Background: Neural machine translation
RNN Encoder-Decoder
Encoder reads the input sentence, a sequence of vectors , into a vector c. The most common approach is to use an RNN such that
is a hidden state at time t, and c is a vector generated from the sequence of the hidden states. f,q are some nonlinear func.
Decoder is often trained to predict the next word given the context vector c and all the previously predicted words
In other words, the decoder defines a probability over the translation y by decomposing the joint probability into the ordered conditionals.
where . With an RNN, each conditional probability is modeled as
where g is a nonlinear, potentially multi-layered, function that outputs the probability of , and is the hidden state of the RNN.
Learning to align and translate
The new architecture consists of a bidirectional RNN as an encoder and decoder that emulates searching through a source sentence during decoding a translation.
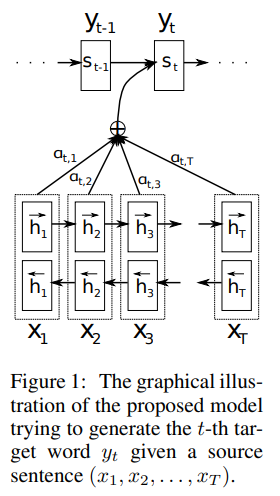
Decoder: General Description
We define each conditional probability into
where is an RNN hidden state for time i, computed by
The difference between existing encoder-decoder approach and ours is the probability is conditioned on a distinct context vector for each target word $
The context vector depends on a sequence of annotations to which an encoder maps the input sentence. Each annotation contains information about the whole input sequence with a strong focus on the parts surrounding the -th word of the input sequence.
The context vector is computed as a weighted wum of these annotations :
The weight of each annotation is computed by
where , is an alignment model which scores how well inputs around position and the output at position match. The score is based on the RNN hidden state and the -th annotation of the input sentence.
The probability ,or its associated energy , reflects the importance of the annotation with respect to the previous hidden state in deciding the next state and generating .
The decoder decides parts of the source sentence to pay attention to.
This attention mechanism, we relieve the encoder from burden of having to encode all information can be spread throughout the sequence fo annotations.
Encoder: Bidirectional RNN for annotating sequences
A BiRNN consists of forward and backward RNN's. We obtain an annotation for each word by concatenating the forward hidden state and the backward one , i.e.,
In this way, the annotation contains the summaries of both the preceding words and the following words. Due to the tendency of RNNs to better represent recent inputs, the annotation will be focused on the words around .
