
JPA(Java Persistence API)
Java에서의 ORM을 위한 API 명세
- Hibernate: 가장 많이 사용되는 JPA 구현체
엔티티(Entity)
영속화를 위한 도메인 객체
@Entity애너테이션이 적용되어야 함- 인자가 없는 생성자를 가져야 함
final클래스이어선 안 됨List,Set,Map형태의 Entity 컬렉션 필드로 연관 관계를 표현함
EntityManager
영속성 컨텍스트를 관리하는 인터페이스
- 영속성 컨텍스트(Persistence context): 영속화된 Entity들의 집합
find(): DB에서 영속화된 Entity 조회persist(): 새 Entity 영속화merge(): 해당 인스턴스의 상태를 영속성 컨텍스트 내 Entity에 병합remove(): DB에서 Entity 제거detach(): 영속성 컨텍스트에서 Entity 제거
영속성 컨텍스트(Persistence Context)
엔티티를 관리하는 영속성 컨텍스트
- 1차 캐시:
find()호출 시 영속성 컨텍스트에서 엔티티 존재를 확인함 - 동일성(identity) 보장: 식별자가 같은 엔티티 인스턴스 간의 동일성을 보장함
- 트랜잭션을 지원하는 쓰기 지연: 쿼리를 한 번에 전달하여 성능을 최적화함
- 변경 감지(dirty checking): 엔티티의 데이터를 변경하기만 하면 데이터베이스에 반영됨
- 지연 로딩(lazy loading): 연관된 엔티티들을 함께 가져오지 않고, 필요에 따라 조회할 수 있음
Entity 인스턴스의 생명 주기
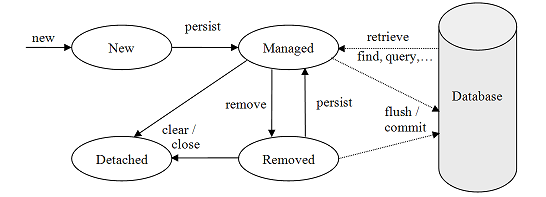
New: 영속화되지 않은 상태ManagedorPersistent: 영속화 컨텍스트에서 관리되는 상태Detached: 영속화 컨텍스트에서 더 이상 관리되지 않는 상태Removed: 영속화 컨텍스트에서 DB에서 제거되었음을 나타내는 상태
연관 관계(Relationship)
엔티티 간의 연관 관계
- 단방향: 한쪽으로만 참조하는 연관 관계
- 객체간 연관 관계를 최소화할 수 있음
- 양방향: 서로 참조하는 연관 관계
- 반대 방향으로 객체 그래프 탐색이 가능함
- 연관 관계의 주인: 연관 관계에서 테이블의 외래 키를 관리하는 쪽의 엔티티
- 주인의 반대편은
mappedBy로 주인을 지정해야 하며, 연관 관계 수정이 아닌 조회 기능만 가능함 - 연관 관계의 주인은 비즈니스 중요도가 아닌 외래 키의 위치와 관련해서 정해야 함
- 주인의 반대편은
다중성(Multiplexity)
연관 관계의 성격
- 다대일(N:1,
@ManyToOne)- 다(N) 쪽에 외래 키가 있음
- 양방향은 일대다 매핑과 함께 구현함
- 일대다(1:N,
@OneToMany)- 단방향으로 구현하면 조인 테이블을 두어야 하므로 권장되지 않음
- 일대일(1:1,
@OneToOne)- 어느 쪽이 외래 키를 가질지 선택해야 함
- 주 테이블에 외래 키를 두면 객체 지향적으로, 주 테이블만 확인해도 대상 테이블과의 연관 관계를 확인할 수 있음
- 대상 테이블에 외래 키를 두면, 테이블 관계를 일대일에서 일대다로 변경할 때 테이블 구조를 그대로 유지할 수 있음
- 어느 쪽이 외래 키를 가질지 선택해야 함
- 다대다(N:N,
@ManyToMany)- 내부적으로 연결 테이블을 추가해 구현됨
- 연결 테이블에 새로운 컬럼이 필요해지면 문제가 생기므로 권장되지 않음
- 따라서 연결 엔티티와 두 쌍의 다대일로 구현함
상속 관계 매핑
객체를 테이블로 매핑하기 위한 방법들 (@Inheritance)
- 조인(
JOINED) 전략: 각 클래스를 테이블로 표현하고 조인으로 조회함- 부모 클래스에 타입 구분 컬럼(
Discriminator)을 두어야 함 - 테이블이 정규화되는 장점이 있음
- 조회할 때 조인이 많이 사용되어 성능이 낮은 단점이 있음
- 부모 클래스에 타입 구분 컬럼(
- 단일 테이블(
SINGLE_TABLE) 전략: 통합 테이블로 여러 클래스를 표현함- 타입 구분 컬럼(
Discriminator)을 두어야 함 - 조회 쿼리가 단순하다는 장점이 있음
- 자식 엔티티의 컬럼이
null을 허용해야 하며, 테이블이 커질 수 있다는 단점이 있음
- 타입 구분 컬럼(
- 구현 클래스마다 테이블(
TABLE_PER_CLASS) 전략: 서브타입 테이블로 표현함- 자식 테이블 각각에 필요한 컬럼을 모두 둠
- 자식 테이블을 통합해서 다루기 어렵다는 단점이 있음 (따라서 권장되지 않음)
@MappedSuperclass
자식 테이블에 컬럼을 제공하는 부모 클래스를 위한 애너테이션
- 부모 클래스는 테이블과 매핑하지 않고, 자식 클래스에게 매핑 정보만 제공하고 싶은 경우 사용함
식별 관계 매핑
연관 관계를 갖는 테이블을 매핑하기 위한 관계들
- 식별 관계: 자식 테이블에서 부모의 기본 키를 자신의 기본 키와 외래 키로 사용하는 관계
- 특정 상황에 조인 없이 하위 테이블만으로 검색을 완료할 수 있음
- 자식의 기본 키가 부모의 기본 키로 이루어지므로, 테이블 구조가 유연하지 못함
- 비식별 관계: 자식 테이블에서 부모의 기본 키를 외래 키로만 사용하는 관계
- 기본 키가 적은 수의 컬럼으로 이루어져, 조인과 인덱스 구성이 단순함 (따라서 일반적으로 권장됨)
복합 키(Composite Key)
@IdClass: RDB에 가까운 방법- 엔티티의 필드들을 식별자 클래스에 매핑함
@EmbeddedId: 객체 지향에 가까운 방법- 식별자 클래스를 타입으로 하는 기본 키 필드를 둠
- 식별 관계를 매핑할 때
@MapsId를 활용함
프록시(Proxy)
JPA 구현체는 엔티티를 지연 로딩하기 위해 프록시 객체를 제공함
- 프록시 객체: 원본 엔티티를 상속받고, 지연 로딩 기능이 적용된 객체
- 엔티티를 실제 사용하는 시점까지 DB 조회를 미루고 싶을 때
getReference()메소드를 사용할 수 있음PersistenceUnitUtil.isLoaded()메소드로 초기화 여부를 확인함
- 컬렉션 래퍼: Hibernate에서 추적과 관리를 위해 엔티티 컬렉션을 프록싱한 것
페치 전략(Fetch Strategy)
연관된 엔티티를 조회하기 위한 전략
즉시 로딩(Eager Loading)
연관된 엔티티를 조인 쿼리를 통해 즉시 조회함
- 불필요한 쿼리를 절약함
- 2개 이상의 컬렉션을 즉시 로딩으로 설정하는 것은 권장되지 않음
- SQL 실행 결과가 너무 많은 데이터를 반환할 수 있기 때문
지연 로딩(Lazy Loading)
연관된 엔티티를 프록시로 조회하여, 실제 사용할 때 초기화함
- 데이터를 필요에 따라 조회함
- 대부분의 경우에 지연 로딩을 사용하고, 필요에 따라 즉시 로딩을 사용하는 편이 권장됨
N+1 문제
하위 엔티티들을 첫 쿼리 실행 시 한 번에 가져오지 않고, 지연 로딩으로 N개의 추가 쿼리가 발생하는 문제
- JPQL의
join fetch혹은@EntityGraph를 통해 즉시 로딩하는 방법으로 해결할 수 있음
영속성 전이(Transitive Persistence)
부모 엔티티의 영속 상태를 자식 엔티티로 전이함 (cascade)
PERSIST: 영속화 전이- 엔티티를 저장할 때 연관된 모든 엔티티가 영속 상태여야 하는데, 영속화 전이를 이용하면 이를 편리하게 구현할 수 있음
REMOVE: 삭제 전이- 자식 테이블의 외래 키 제약조건으로 인해 무결성 예외가 발생할 수 있으므로, 부모 제거 시 자식도 함께 제거하도록 만듬
고아 객체(Orphan Entity)
부모 엔티티와 연관 관계가 끊어진 자식 엔티티
- 고아 객체 제거(Orphan Removal): JPA가 고아 객체를 자동으로 삭제하는 기능
- 부모 엔티티의 컬렉션에서 자식 엔티티의 참조만 제거되면, 자식 엔티티가 자동으로 삭제됨
값 타입(Value Type)
Entity가 아닌 일반적인 타입 (식별자와 독립적인 생명 주기가 없음)
- 임베디드(Embedded) 타입: 추가적인 테이블을 만들지 않는 값 타입
- 특정 필드를 객체 지향적으로 다루고 싶을 때 사용함
@Embeddable클래스 타입으로 선언한 필드에@Embedded를 적용하여 사용함- 이때, 매핑 정보를 재정의하려면
@AttributeOverride를 사용함
- 이때, 매핑 정보를 재정의하려면
- 불변 객체로 설계하는 것이 권장됨
- 값 타입 컬렉션: 별도의 테이블로 여러 개의 값을 표현하는 컬렉션
- 컬렉션 필드에
@ElementCollection과@CollectionTable을 적용하여 사용함- 이때, 매핑 정보를 재정의하려면
@AttributeOverride를 사용함
- 이때, 매핑 정보를 재정의하려면
- 값 타입 컬렉션을 변경할 때, 데이터 전체를 삭제하고 재저장하는 방식으로 작동할 수 있음
- 값 타입에는 기본 키가 없기 때문
- 데이터가 많다면 새로운 Entity와의 일대다 관계로 대체하는 것이 권장됨
- 컬렉션 필드에
객체 그래프(Entity Graph)
Entity 조회 시점에 연관된 Entity들을 함께 조회하는 기능
@NamedEntityGraph: Entity 클래스에 객체 그래프를 정적으로 정의getEntityGraph(): EntityManager를 통해 객체 그래프를 동적으로 정의
JPQL
JPA에서의 엔티티 조회를 위한 객체 지향 쿼리 언어
- 네이티브 SQL보다 추상적이고 간결함
Criteria
JPQL을 생성하기 위한 빌더 클래스
- 프로그래밍 코드로 JPQL을 작성할 수 있음
- 동적 쿼리를 작성하기 편하고 Type-safety를 제공함
- 복잡하고 장황하다는 단점이 있음
Spring Data JPA
Spring에서 RDB를 추상화하여 JPA로 다루기 위한 프레임워크
- 데이터 접근 계층 개발을 구현 클래스 없이 인터페이스 작성만으로 끝낼 수 있음
JpaRepository
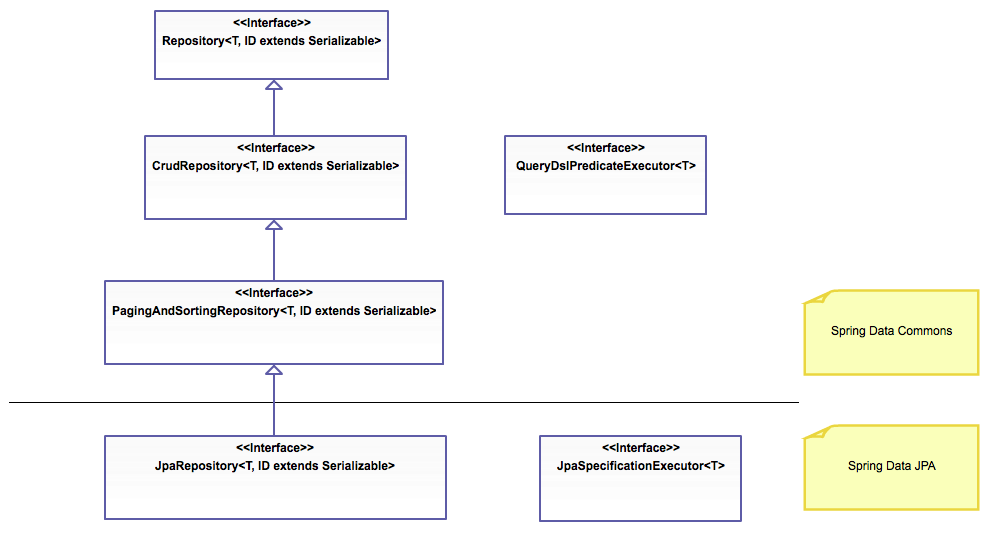
간단한 CRUD 기능을 공통으로 처리하는 인터페이스
save(): 새로운 Entity는 저장(persist), 기존 Entity는 갱신(merge)delete(): EntityManager의remove()호출findOne(): EntityManager의find()호출getOne(): EntityManager의getReference()호출findAll(): 모든 엔티티 조회, 정렬이나 페이징 조건을 제공할 수 있음
쿼리 메소드 기능
쿼리를 간편하게 작성할 수 있도록 돕는 기능
- 메소드 이름으로 쿼리 생성
@Query애너테이션을 사용하여 쿼리 직접 정의
Specification
JPA Criteria를 기반으로 하는 추상화된 쿼리 조건문 빌더
@Transactional
트랜잭션 범위의 영속성 컨텍스트 전략을 위한 Spring AOP 기능
- 전파(propagation) 속성: 해당 메서드를 어떤 트랜잭션에서 실행할지 결정
REQUIRED: 기존에 트랜잭션이 없다면 새로 생성해 사용함 (기본 값)SUPPORTS: 기존 트랜잭션이 있다면 사용하고, 없다면 없이 실행함MANDATORY: 기존 트랜잭션이 있다면 사용하고, 없다면 예외를 발생시킴NEVER: 기존에 트랜잭션이 있다면 예외를 발생시킴NOT_SUPPORTED: 기존 트랜잭션이 있다면 중지시키고, 트랜잭션 없이 실행함REQUIRES_NEW: 기존 트랜잭션이 있다면 중지시키고, 새로 생성해 사용함NESTED: 기존 트랜잭션이 있다면 세이브 포인트를 만들고, 새로 생성해 사용함 (예외 발생 시 해당 지점으로 롤백)
QueryDSL
쿼리를 간결하고 Type-safe하게 다룰 수 있도록 하는 프레임워크
- JPA Criteria를 대체할 수 있음
- 매우 유연하고 직관적인 코드로 쿼리를 작성할 수 있음
