Automatic Defect Classification Using Semi-Supervised Learning With Defect Localization
Abstract
자동 결함 분류(ADC) 시스템은 반도체 제조 공정에서 발생하는 결함을 자동으로 분류한다.
ADC는 반도체 칩 생산의 수율을 높이고, 공정 중 사고를 방지하는 결함 관리의 시작점이다.
ADC는 주사 전자 현미경(SEM) 결함 이미지를 활용해 웨이퍼 표면의 결함을 찾아낸다.
Problem
- SEM 이미지의 수동 분류는 숙련된 엔지니어를 고용하는데 상당한 인건비가 발생
- 라벨이 부착된 이미지가 부족하고 이미지의 배경이 너무 다양해 실제 제조 공정에 ADC를 적용하는게 어려움
문제 해결을 위해,
📌 결함 위치 탐지를 활용한 자동 결함 분류를 제안
📌 라벨링 비용을 줄이기 위해 본 논문에서는 반지도 학습을 사용하는 분류 모델과 결함 탐지 모델을 설계함
Preliminaries
semi-supervised learning은 라벨이 없는 데이터는 쉽게 얻을 수 있지만, 라벨이 있는 데이터는 얻기 어렵고 비용이 많이 들며 시간이 많이 소요되는 실제 응용 분야에 적합하다.
ADC에 사용되는 SEM이미지의 라벨링 비용이 매우 높기 때문에 반지도 학습을 사용하는게 효과적이다.
A. Semi-Supervised Image Classification
반지도 이미지 분류에서 가장 중요한 것은 pseudo-labeling과 consistency regularization을 결합하는 것이다.
-
consistecy regularization: 모델 입력을 증강해 새로운 입력이 있을때 예측이 크게 변하지 않는다는 가정에 따라 모델을 규제하는것
- 라벨이 없는 이미지를 사용할 수 있의며, 사용되는 데이터 양이 증가함에 따라 모델의 일반화 능력도 향상됨
-
pseudo labeling: 라벨이 있는 데이터를 기반으로 라벨이 없는 데이터에 임시 라벨을 제공함
-
FixMatch: 소량의 라벨이 있는 데이터를 사용해 모델을 훈련시킴, 라벨이 없는 데이터에 약한 증강을 적용해 모델에 추가함.
- 여기서 얻어진 prediction에서 가짜 라벨을 추출, 동일한 라벨이 없는 데이터에 강한 증강을 적용해 학습함으로 예측과 가짜 라벨을 유사하게 만듬이미지크기와 계산 비용을 고려하여 FixMatch를 기반으로 배경의 영향을 제한하는 분류 모델 개발
B. Semi-Supervised Object Detection
객체 탐지에서는 객체의 영역 정보를 라벨링 해야하기에 이미지 분류보다 높은 라벨링 비용이 필요하다.
본 논문에서는 Faster R-CNN구조를 사용하고있으며, 이 구조를 결함 위치 탐지에 적용했다.
Method
👾 ADC의 주요 문제
1. 다양한 이미지 배경의 영향
2. 라벨이 부족함
💡 주요 아이디어
1. 반지도 학습 사용
2. 결함 패턴 학습시 배경의 영향을 줄이기 위해 결함 위치 탐지를 사용해 설계
2-1. 결함 위치 탐지는 라벨링 비용을 줄이기 위해 반지도 객체 탐지에 기반을 두고 있음
A. Defect Localization
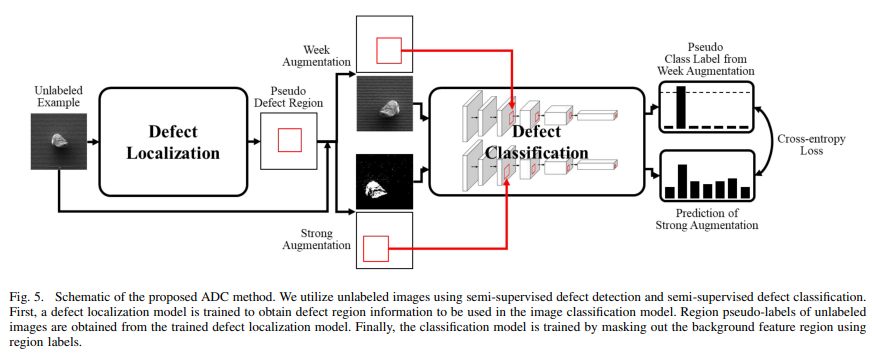
분류 모델에서 배경 특징의 영향을 최소화 하기 위해 결함 위치 탐지를 사용한다. 결함 위치 탐지 모델의 학습을 위해 SEM 이미지의 결함 영역 정보가 필요하지만, 라벨링 비용이 매우 높다. 본 연구에서는 라벨이 없는 SEM이미지를 사용해 결함 위치탐지 모델을 개발했다.
👀 HOW?
- Faster R-CNN구조에 기반을 두고 있음
- 라벨이 없는 이미지 활용을 위해 메모리 뱅크를추가
- 라벨이 있는 이미지: 실제 영역 좌표를 예측하도록 모델을 학습
- 라벨이 없는 이미지: 유사한 라벨이 있는 이미지의 영역을 pseudoregion coordinates로 사용
- 라벨이 없는 데이터의 손실 함수는 라벨이 있는 데이터의 가장 유사한 특징을 사용하여 가짜 라벨을 제공함
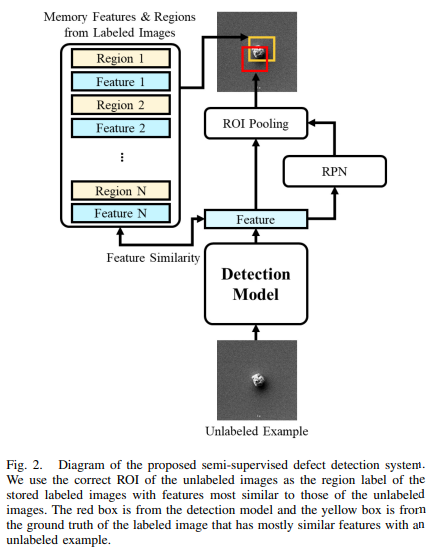
B. Semi-Supervised Calssification With Defect Localization
이 연구에서 제안된 분류 모델은 FixMatch를 기반으로 하고, 모델의 구조는 위 사진과 같다.
💡 주요 아이디어
1. 추가적인 위치 정보를 사용, 배경의 영향을 최소화하는 분류 모델 설계
2. 라벨이 있는 이미지와 없는 이미지를 동시에 사용해 반지도 학습을 진행
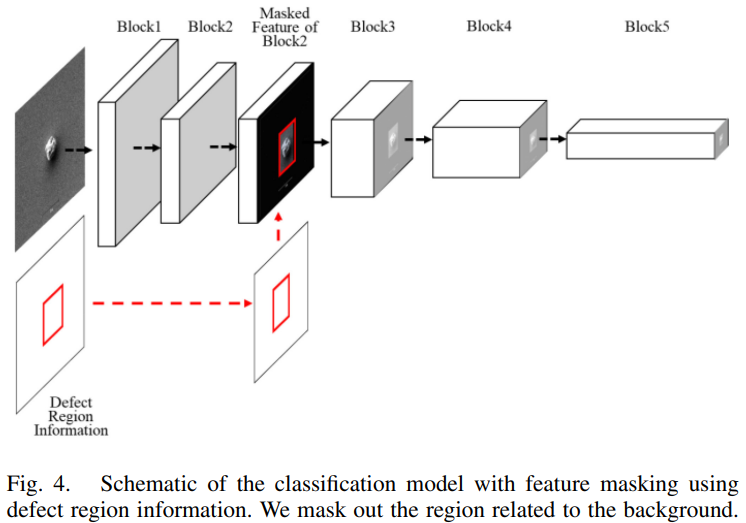
1-1. SEM 이미지가 분류 모델을 통과할 때, 위치 정보가 배경 특징을 마스킹 하는데 사용됨
- 라벨이 없는 이미지가 분류 모델의 두번째 블록을 통과 할 때 결함이 아닌 영역의 특징 값이 0으로 대체 됨
- ResNet50의 두번째 블록에서 특징 마스킹을 적용함->결함과 관련된 특징 값만 후속 블록으로 전달됨
2-1. 라벨이 있는 이미지
- 손실 함수
- 이 연구의 손실 함수는 FixMatch의 손실함수와 유사함
- 두 확률 분포 간의 크로스 엔트로피 값을 평가함
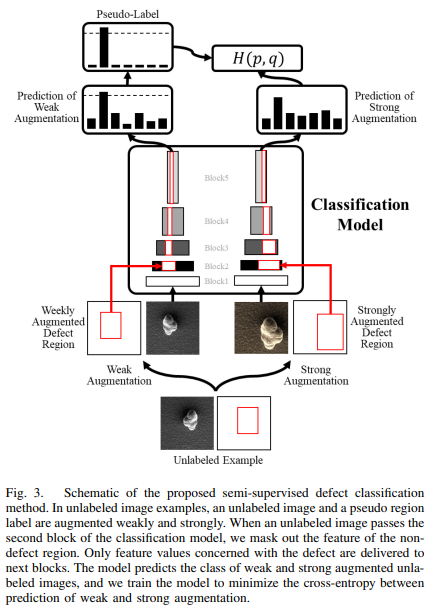
2-2. 라벨이 없는 이미지
- 약한 증강, 강한 증강이 이미지와 결함 영역 모두에 적용됨
- 분류 모델은 FixMatch와 유사하게 약한 증강과 강한 증강에 대해 비슷한 예측을 하도록 훈련됨
- 약한 증강과 강한 증강은 이미지에서 결함의 크기와 위치를 변경함
- 라벨이 없는 데이터에 적용된 증강은 결함의 위치 정보에도 적용되어 결함의 정확한 위치 정보를 제공함
- 결함 위치 정보에서 얻은 영역은 분류 모델에서 해당 배경의 특징을 마스킹하는데 사용됨
- 손실함수
전체 학습의 손실함수
C. Overall Method
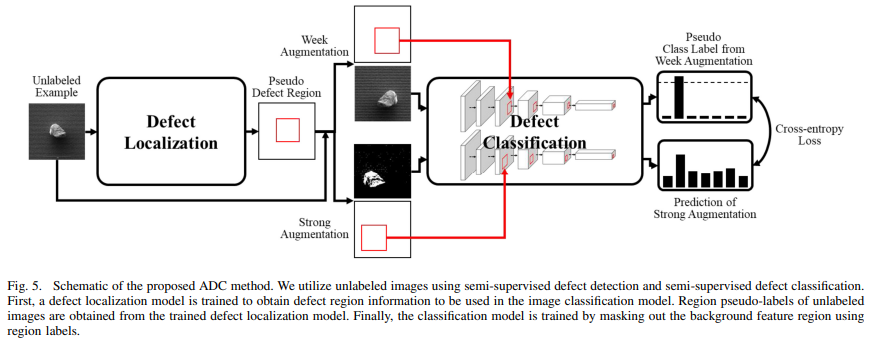
1. 제안된 반지도 학습 방법을 사용해 결함 탐지 모델을 학습
1-1. 라벨이 없는 이미지와 위치 정보가 추가
2. 학습된 탐지 모델을 통해 라벨이 없는 이미지를 통과시켜 결함 영역 정보를 얻음
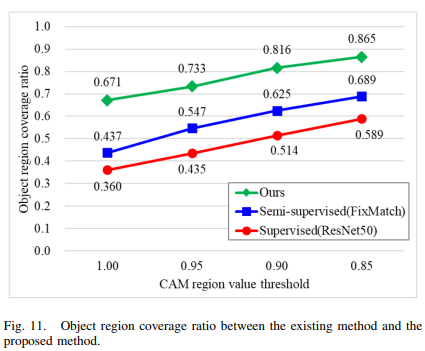
제안된 방법과 기존 방법간의 성능 비교