DDPM은 비평형 열역학에서 영감을 받은 이미지 생성 방법이다. 이 모델은 흐릿한 이미지를 점점 선명하게 만드는 과정으로 이미지를 생성한다. 마치 우리가 스케치에서 시작해서 완성된 그림을 그리는 과정과 비슷하다.
이 모델을 잘 작동하게 하려고 논문에서는 가중 변분 경계를 사용했다. 이는 확산 확률 모델과 노이즈를 제거하는 방법인 스코어 매칭을 결합한 방법이다. 이 모델은 CIFAR10 데이터 셋에서 9.46이라는 높은 점수를 받았고, FID점수도 3.17로 낮아서 이미지 품질이 뛰어나다는걸 보여줬다.
Introduction
Diffusion model은 Markov chain을 매개 변수화 해서 훈련시키는 방식을 사용한다. 이 모델은 데이터에 점점 노이즈를 추가하는 확산 과정을 역으로 학습해서, 최종적으로는 원본 데이터와 일치하는 샘플을 생성하게 된다. 쉽게 얘기해서, 아주 조금씩 노이즈를 추가하면서 데이터를 흐리게 만들고, 이 과정을 거꾸로 진행해서 원래의 깨끗한 이미지를 복원하는 방법을 말한다.
Background
Diffusion model(확산 모델)은 밑의 수식 형태를 가진 latent variable 모델이다.
pθ(x0)=:∫pθ(x0:T)dx1:T
x1,...,xT 얘네들이 같은 차원의 데이터 x0q(x0)의 latent variable들이다.
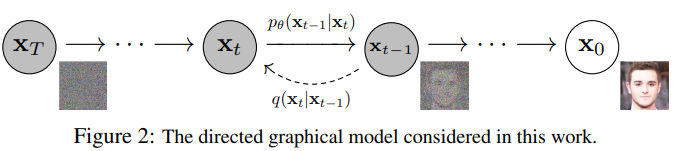
joint distribution pθ(x0:T)은 reverse process라고 부른다. 그리고 이 수식 학습된 가우시안 전이를 갖는 마르코프 체인으로 정의되며, p(xT)=N(xT;0,I):에서 시작한다.
이 확산 모델이 다른 latent variable 모델들과 구별되는 점은 forward process혹은 diffusion process라고 불리는 근사 posterior q(x1:T∣x0)가 고정된 마르코프 체인이라는 것이다. 이 과정(forward or diffusion process)은 variance schedule β1,...,βT:에 따라 데이터에 점진적으로 가우시안 노이즈를 추가한다.
훈련은 negative log likelihood의 variational bound를 최적화 하면서 진행된다. 아래 수식은 모델의 파라미터 θ를 조정하여 모델이 주어진 데이터 x0에 대해 가능한 최선의 예측을 하도록 한다.
variational bound의 개념에 대해서 짧게 설명하자면 복잡한 분포의 정확한 계산을 간단하게 근사하는 방법이다. 이 논문에서는 KL발산을 사용해 실제 분포와 근사 분포 간의 차이를 최소화 하려고 한다.
forward process의 분산 βt는 reparameterization을 통해 학습하거나, 하이퍼 파라미터로 설정할 수도 있다. reverse process의 expressiveness(모델이 데이터의 복잡한 구조를 얼마나 잘 표현하는지)는 pθ(xt−1∣xt)에서 가우시안 conditionals을 선택함으로 부분적으로 보장된다. 쉽게 말해서 reverse process에서 상태를 예측하는 과정이 수학적으로 잘 정의되고, 계산이 간단해지며 모델의 표현력이 어느정도 보장된다는뜻과 같다.
이는 βt가 작을때 두 과정이 동일한 함수 형태를 가지기 때문이다. forward process의 중요한 특징 중 하나는 임의의 시간 t에서 xt를 특정 수식으로 명확하게 계산할 수 있다는 것이다. αt:=1−βt 그리고 αˉt:=∏s=1tαs 이 정의를 사용해서 수식으로 명확하게 xt를 계산 할 수 있다.
q(xt∣x0)=N(xt;αˉtx0,(1−αˉt)I)(4)
모델 훈련은 L을 stochastic gradient descent로 최적화 하면서 이루어진다. (3)번 수식의 L을 재작성하여 분산을 줄임으로 식을 개선할 수 있다.
(자세한 내용은 부록 A를 참조)
식(5)는 KL발산을 사용하여 pθ(xt−1∣xt)와 forward process의 posteriors(관찰된 데이터 x0를 기반으로 변수xt−1의 분포)를 비교한다. 이 posteriors는 x0에 조건화된 경우 해석 가능하다. 이 말은 x0가 주어졌을때 xt−1의 분포를 계산하거나 이해하는 게 가능하다는 것이다.
결과적으로 식(5)의 모든 KL발산은 가우시안 분포 간의 비교이므로, 높은 분산의 몬테카를로 추정 대신 닫힌 형태(직접 계산 가능)의 표현을 사용하여 Rao-Blackwellized방식으로 계산할 수 있다. 요약하면 그냥 직접 계산 가능한 형태로 (3)번 수식을 변환했다는 얘기다.