Seq2Seq 모델은 RNN의 유형 중 many to many를 사용하는 모델이다.
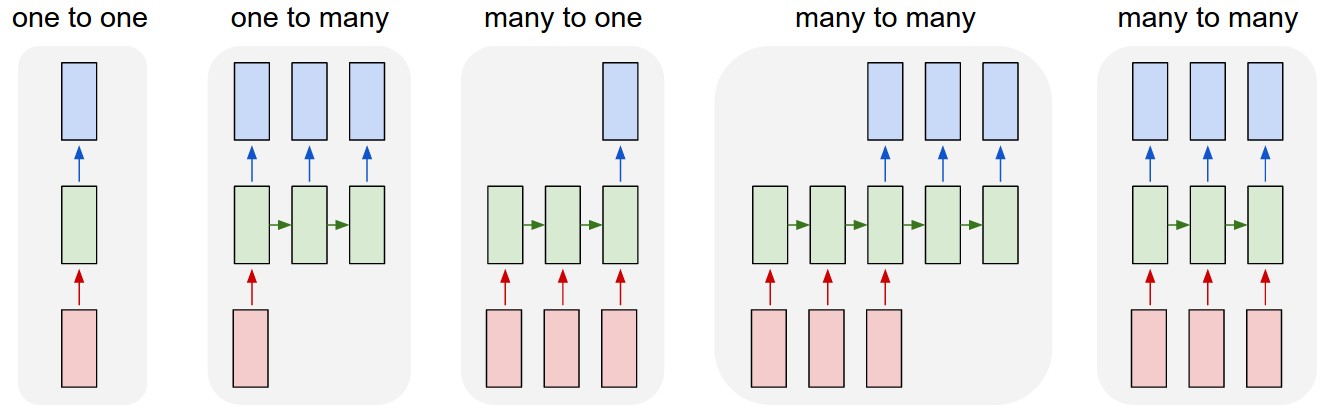
attention은 RNN이 가진 문제(인코더의 끝단에 갈수록 병목 현상 및 정보 손실 문제)를 해결하기 위해 나온 idea이다. many to many model은 그림에서 볼 수 있듯이 신경망 기계 번역(Neural machine translation, NMT)에서 많이 사용된다. 그렇다 보니 보통 인코더의 첫 단어는 디코더의 첫 단어와 연관이 깊은 반면 인코더의 시작은 인코더 끝단(혹은 디코더의 시작)에 가서는 그 정보가 손실된다. 즉, 디코더의 첫 부분부터 잘못된 예측을 할 가능성이 높아진다(이를 해결하기 위한 trick으로 인코더의 sequence를 아예 반대 방향으로 넣어주기도 했다). 이는 곧 Sequence data를 다루는데에 큰 영향을 끼치므로 이를 해결하기 위해 attention이라는 개념이 나온 것으로 보인다.
나에게 attention은 사실 이 이후의 모델인 transformer에서 더 먼저 배웠지만 그 시작은 Seq2Seq이므로 이를 알아볼 필요가 있다. Seq2Seq model with attention은 모델의 입력으로 들어오는 단어들에 대해 attention score를 매김으로써 병목 현상을 해소한다. 더 정확하게는 인코더의 모든 단어들과 모델이 계산하려 하는 그 디코더의 단어마다 어떠한 연산(dot, general, concat)을 통해 attention score를 매기고 디코더의 다음 예측 즉 출력에 이를 반영한다. 이로써 각각의 decoder가 얻은 출력은 인코더의 각 단어들을 참고하고 이를 통해 정보 손실 문제 뿐 아니라 backward propagation에서 생기는 gradient vanishing 및 exploding을 해결할 수 있었다. 추가적으로 attention map을 통해 각 decoder의 과정마다 어떤 단어에 초점을 맞추는 지 확인할 수 있는데, 이는 곧 우리가 모델을 더 심도있게 바라볼 수 있게 만든다. 기존의 머신 러닝 모델은 입력과 그 결과를 통해서만 그 모델을 해석했다면, attention mechanism은 각각의 decoder 단계에서 모델을 해석할 수 있게 만들었다.
위에서 말한 어떠한 연산에는 여러 가지가 있지만 dot, general, concat score만 설명하려 한다. dot은 말 그대로 인코더와 디코와의 내적으로 그 score를 매기는 것을 의미한다. 내가 이 dot score를 처음 봤을 때 겨우 내적으로 두 단어의 연관성(attention score)을 나타내는 것은 부족하다고 느꼈다. 그래서 이를 보정하기 위해 general score가 나타난 것으로 보인다. general score는 인코더와 디코더의 내적을 하기 전에 W 행렬을 곱하여 attention score를 매긴다. 즉 기존의 dot score는 general score 관점에서 보면 인코더와 디코더의 내적 연산 전에 인코더에 identity matrix를 곱한 후에 디코더와의 내적이다. general score는 W 행렬의 곱을 통해 attention score를 얻기 때문에 backward과정에서 이 W 행렬 또한 학습을 통해 변경된다. 마지막으로 concat score는 인코더와 디코더 벡터를 concat한 후 W 행렬 연산, tanh 활성화 함수, 다시 이 값을 스칼라로 반환할 수 있는 행렬(벡터)을 곱함으로써 얻을 수 있다.

sequence modeling 발전의 역사를 보자면
1. 단일 LSTM을 이용한 seq2seq
2. Bi-directional seq2seq
3. ELMO
4. BERT
정방향 -> 양방향 -> 모든 관계 요런식으로 발전 했었습니다.
한 방향으로만 데이터를 볼 경우 정방향 + 양방향을 한다고 하더라도 제일 처음에 있는 단어와 제일 끝에 있는 단어의 관계를 파악할 수가 없었습니다.
그래서 attention is all you need 에서는 한 단어와 다른 모든 단어들의 관계를 보기 시작했습니다.
이러면서 계산해야 할 연산량이 많아지게 되었습니다!