[7일차] 08.자료형(data type)-문자는 프로그램에서 어떻게 표현하여 사용하나요?
Part01. 자바 프로그래밍
ch 01. 자바 기초
08.자료형(data type)-문자는 프로그램에서 어떻게 표현하여 사용하나요?
<문자도 정수로 표현한다>
- 어떤 문자를 컴퓨터 내부에서 표현하기 위해 특정 정수 값을 정의
- ex. A는 65 (ASCII code_8bit_2의8승_256개 표현 가능, 영어 사용에 맞춰짐)
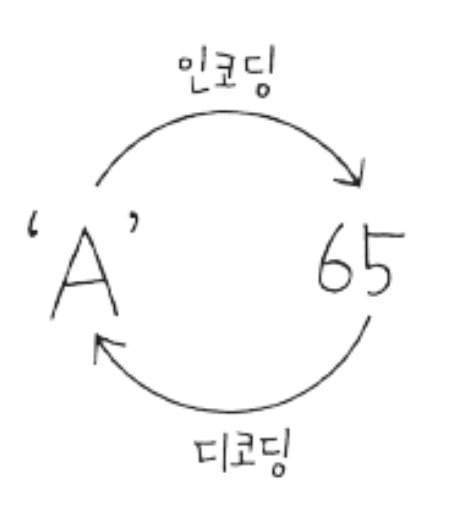
- 문자세트 : 각 문자를 얼마로 표현할 것인지 코드 값을 모아둔 것을 문자세트(Character set)라 함 ex.ASKII, euc-kr, utf-8, utf-16) == > 예시처럼 각 나라의 언어마다 다른 표현체계를 사용하면 오류가 생길 가능성이 높음
- 위와같은 문제점을 극복하고자 모든 나라의 문자를 통합하여 표준화 하기위해 UNICODE가 만들어짐
- UNICODE 종류엔 크게 utf-8 과 utf-16이 있음
-> utf-8 : 1~4byte (utf-16으로 사용했을 때 불필요한 메모리 소모를 방지하고 효율을 위해 사용함)
-> utf-16 : 모든 문자를 2byte로 표현 - UNICODE는 ASCII와 완벽하게 호환됨

<자바에서는 문자가 어떻게 표현되나요?
- 자바는 문자를 나타내기 위해 전세계 표준인 UNICODE를 사용
- utf-16 인코딩을 사용(모든 문자를 2Byte로 표시)
<문자형 변수 선언과 사용하기>
- 문자를 위한 데이터 타입 char ch = 'A';
-> 'A' : 2byte 크기의 문자 (ASCII 숫자로 표현가능)
-> "A" : 문자열(string)
'A'와 "A"는 전혀 다른 성질의 타입이다.
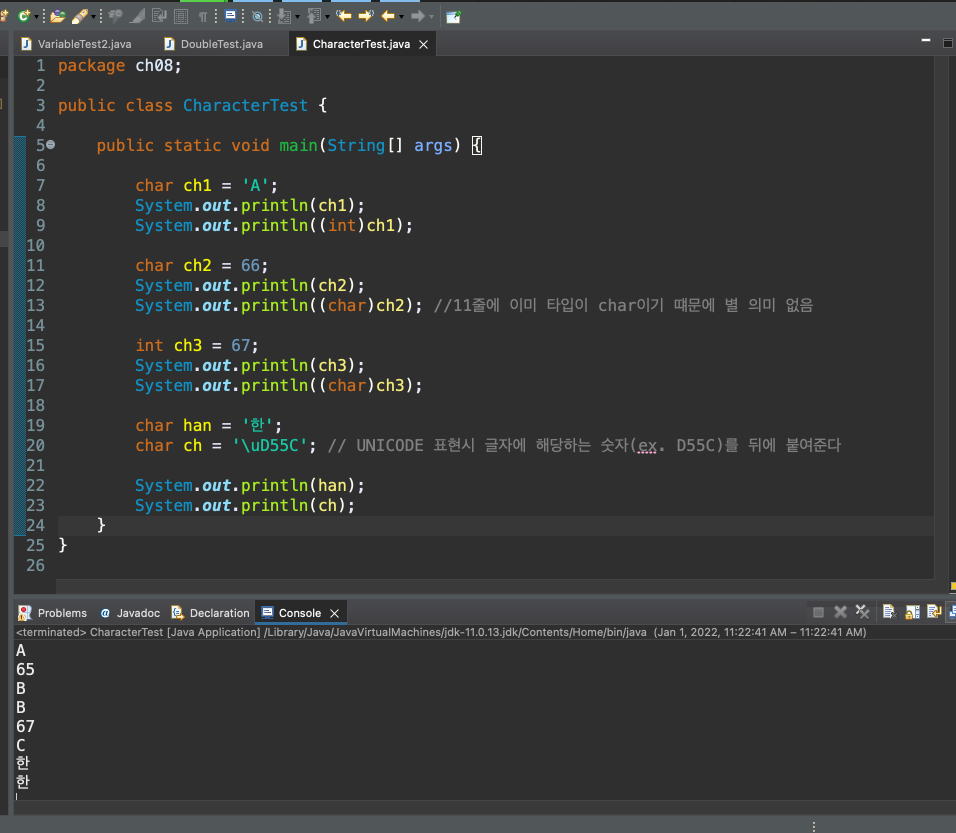
package ch08;
public class CharacterTest {
public static void main(String[] args) {
char ch1 = 'A';
System.out.println(ch1);
System.out.println((int)ch1);
char ch2 = 66;
System.out.println(ch2);
int ch3 = 67;
System.out.println(ch3);
System.out.println((char)ch3);
//char ch4 = -66; 음수는 대입 할 수 없음
char ch5 = '한';
char ch6 = '\uD55C';
System.out.println(ch5);
System.out.println(ch6);
}
}
- 결과
<용어 정리>
- character set : 문자를 숫자로 변환한 값의 세트
- encoding : 문자가 숫자로 변환되는 것
- decoding : 숫자에서 다시 문자로 변환되는 것
- ASCII code : 알파벳과 숫자, 특수문자 등을 1byte에 표현하는데 사용하는 문자 세트
- UNICODE : 전 세계 표준으로 만든 문자세트
<+ UTF에 대해 좀 더 알아보기>
- UTF는 유니코드 문자를 인코딩하는 방식을 나타낸다.
- UTF-# 는 몇 bit를 사용하여 Index를 표현할 것인가를 뜻한다.
- UTF-8은 8Bit를 사용하여 1개의 Index를 표현한다.
- UTF-16은 16Bit를 사용하여 1개의 Index를 표현한다.
- UTF-32은 32Bit를 사용하여 1개의 Index를 표현한다.
<.UTF-8>
- UTF-8의 코드 단위는 8bit이다.
- UTF-8은 인터넷 대부분에서 기본적으로 사용되는 인코딩 방식이다.
- UTF-8은 유니코드를 위한 가변 길이 문자 인코딩 방식 중 하나이다.
- UTF-8은 유니코드 한 문자를 나타내기 위해 1byte ~ 4byte까지 사용한다.
사실은, 6byte까지 사용하지만 일반적인 문자는 3byte 내로 처리되며 4byte 영역에는 이모티콘 같은 문자가 존재한다. 사실상 4byte 이상의 문자를 사용하는 경우가 없다보니 1~4byte를 사용한다고 말한다.
* 영문 byte 수 : 1byte
* 한글 byte 수 : 3byte
<.UTF-16>
- UTF-16의 코드 단위는 16bit이다.
- 주로 사용되는 기본다국어 평면(BMP_Basic Multilingual plane)에 속하는 문자들은 그대로 16bit값으로 인코딩 되고, 그 이상의 문자는 특별히 정해진 방식으로 32bit로 인코딩된다.
- UTF-16 인코딩은 유니코드 한 문자를 나타내기 위해 2byte ~ 4byte까지 사용한다.
* 영문 byte 수 : 2byte
* 한글 byte 수 : 2byte
<.UTF-8 vs UTF-16>
-
문자 하나를 표현하기 위한 필요 bit크기
UTF-8 : 8bit
UTF-16 : 16bit -
문자 하나를 표현하기 위한 필요 byte 크기
UTF-8 : 1byte ~ 4byte
UTF-16 : 2byte ~ 4byte
참고 사이트 : https://goodgid.github.io/Unicode-And-UTF-Encoding/
오늘의 공부 소감 :
강의에서 대략적으로 짚고 넘어가는 부분들을 따로 찾아보게 되고, 점점 쓸게 많아지는 것 같다...

back-end enginneer