Multi-level colonoscopy malignant tissue detection with adversarial CAC-UNet
Motivation
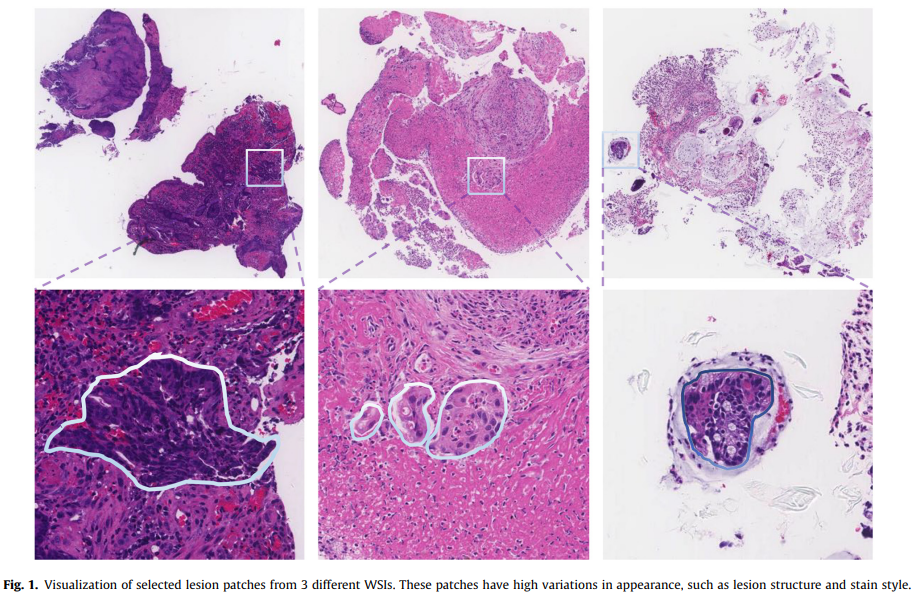
소화기계 암은 초기 단계에서 진단과 치료를 받는다면 치료 성공률이 높다.
병리과 의사가 WSI(Whole slide image)를 수작업으로 분석하는 것은 시간이 오래 걸린다.
자동 WSI 분석 모델이 초기에 암을 찾아내고 진단할수 있다면?
Related Work
- WSI down sampling
- 낮은 해상도 수준에서 RoI를 감지
- 다중 해상도 분석
- 그래프 기반 다중 해상도 접근 방식
- 문제점: 거친 WSI로 인해 정보 손실이 생겨 진단 결과가 부정확
- 패치 분할 방법
- WSI를 으로 자른 후 3층 CNN아키텍처 사용
- 모든 패치 분류 결과를 기반으로 WSI에 최종 확률 맵을 생성
- 문제점: 패치 수준의 분류 결과만 결합하여 전체 WSI 조직 분석은 부정확함, Semantic segmentation을 수행해야 함
- Semantic segmentation은 FCN을 기반으로 진행됨
- DA 기술의 종류
- 사전처리 (pre-processing)
- 도메인 적대적 네트워크 (Domain-adversarial network)
- 최근 연구 동향
- WSI->MSI 도메인 적응, 비지도 도메인 적응을 달성하려 시도
Problems
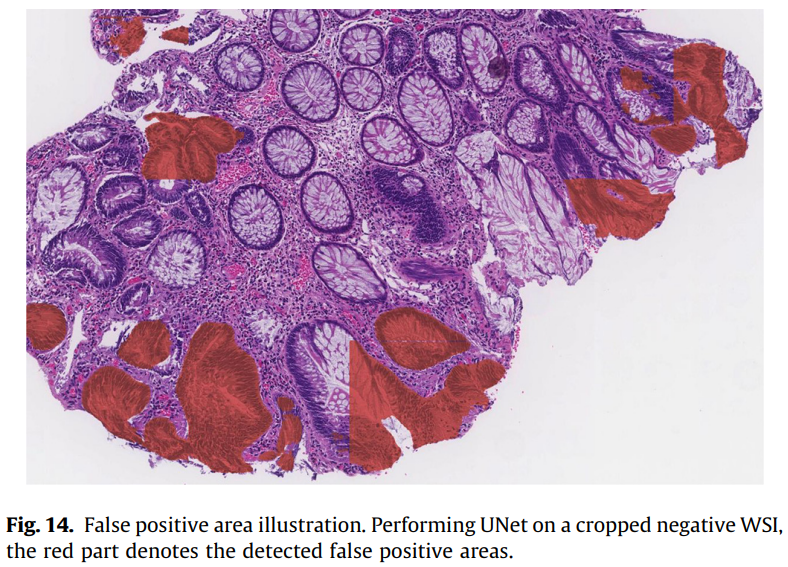
- WSI에 대해 기존의 패치 수준 segmentation을 직접 적용할 경우 False Positive의 위험을 가지고 있다. 어떻게 해결할것인가?
- Key patch가 선택되었을 때, appearance invariant image segmentation을 어떻게 수행할 것인가?
Proposed Method
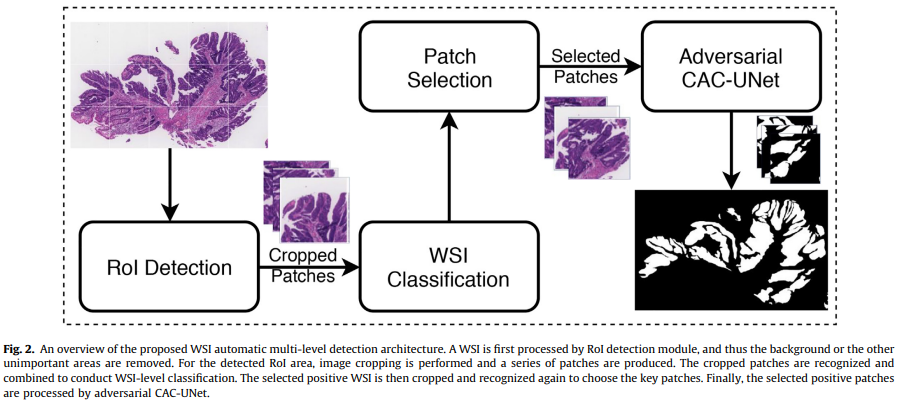
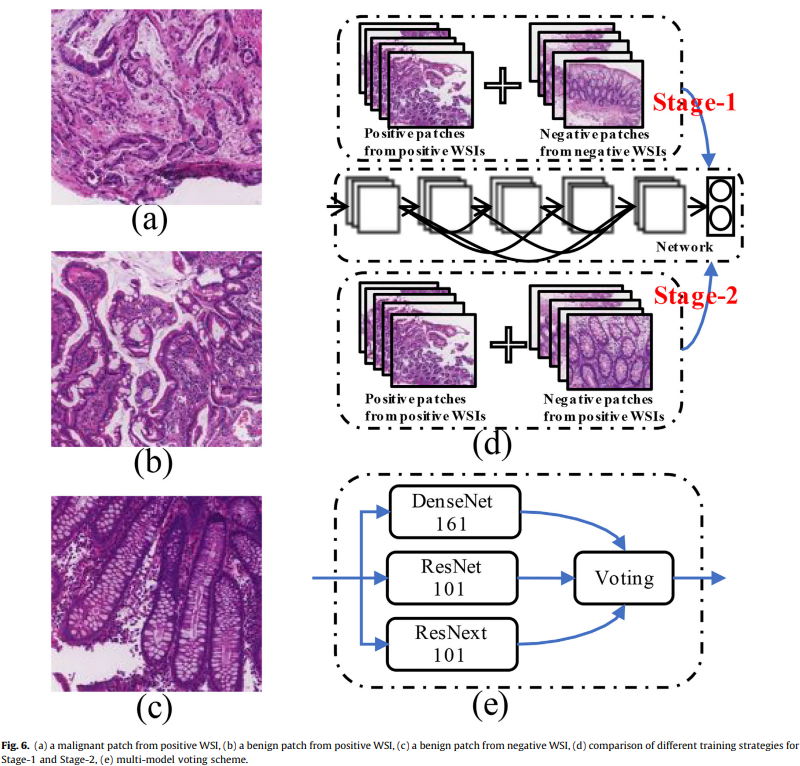
[stage-1] WSI 수준 분류
- 입력된 WSI가 malig(악성)인지 benign(양성)인지 판단 후 negative 패치를 제거함
- WSI 수준의 분류를 수행함, 분류기는 DenseNet 사용
[stage-2] Key patch selection
- 악성 WSI의 각 패치를 정밀 분류, positive patch를 key patch로 선정함
- 패치 수준 분류는 다중 모델 투표를 이용함
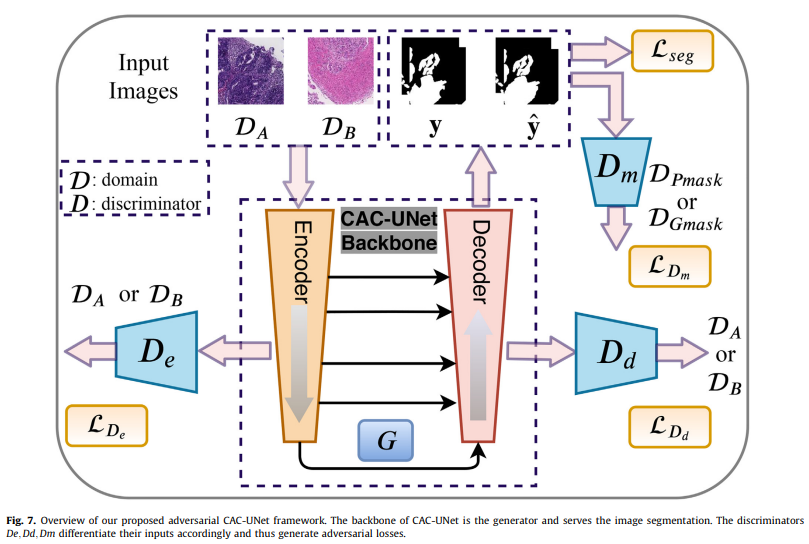
[stage-3] Adversarical CAC-UNet
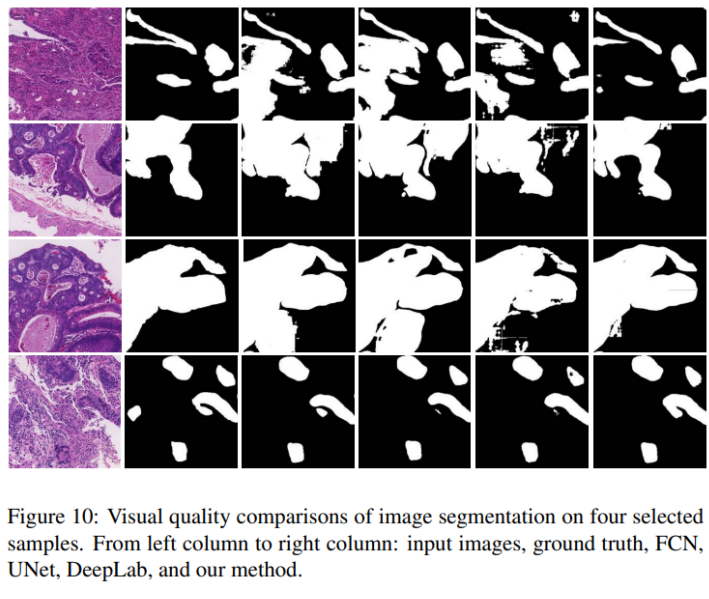
- Key patch를 segmentation하고 이를 하나의 WSI 마스크로 결합함
- segmentation을 위해 적대적 CAC-UNet설계함
[Stage-1] WSI Classification
RoI detection

RGB 값의 표준편차가 미리 정의된 임계값 R보다 작으면 해당 패치는 버려지는 식으로 ROI patch를 만든다.
WSI Classification
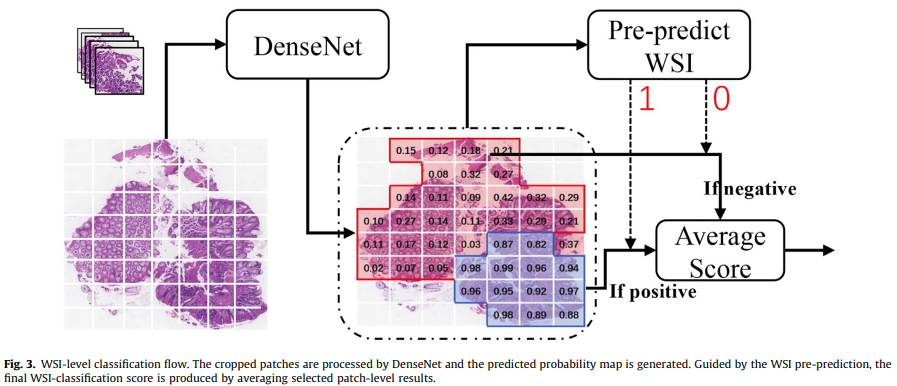
: WSI level classification score
: patch level set, all positive patch negative patches of X
: patch number in set
: pre-predicted positive, negative label
: Ground Truth
: original label distribution
: 훈련 예제
: 해당 label(k=1 pos, k=0 neg)
: smoothing 매개 변수
: 현재 패치의 malignatn 영역
: 모든 패치의 최대 malignant 영역
[Stage-2] Patch Selection
Key patch selection
[Stage-3] Adversarial CAC-UNet
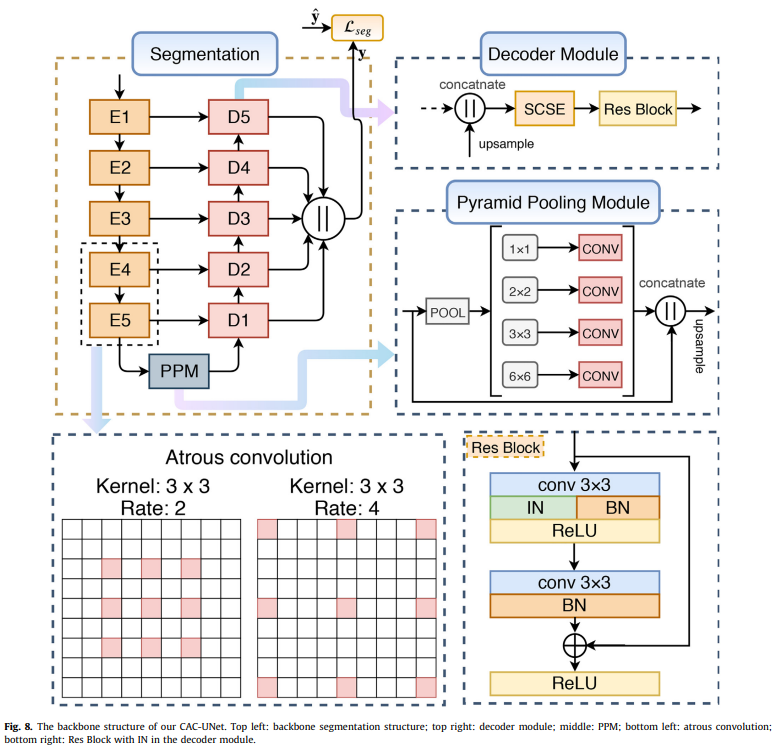
Segmentation
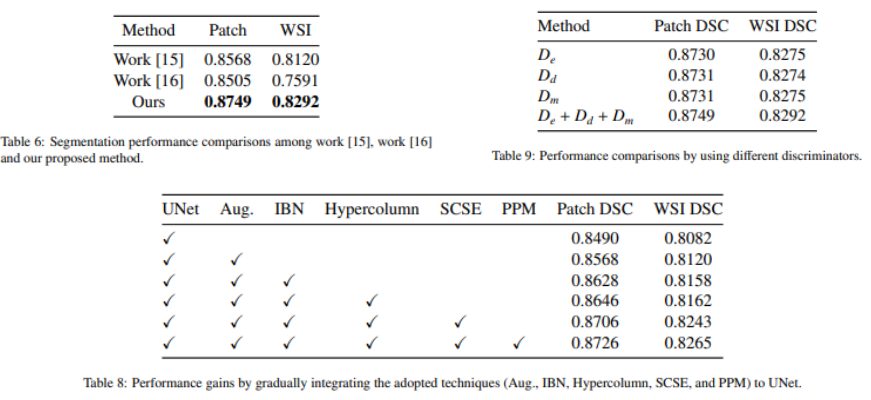
- Domain-invariant feature 학습을 진행함
- 모델의 Genralization ability 향상
- 훈련 세트를 로 나눔->
- : 모델 예측 분할 마스크, 전문가에 의해 라벨링 된 GT 마스크
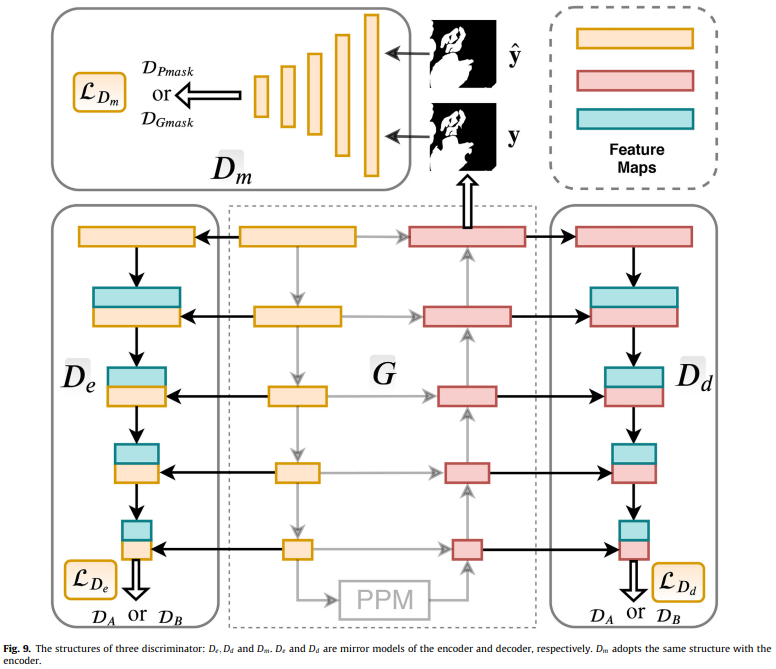
- Discriminator: CNN 기반의 일련의 분류기
- Generator: segmentation 모델 전체 또는 일부
- 예측된 분할 마스크와 GT 마스크 간의 차이를 최소화 한다.
- 인코더 feature 맵을 기반으로 도메인 이미지를 구별한다.
- 디코더 feature 맵과 에 의해 생성된 feature 맵을 기반으로 도메인의 이미지를 구별한다.
- 예측된 마스크를 GT마스크와 구별한다.
모델 구조
Domain-adversarial Learning
Training
-
𝐺 훈련: 의 이미지와 label로 부터 학습
- Invariant feature map을 사용하여 𝐺 가 더 정확히 segmentation을 수행하도록함.
- 에서 무작위로 샘플링된 패치 이미지) , (해당 패치 레이블 집합)
- 𝐿𝑠𝑒𝑔를 최소화 하여 𝐺 훈련
-
훈련: 학습된 𝐺 로부터 독립적으로 판별자 훈련
- 을 최소화함
- 초기 를 얻게 됨
-
교대로 적대적 훈련: 초기화된 G와 판별자를 적대적 훈련
- 𝐺를 업데이트 하기 위해 판별자들의 판별 결과를 이용
- 판별자들은 𝐺의 출력을 가능한 실제 레이블과 유사하도록 만듬
- 수렴할 때 까지 교대로 반복하여 훈련
- 𝐺를 업데이트 하기 위해 판별자들의 판별 결과를 이용
-
교대로 이런 훈련을 진행하면, 도메인에 따른 변동성에 invariant한 특징을 갖는 세그멘테이션 네트워크를 학습할 수 있다.
Discussion

5238D8K7