대회 링크: https://dacon.io/competitions/official/236033/overview/description
이전 학습 결과를 보면 제대로 학습이 되지 않는 문제가 발생했다. 그 때 써놓았던 문제점을 해소하기 위해 먼저 데이터셋의 구성을 변경했다.
데이터셋 구성 변경
기존 Dataset은 (hour, feature), (weight) 쌍으로 되어 있었다.
(즉, 하루 동안 15개의 feature들이 한시간마다 기록된 data와 그 날의 상추 무게가 label인 data, label 쌍)
이를 수정하여 (day, hour, feature), (hour, weight) 쌍으로 변경했다.
(즉, 하나의 상추에 대해서 28일 간의 데이터를 모두 하나로 묶어 데이터셋으로 구성)
각각 data, label의 차원을 숫자로 나타내면 다음과 같다.
기존: (24, 15), (1)
수정: (28, 24, 15), (28, 1)
데이터셋 수정 이점
- 이렇게 데이터셋을 수정하여 얻은 이점은 상추가 28일 간 성장하는 시계열 데이터를 섞이지 않은 상태로 이용할 수 있다는 점이다.
(기존에는 단순히 하루 동안의 feature와 그 날의 무게가 데이터셋의 한 쌍이라 시계열 데이터 특징을 전혀 이용하지 않았다.)
물론 shuffle을 하지 않고 batch size를 28의 배수로 설정한다면 이를 우회할 순 있긴 하지만 일반적인 방법이라 생각되진 않는다.
모델 개선
데이터셋을 변경했으니 다음은 모델 개선이다.
기존의 baseline의 LSTM과 FC layer를 이어붙인 모델을 그대로 재활용하여, 모델을 개선하였다.
기존 baseline 모델
class BaseModel(nn.Module):
def __init__(self):
super(BaseModel, self).__init__()
self.lstm = nn.LSTM(input_size=15, hidden_size=256, batch_first=True, bidirectional=False)
self.classifier = nn.Sequential(
nn.Linear(256, 1),
)
def forward(self, x):
hidden, _ = self.lstm(x)
output = self.classifier(hidden[:,-1,:])
return output개선된 모델
class BaseModel(nn.Module):
def __init__(self):
super(BaseModel, self).__init__()
self.lstm_model_list = nn.ModuleList([
nn.LSTM(input_size=16, hidden_size=256, batch_first=True, bidirectional=False) for _ in range(28)
])
self.linear_model_list = nn.ModuleList([
nn.Linear(256, 1) for _ in range(28)
])
def forward(self, x):
# x : (batch_size, day, hour, feature) - (N, 28, 24, 15)
prev_weights = [0] * CFG['BATCH_SIZE']
output_weights = torch.Tensor().to(device)
for lstm_model, linear_model, chunks in zip(self.lstm_model_list, self.linear_model_list, torch.chunk(x, 28, dim=1)):
# chunk : (1, 24, 15)
input_tensor = torch.Tensor().to(device)
for chunk, prev_weight in zip(chunks, prev_weights):
prev_weight_tensor = torch.Tensor(24).fill_(prev_weight).view(1, -1, 1).to(device)
x = torch.cat([chunk, prev_weight_tensor], dim=-1)
input_tensor = torch.cat([input_tensor, x], dim=0)
output, _ = lstm_model(input_tensor) # x : (N, 24, 16)
weights = linear_model(output[:, -1, :]) # weights : (N, 1)
output_weight = weights.unsqueeze(dim=1)
prev_weights = weights.squeeze(dim=1)
output_weights = torch.cat([output_weights, output_weight], dim=1)
return output_weights중간중간 tensor의 차원이 헷갈려서 주석으로 작성했다. N은 batch_size를 의미한다.
개선된 모델 코드가 기존의 baseline 모델 코드보다 훨씬 길어지긴 했지만, 결국에는 LSTM과 FC layer를 이어붙인 점은 같다.
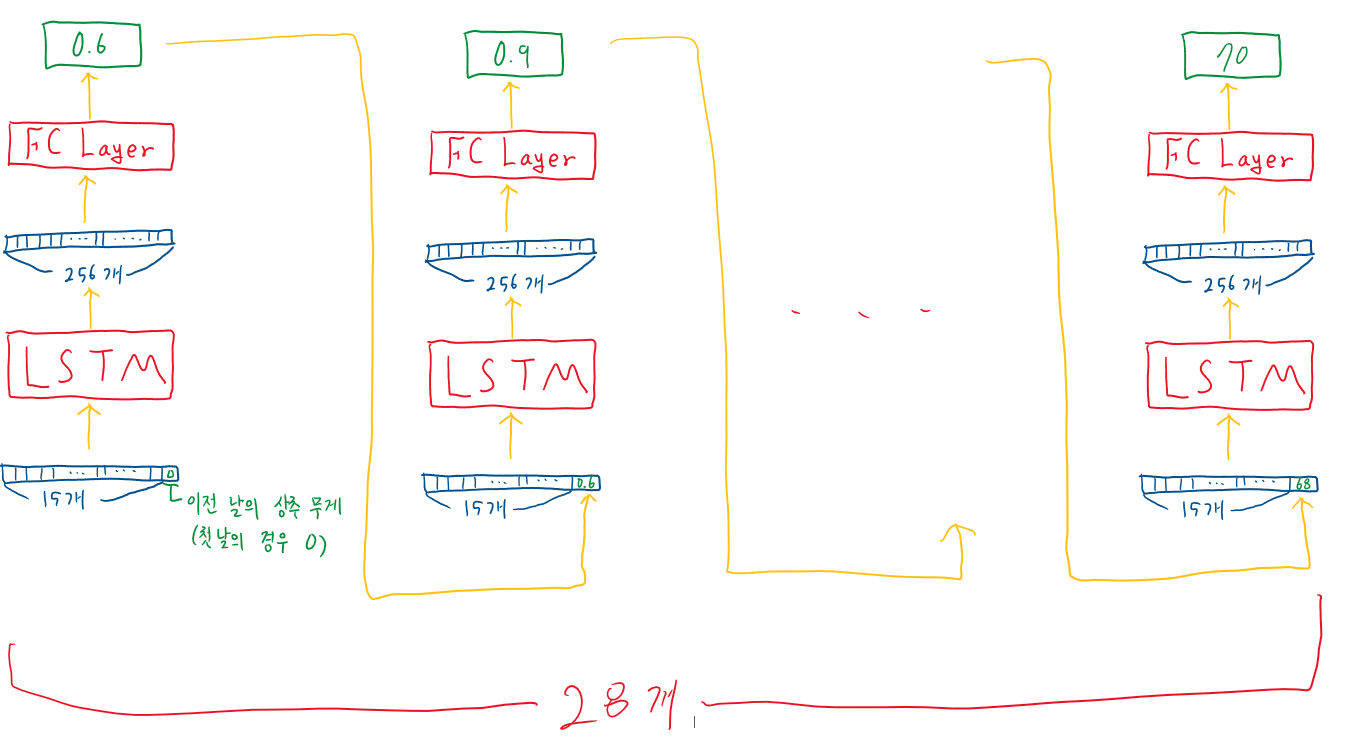
하지만 LSTM의 input_size를 15에서 16으로 증가시켜 이전 상추의 무게를 feature에 추가할 수 있도록 LSTM 모델을 수정하였으며, 날마다 서로 다른 LSTM과 FC layer를 사용한다는 점이 다르다. 즉, 총 28개의 LSTM 모델, 28개의 FC layer 모델을 사용한다.
모델을 그림으로 그리면 다음과 같다.
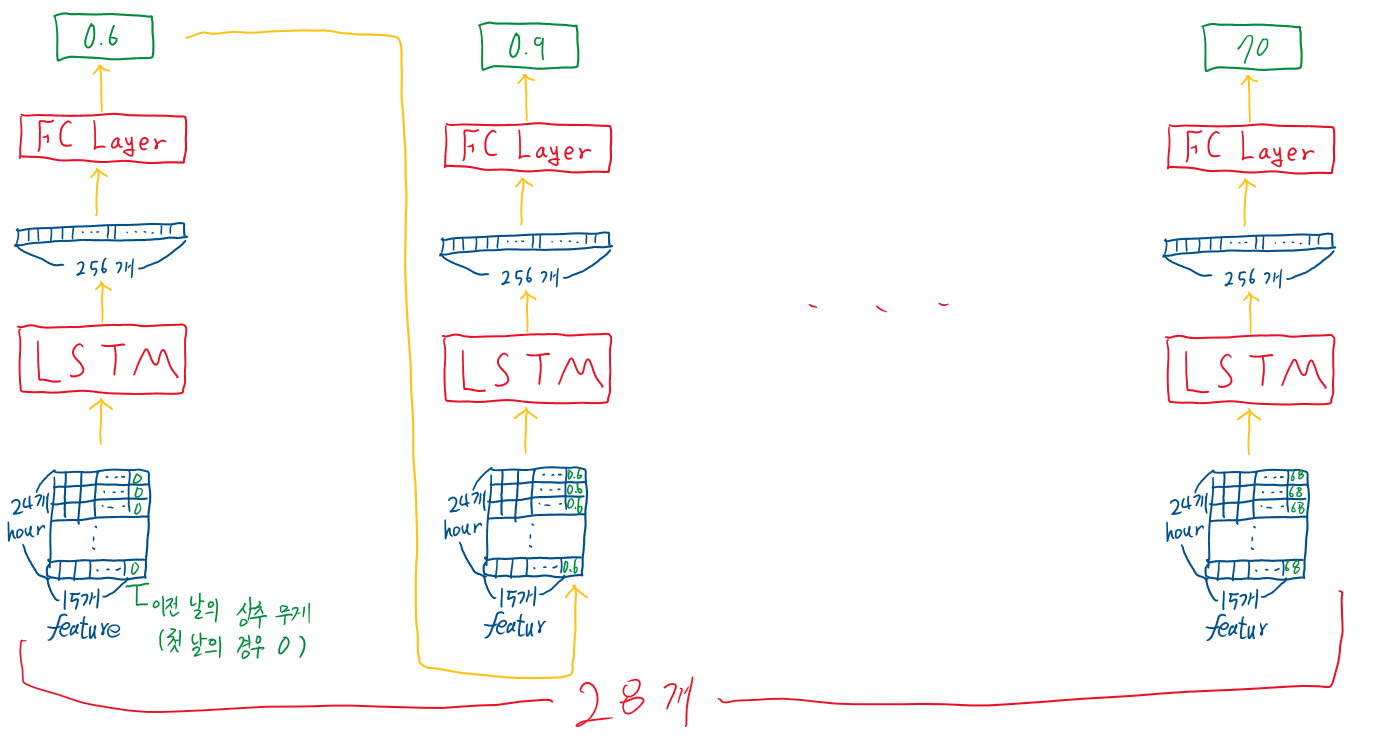
24시간 동안 15개의 feature의 data에 이전 날의 상추 무게까지 concat하여 LSTM에 input으로 준 후, 그 결과를 다시 FC layer에 input으로 주어 그 날의 무게를 예측한다. 그리고 예측한 무게를 다음 input의 feature에 concat하여 LSTM에 input으로 주는 것을 28번 반복하여 최종 무게를 예측하는 모델이다.
학습 결과
다음은 데이터셋과 모델을 변경하여 얻은 학습결과이다.
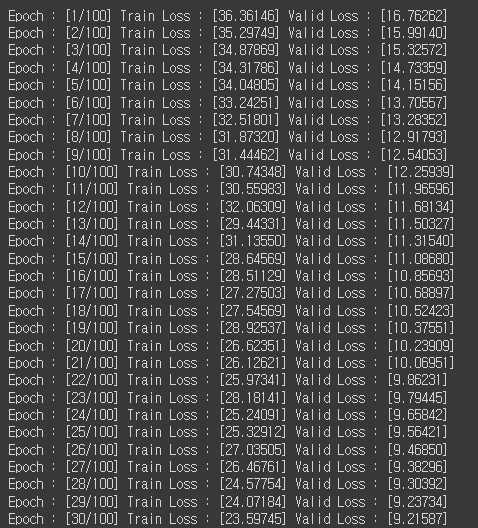
확실히 기존 baseline과는 다르게 train loss와 valid loss가 지속적으로 감소하는 것을 확인할 수 있었다.
