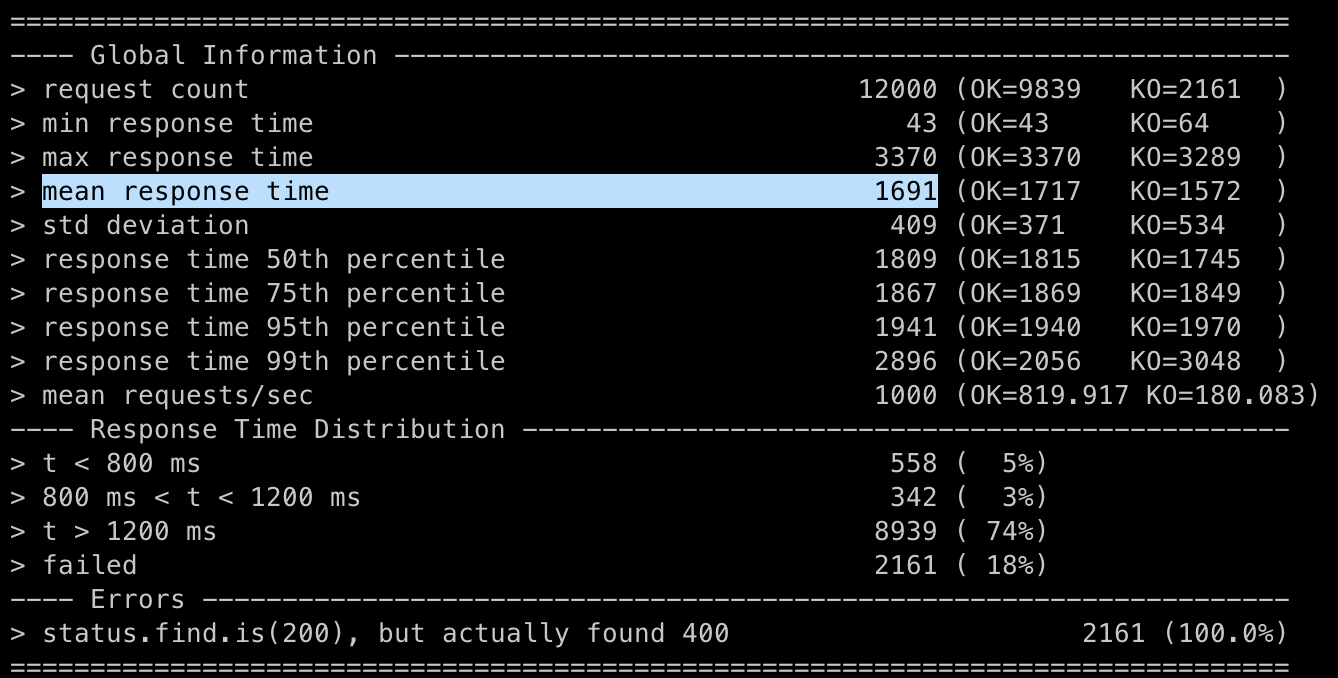
어? 오히려 더 늘었다... (1468ms → 1691ms)
조금 생각해보니 안일한 판단이었다.
Lecture를 불러온다고 해서 항상 스케줄을 보진 않는다.
예를 들면, 재수강 제약조건에서는 이전 학기 수강 이력을 모두 불러오지만, 이때 강의의 스케줄은 필요하지 않다.
또한, 수강할 강의가 만석이면, 굳이 스케줄을 불러올 필요가 없다.
그럼 스케줄을 필요로 하는 순간은 언제일까?
유효한 시간표인지 검사하는 제약조건 뿐이다. 이때에만 즉시 로딩으로 불러오도록 만들면 된다.
@Repository
interface LectureRegistrationRepository : JpaRepository<LectureRegistration, Long> {
@Query(
"select reg from LectureRegistration reg " +
"inner join fetch reg.lecture lec " +
"left join fetch lec.schedules " +
"where reg.student = ?1 and lec.term = ?2"
)
fun findRegistrationsBelongToTerm(
student: Student,
lectureTerm: String
): Set<LectureRegistration>
/* ..other methods.. */
}JPQL에서 left join fetch lec.schedules으로 스케줄을 즉시 불러오도록 했다. (해당 기능에 관해선 Hibernate의 공식 문서를 참조했다)
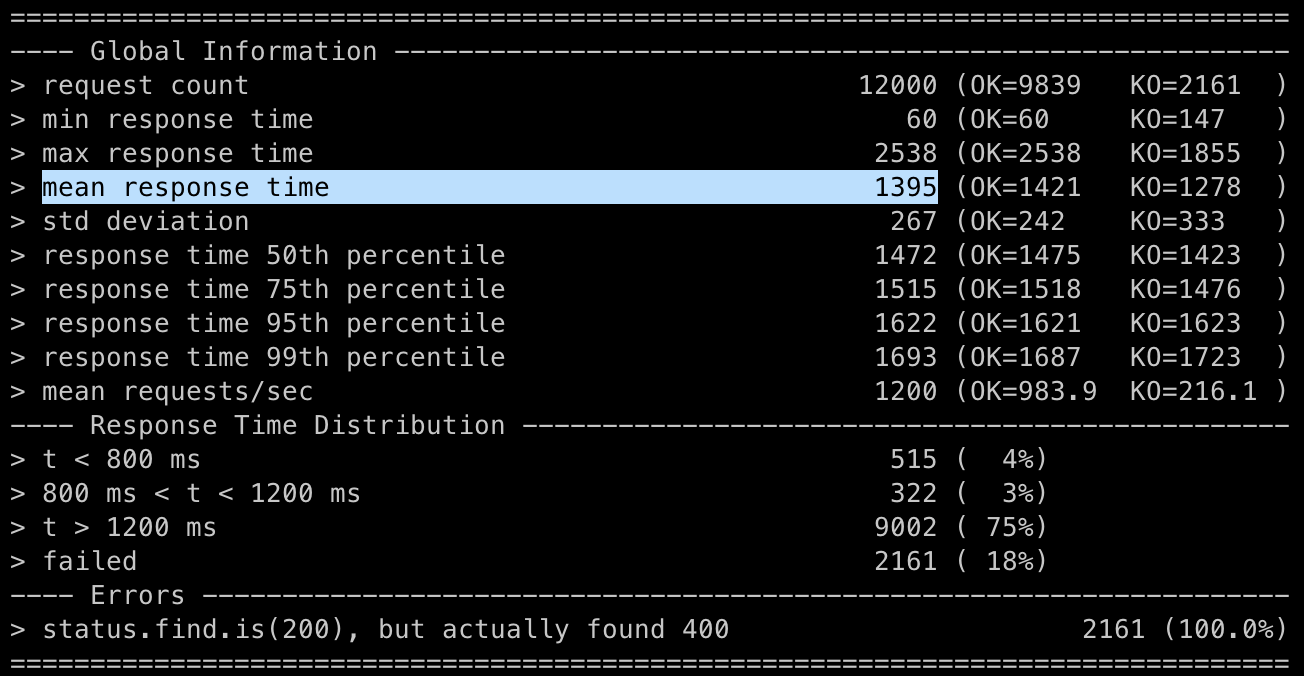
조금이지만 어쨌든 줄었다! (1468ms → 1395ms, 약 70ms)
쿼리가 참조하는 레코드 수 줄이기
select * from 수강_이력 where id=? and 학생_id=? and 학기<>?: 수강 이력 조회 (재수강 제약조건)
Count: 12000 Time=0.00s (3s) Lock=0.00s (0s) Rows=29.7 (356976)
기존의 수강 이력 조회 쿼리는 주어진 학생의 모든 과거 수강 이력을 읽어오고 있었다.
그렇게 설계한 이유는 다음과 같다:
- 기능 확장에 대비했다. 지금은 수강 이력을 확인하는 제약조건이 재수강 제약조건 뿐이지만, 추후 선이수과목 조건이라던지 비슷한 쿼리를 필요로 하는 기능이 추가될 것으로 예상했다.
- 어차피 비슷한 쿼리라면 한 번에 전부 가져오고, 애플리케이션 로직으로 필터링하는 편이 쿼리를 아낄 수 있다고 판단했다. 학생 당 수강 이력이 많아봤자 50개가 안 되므로 큰 문제는 없을 것 같았다.
그러나 이 쿼리는 무려 35만개의 레코드를 조회하고 있었다.
학생 당 수강 이력이 36개(학기 당 6강의, 6학기)라고 생각하면, '6×6×2,000=72,000'이며, 수강신청 한 번에 강의를 6개 신청하므로 '6×72,000=452,000'만큼 레코드를 조회해야 한다. 실제로 이에 가깝게 356,976번 레코드를 조회했다.
아무리 새로운 제약조건이 추가된다고 해도, 모든 수강 이력을 읽어올 필요는 없을 것이다. 따라서 이를 조건부 쿼리로 변경하여 조회하는 레코드 범위를 축소시키자.
@Query(
"select reg from LectureRegistration reg " +
"inner join reg.lecture lec " +
"where reg.student = ?1 and lec.subject = ?2 and lec.term <> ?3"
)
fun findOldRegistrationsBySubject(
student: Student,
subject: String,
term: String
): Set<LectureRegistration>SQL 문의 where 부분에 lec.subject = ?를 추가했다. 재수강 제약조건 확인을 위해, 같은 과목을 기준으로 과거 수강 이력을 조회한다.
@Entity
@Table(indexes = [Index(name = "term", columnList = "subject,term")])
class Lecture( /* ... */ )빠르게 조회할 수 있도록 인덱스도 추가해줬다.
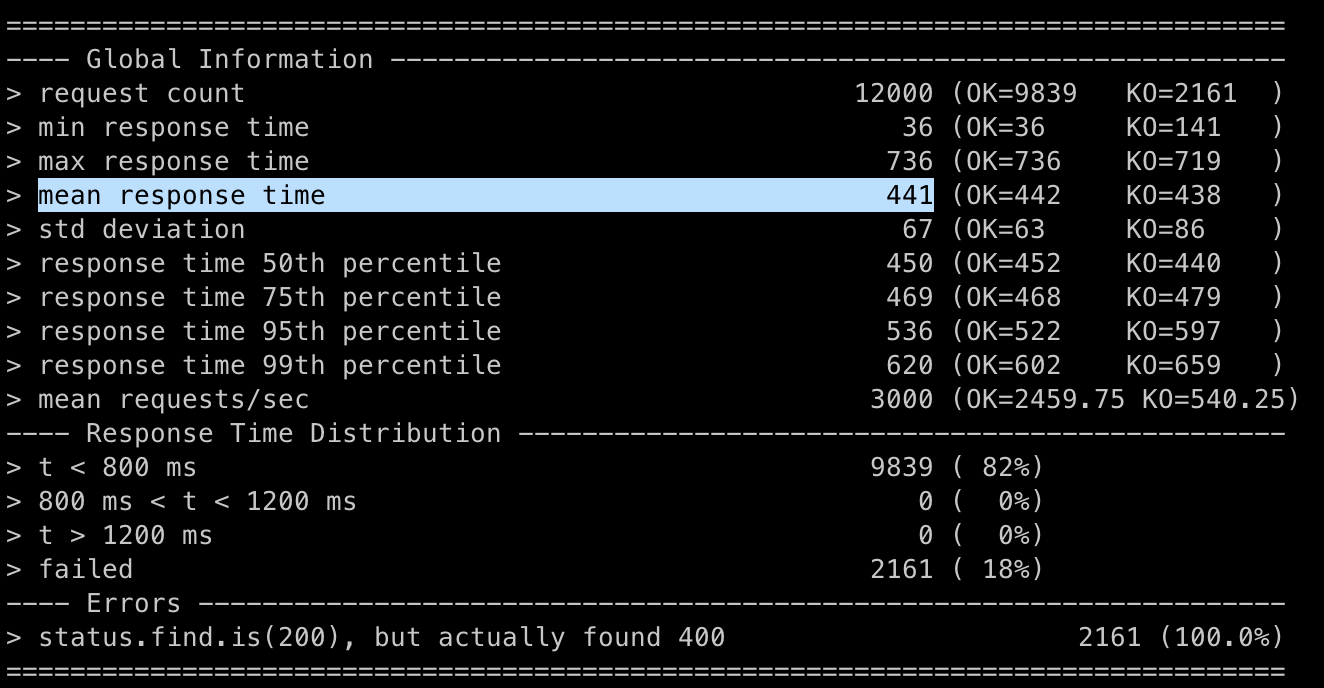
굉장히 큰 개선이 이루어졌다! (1395ms → 441ms, 약 950ms)
Count: 12000 Time=0.00s (3s) Lock=0.00s (0s) Rows=0.0 (295), root[root]@localhost
select * from 수강_이력 where id=? and 학생_id=? and 학기<>?레코드 조회도 295번으로 1000배 이상 줄었다. 진작 할 걸 그랬다.
