자료구조
데이터를 저장하고 효율적으로 접근하거나 수정할 수 있도록 하는 구조
선형 자료구조
데이터가 연속적으로 배열되는 자료구조
- 한 원소가 다음 원소 하나와 연결된 구조
배열 vs 연결 리스트
배열(Array)
| 평가 요소 | 시간복잡도 |
|---|---|
| 랜덤 액세스 | O(1) |
| 원소 삽입/제거 | O(n) |
원소를 인덱스와 함께 특정 순서로 나열한 구조
- 인덱스를 통해 빠르게 특정 원소를 접근할 수 있음
- 중간에 원소를 삽입하거나 제거하면 뒤의 원소들을 재배열해야 함
- 일반적으로 메모리를 연속적으로 할당하여 구현하며, 고정된 크기를 가짐
- 가변 배열(Dynamic array): 크기를 동적으로 늘릴 수 있는 배열
연결 리스트(Linked list)
| 평가 요소 | 시간복잡도 |
|---|---|
| 랜덤 액세스 | O(n) |
| 원소 삽입/삭제 | O(1) |
원소를 담은 각 노드가 다음 노드를 참조하는 형태의 구조
- 중간에 원소를 쉽게 삽입하거나 제거할 수 있음
- 특정 원소를 접근하려면 앞의 노드들을 순차적으로 확인해야 함
- 일반적인 배열에 비해 오버헤드가 존재함
- 노드마다 메모리를 할당함 (빈번한 메모리 할당으로 인한 I/O 병목 발생)
- 메모리가 연속적이지 않음 (지역성의 원리에 기반한 CPU 캐시 성능 하락)
- 이중 연결 리스트(Doubly-linked list): 노드가 양방향으로 연결된 연결 리스트
스택 vs 큐
스택(Stack)
후입선출(LIFO) 방식의 선형 자료구조
- 한 방향(
top)에서 원소를 쉽게 삽입(push)하거나 제거(pop)할 수 있음 - 구현 방식:
- 가변 배열을 통한 구현: 후입선출만 한다면 O(1)
- 단일 연결 리스트를 통한 구현: 모든 경우 O(1)이지만, 노드 메모리 할당 오버헤드가 있음
큐(Queue)
선입선출(FIFO) 방식의 선형 자료구조
- 원소를 앞(
front)에서 쉽게 제거(dequeue)하고, 뒤(back)에서 쉽게 삽입(enqueue)할 수 있음 - 구현 방식:
- 연결 리스트를 통한 구현: 마지막 노드를 기억함으로써 O(1)
덱(Deque; double-ended queue)
양쪽 방향에서 원소를 삽입하고 제거할 수 있는 선형 자료구조
- 구현 방식:
- 가변 배열을 통한 구현: 대부분 O(1)이며 참조 지역성에 의해 효율적이나, 한 방향에서는 O(n)임
- 이중 연결 리스트를 통한 구현: 모두 O(1)이지만, 노드 메모리 할당 오버헤드가 있음
우선순위 큐(Priority Queue)
원소를 우선순위에 따라 배열하는 큐
- 구현 방식: 힙을 통한 구현
비선형 자료구조
데이터가 연속적이지 않은 자료구조
- 한 원소가 여러 개의 다음 원소들과 연결될 수 있는 구조
그래프(Graph)
여러 노드가 서로 연결되어 있는 형태의 비선형 자료구조
- 인접 행렬(Adjacency matrix): 두 노드가 인접되어 있는지 보인 2차원 테이블
- 인접 리스트(Adjacency list): 한 노드마다 인접한 노드 목록을 보인 리스트
트리(Tree)
여러 노드가 계층 구조로 연결된, 사이클이 없는 그래프
이진 트리(Binary tree)
각 노드가 최대 2개의 자식을 갖는 트리
- Full binary tree: 각 노드가 0개 혹은 2개의 자식을 갖는 트리
- Complete binary tree: 모든 단말 노드가 가능한 왼쪽에 배열된 트리 (completely filled)
- Perfect binary tree: 모든 단말 노드가 같은 깊이를 갖는 트리
이진 탐색 트리(BST; binary search tree)
이진 탐색을 기반으로 정렬된 이진 트리
- 이진 탐색을 통해 O(lgn)만에 원소를 찾고, 삽입하고, 제거할 수 있음 (단, 최악은 O(n))
- 각 노드가
왼쪽 서브트리의 모든 값<오른쪽 서브트리의 모든 값을 만족 - 균형이 맞지 않고 편항되면, 이진 탐색에도 순차적으로 작동함
- Self-balancing BST: 탐색 속도 향상을 위해 스스로 균형을 맞추는 이진 탐색 트리 (쓰기 성능과의 trade-off)
Red-black tree
각 노드를 red 혹은 black으로 다뤄 균형을 맞추는 Self-balancing BST
- 모든 경우에도 O(lgn)만에 원소를 찾고, 삽입하고, 제거할 수 있음
힙(Heap)
각 노드의 값이 후손들보다 크거나 같은 트리 기반 자료구조
- 우선순위가 가장 높은 원소를 O(1)만에 얻을 수 있음
- 구현 방식:
- Binary heap: Complete binary tree로 구현한 힙
- 삽입 평균 O(1), 최악 O(lgn) (필요에 따라 heapify)
- 삭제 O(lgn) (root외 swap 후 heapify)
- Binary heap: Complete binary tree로 구현한 힙
B-Tree
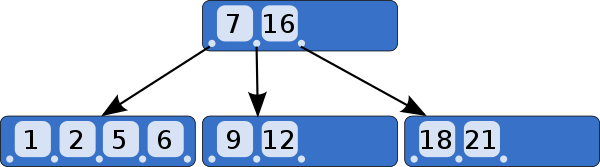
한 노드에 여러 원소를 담고, 스스로 균형을 맞추는 트리
- 각 노드가
포함된 원소 수 + 1만큼의 자식을 가지며, 최대차수(order)개까지 가질 수 있음- 각 원소가
자신의 왼쪽 서브트리 내 모든 값<자신의 값<자신의 오른쪽 서브트리 내 모든 값을 만족함 - 자식의 수가 차수를 초과하면 분할함으로써 균형을 맞춤
- 각 원소가
- 모든 경우에 O(lgn)만에 원소를 찾고, 삽입하고, 제거할 수 있음
- 큰 블록 단위로 읽거나 쓰는 디스크 환경에서는 BST보다 효율적임 (e.g. 파일 시스템, 데이터베이스)
- 한 노드가 여러 자식을 가지므로, BST보다 높이가 작음 (I/O 횟수가 줄어들어 효율적임)
- 한 노드에 여러 개의 원소가 담기므로, 한 번의 I/O로 많은 데이터를 다룰 수 있음
B+Tree
원소를 내부 노드가 아닌 단말 노드에만 저장하며, 단말 노드가 이중 연결 리스트로 이어진 B-Tree
- 연결 리스트를 통해 원소를 순차적으로 탐색할 수 있음
- 내부 노드에 키를 더 많이 보관하므로, B-Tree보다 높이를 더 줄일 수 있음
Map(Associative array)
key-value 쌍을 저장하는 자료구조
Hash table을 통한 구현
해시 함수와 배열을 통해 구현함 (bucket들로 이루어진 배열)
- 해싱을 통해 값의 위치를 O(1)만에 찾아냄
- 해시 값 간의 충돌(Collision)이 있을 수 있음
- 따라서 원소를 찾거나 삽입, 삭제하는 데에 최악의 경우 O(n)이며, 이는 좋은 해시 함수를 통해 예방할 수 있음
Separate chaining
각 bucket마다 독립적인 자료구조를 가져 충돌을 해결함
- 적재율이 충분히(약 70%) 낮고, 해시 함수의 성능이 좋은 일반적인 상황에는 잘 작동함
- 따라서 동적으로 크기를 확장(rehash)해야 하며, 이 비용을 무시할 수 없음
- 구현 방식:
- 연결 리스트를 통한 구현: bucket마다 독립적인 연결 리스트를 가짐
- 연결 리스트에 의한 메모리 오버헤드가 발생함
- Self-balancing BST를 통한 구현: bucket마다 독립적인 Self-balancing BST를 가짐
- 장점: 최악의 경우 O(n)이 아닌 O(lgn)
- 단점: 구현의 복잡함으로, 작은 크기의 hash table에서 성능이 낮을 수 있음
- 연결 리스트를 통한 구현: bucket마다 독립적인 연결 리스트를 가짐
Open addressing
충돌 발생 시 다른 bucket을 사용하여 해결함
- 연속된 메모리를 할당하므로 CPU 캐시 효율이 높음
- 따라서 원소의 크기가 작고, 적재율이 작으면 효율적이나, 그 반대의 상황에는 비효율적임
- 구현 방식:
- Linear probing: 다음 bucket을 사용함
- Quadratic probing: k2 이후의 bucket을 사용함 (clustering 완화)
- Double hashing: 두 번째 해시 함수를 활용하여 bucket을 선정함 (clustering 완화)
Tree를 통한 구현
Self-balancing BST를 통해 구현함
- 원소를 정렬된 상태로 다룸
- 모든 경우에 O(lgn)만에 값을 찾고, 삽입하고, 제거할 수 있음
