남은 개선 여지
select * from 강의 where id=? for update: 수강할 Lecture 조회, x-lock 적용
Count: 233 Time=0.00s (0s) Lock=0.00s (0s) Rows=1.0 (233)
저번 mysqldumpslow 결과에서 평균 수행 시간이 가장 높았던 쿼리다.
수강할 Lecture를 조회하고, 여석을 하나 줄이는 동안 x-lock을 걸기 위함인데, 배타적 잠금을 걸다보니 수행 시간이 높게 나온 것 같다.
락은 필요한데, 최대한 효율적으로 사용하고 싶은 상황. 어떻게 개선할 수 있을지 곰곰이 생각해봤다.
잠금 지속시간 줄이기
첫 번째 전략은 Lecture에 대한 x-lock을 최대한 늦게 걸고, 최소한의 시간동안 유지하는 것이다.
기존 수강 신청 트랜잭션은 다음과 같은 모습이다:
// Student 레코드 획득 (`x-lock`)
val student = studentRepository.findByIdForUpdate(studentId).orElseThrow {
errorHelper.notFound("Student $studentId")
}
// Lecture 레코드 획득 (`x-lock`)
val lecture = lectureRepository.findByIdForUpdate(dto.lectureId).orElseThrow {
errorHelper.notFound("Lecture ${dto.lectureId}")
}
// 강의 수강에 요구되는 제약조건 확인, 위반 시 `rollback`
for (constraint in registerConstraints) {
if (!constraint.comply(student, lecture)) {
val constraintName = constraint::class.simpleName
throw errorHelper.badRequest(
"Student couldn't register the lecture: violates $constraintName"
)
}
}
// 강의 여석 확인, 만석 시 `rollback`
if (lecture.numAvailable <= 0) {
throw errorHelper.badRequest(
"Student couldn't register the lecture: no available seats"
)
}
// 강의 여석 1 차감 (이후 `update 강의 where ...`)
lecture.numAvailable--
// 수강 이력 저장 (`insert into 수강_이력 values ...`)
val registration = LectureRegistration(
student = student,
lecture = lecture
)
registrationRepository.save(registration)- Student 레코드 획득 (
x-lock) - Lecture 레코드 획득 (
x-lock) - 강의 수강에 요구되는 제약조건 확인, 위반 시
rollback - 강의 여석 확인, 만석 시
rollback - 강의 여석 1 차감 (이후
update 강의 where ...) - 수강 이력 생성 (
insert into 수강_이력 values ...)
이때 Lecture에 x-lock을 건 다음 제약조건을 확인하므로, 제약조건을 위반하는 경우라도 일단 잠금은 걸어두어야만 한다.
제약조건 확인 이후에 잠금을 걸도록 하면, 비교적 레코드 락 시간이 줄어들지 않을까?
// ... Student 레코드 획득
// Lecture 레코드 획득 (Consistent read)
val lecture = lectureRepository.findById(dto.lectureId).orElseThrow {
errorHelper.notFound("Lecture ${dto.lectureId}")
}
// ... 제약조건 확인
// 영속성 컨텍스트 비우고, Lecture 레코드 다시 획득 (`x-lock`)
entityManager.detach(lecture)
val lectureForUpdate = lectureRepository.findByIdForUpdate(dto.lectureId).orElseThrow {
errorHelper.notFound("Lecture ${dto.lectureId}")
}
// ...위와 같이 처음에는 잠금 없이 레코드를 읽어오고, 이후 x-lock이 필요한 작업 직전에 레코드를 다시 획득하도록 수정해봤다.
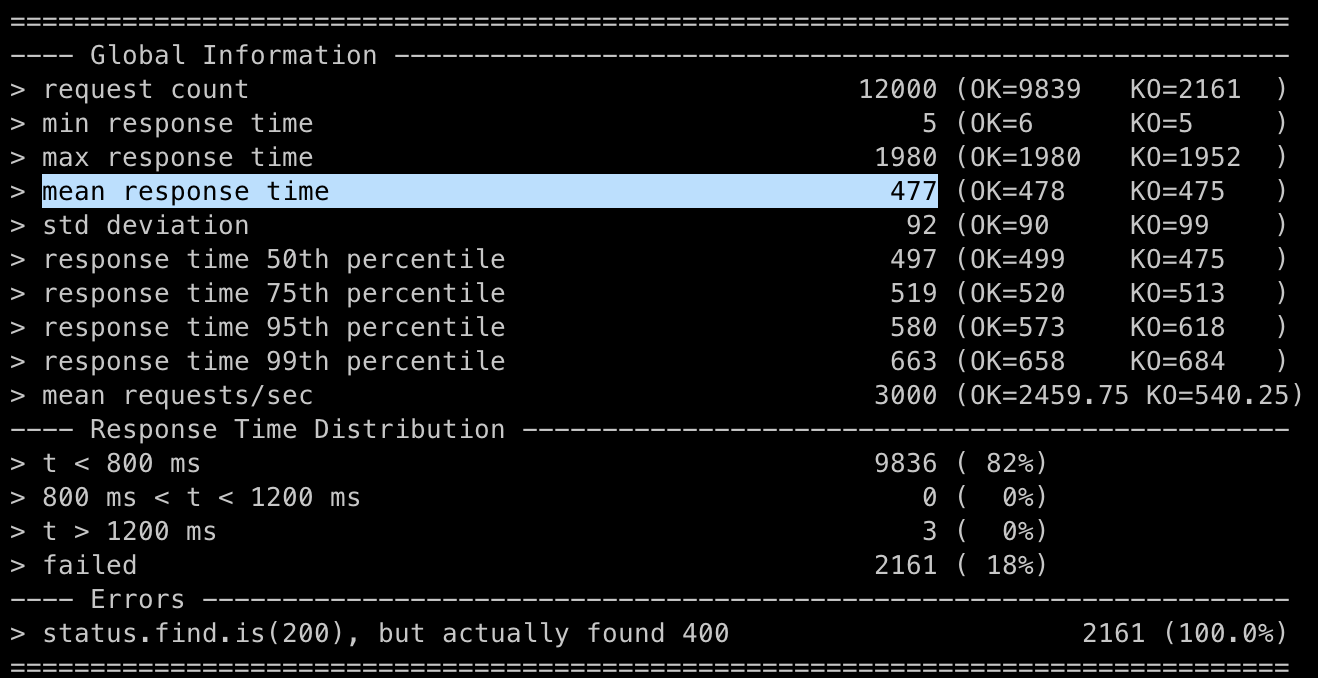
음.. 성능이 더 떨어졌다. (441ms → 477ms)
이유를 생각해봤다.
- 애초에 제약조건을 위반하는 상황이 빈번히 발생하지 않는다.
- 사실 테스트 데이터에도 제약조건을 위반하는 경우를 넣지 않았다. 자주 발생하지 않는 일이므로 굳이 작성하지 않았다.
- 제약조건을 위반하는 경우는 사용자의 실수뿐이다. 6개월의 일과를 결정하는 상황에 실수를 할 사람이 2000명 중 얼마나 될까?
- 추가적인 쿼리가 발생한다.
- 잠금 없이 Lecture 레코드를 획득하는 쿼리와 잠금과 함께 Lecture 레코드를 획득하는 쿼리, 이렇게 두 개가 발생했다.
- 잠금의 지속시간을 줄이기 위해서는 불가피한데, 요청 수가 12,000개나 되다보니 성능에 조금의 영향을 줬다.
결론적으로 이 전략은 개선에 도움이 되지 않는다. 철회하도록 하자.
만석 강의 캐싱하기
수강 신청 트랜잭션을 다시 살펴보자:
- Student 레코드 획득 (
x-lock) - Lecture 레코드 획득 (
x-lock) - 강의 수강에 요구되는 제약조건 확인, 위반 시
rollback - 강의 여석 확인, 만석 시
rollback - 강의 여석 1 차감 (이후
update 강의 where ...) - 수강 이력 생성 (
insert into 수강_이력 values ...)
만석으로 인한 수강 실패는 테스트에서 18%를 차지한다. 실제로도 제약조건 위반 사례보다는 훨씬 많을 것이다.
그런데 기존 트랜잭션에서는 만석 강의에서도 여석 확인을 위해 Lecture 레코드에 x-lock을 걸고 있다.
애플리케이션 레벨에서 만석 강의를 기억해두면, 만석 이후에는 해당 강의에 배타적 잠금을 걸 필요가 없어진다.
조금의 개선 효과가 있지 않을까?
@Component
class FullLectureArchive {
private val fullLectureIds: MutableMap<Long, Long> = ConcurrentHashMap()
private val clock: Clock = Clock.systemDefaultZone()
val logger: Logger get() = LoggerFactory.getLogger(this.javaClass)
fun isFull(lectureId: Long): Boolean {
val expTime = fullLectureIds[lectureId] ?: return false
if (expTime <= clock.millis()) {
val removed = fullLectureIds.remove(lectureId, expTime)
if (removed) {
logger.debug("Invalidate capacity cache of lecture $lectureId")
}
return !removed
}
return true
}
fun setFullFor(lectureId: Long, duration: Long) {
val expTime = clock.millis() + duration
fullLectureIds[lectureId] = expTime
logger.debug("Set lecture $lectureId full")
}
}만석 강의를 기억해두기 위한 컴포넌트를 작성했다. 만석 처리된 강의를 Map에 저장해두는 방식으로 작동한다.
멀티 스레딩에 의해 Race condition이 발생하므로 ConcurrentHashMap 자료구조를 활용했다.
A hash table supporting full concurrency of retrievals and high expected concurrency for updates. This class obeys the same functional specification as Hashtable, and includes versions of methods corresponding to each method of Hashtable. However, even though all operations are thread-safe, retrieval operations do not entail locking, and there is not any support for locking the entire table in a way that prevents all access. This class is fully interoperable with Hashtable in programs that rely on its thread safety but not on its synchronization details.
ConcurrentHashMap은 읽기 연산에 락을 수행하지 않아, Hashtable보다 동시성이 높다.
다만 그만큼 Entry 조회 시 주의를 기울여야 한다. 꺼냈을 당시에는 최신 값이었지만, 얼마 지나지 않아 최신이 아니게 될 수 있기 때문이다.
Map의 Key 값은 Lecture ID, Value 값은 캐시 만료 시간으로 했다. 캐시를 찾았을 때, 캐시의 유효기간이 지나있으면 캐시 미스로 취급한다. 유효기간은 적당히 3초로 설정 했다.
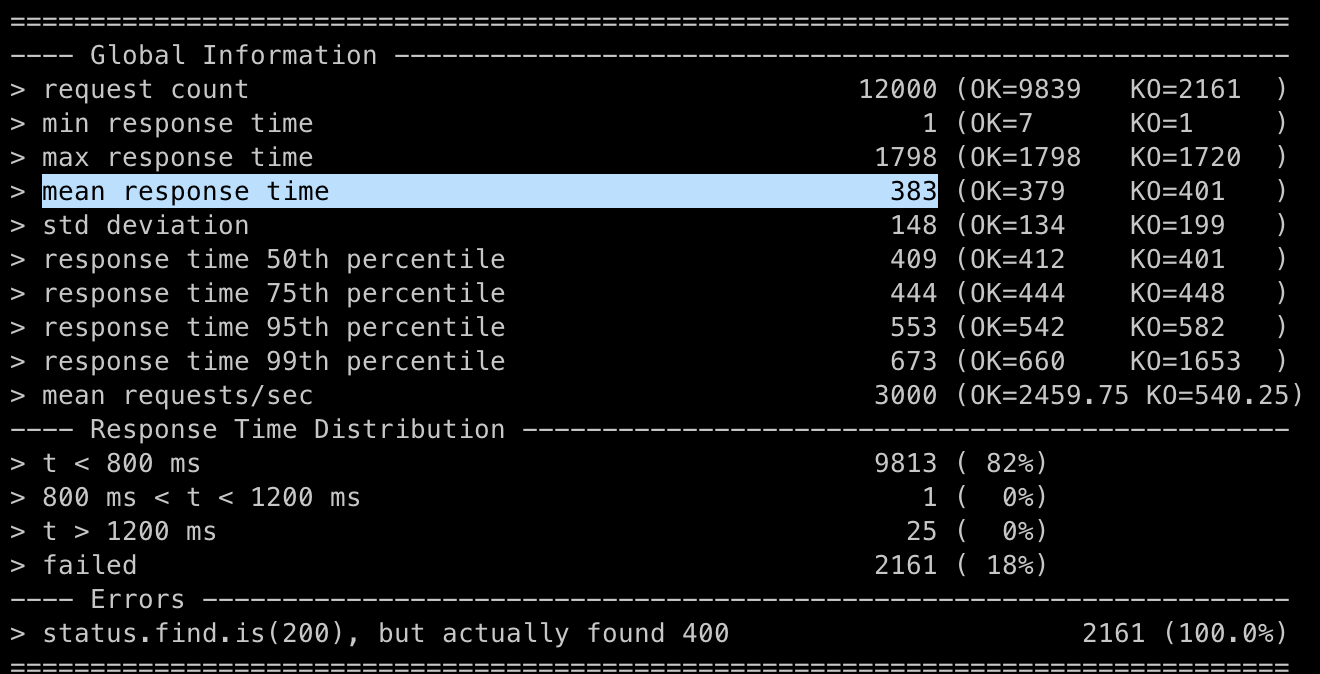
약 60ms 정도 개선됐다! (441ms → 383ms)
