1. nbytes
ndarray object의 메모리 크기 반환
print(np.array([[1,2,3], [4.5, "5", "6"]], dtype=np.float32).nbytes)
# float32 -> 32bits == 4bytes -> 6*4 bytes
>>> 24
print(np.array([[1,2,3], [4.5, "5", "6"]], dtype=np.int8).nbytes)
>>> 6
print(np.array([[1,2,3], [4.5, "5", "6"]], dtype=np.float64).nbytes)
>>> 482. handling shape
2.1 reshape()
array의 크기를 변경, element의 갯수는 동일
reshape의 변수로 -1을 입력하면, 다른 숫자에 맞춰 자동으로 reshape됨
test_matrix = np.array([[1,2,3,4], [1,2,5,8]])
print(test_matrix)
>>> (2, 4)
print(test_matrix.reshape(8,))
>>> array([1, 2, 3, 4, 1, 2, 5, 8])
print(test_matrix.reshape(-1,2).shape)
>>> (4, 2)2.2 flatten()
다차원 array를 1차원 array로 변환
3. slicing
list와 달리 행과 열 부분을 나눠서 slicing이 가능
[] 안에 쉼표(,)를 기준으로 행과 열을 구분
a = np.array([[1,2,3,4,5], [6,7,8,9,10]], int)
a[:, 2:] # 전체 행의 2열 이상
a[1, 1:3] # 1 행의 1열~2열
a[1:3] # 1행~2행의 전체4. creation function
4.1 arange()
array의 범위를 지정하여, 값의 list 생성
np.arange(end) # 0부터 end - 1까지 간격 1로 list 생성
np.arange(start, end) # start부터 end - 1까지 간격 1로 list 생성
np.arange(start, end, step) # start부터 end - 1까지 간격 step으로 list 생성4.2 eye()
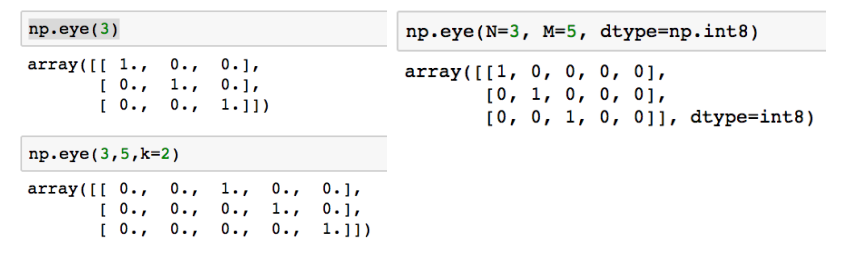
정사각행렬이 아닌 대각 행렬 생성 가능, k값으로 시작 index 변경 가능
4.3 random sampling
데이터 분포에 따른 sampling으로 array를 생성
np.random.uniform(0, 1, 10) # 균등분포(start, end, # of samples)
np.random.normal(0, 1, 10) # 정규분포(mean, standard deviation, # of samples)5. axis
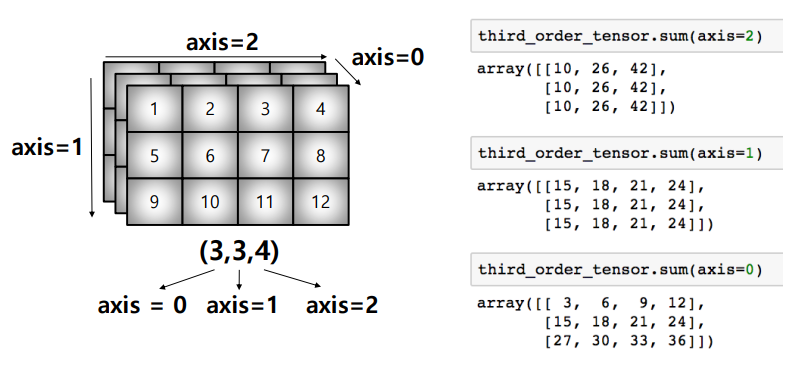
모든 operation function(sum, mean, std)을 실행할 때 기준이 되는 dimension 축

6. comparison operation
6.1 any&all
array의 데이터의 조건에 만족 여부 반환
a = np.arange(10)
print(a)
>>> array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
print(np.any(a>5), np.any(a<0))
>>> (True, False)
print(np.all(a>5), np.all(a<10)
>>> (False, True)6.2 comparison
배열의 크기가 동일할 때 element간 비교의 결과를 boolean type으로 반환
test_a = np.array([1, 3, 0])
test_b = np.array([5, 2, 1])
test_comparison = test_a > test_b
print(test_comparison)
>>> array([False, True, False], dtype=bool)
print(test_comparison.any())
>>> True
print(test_comparison.all())
>>> False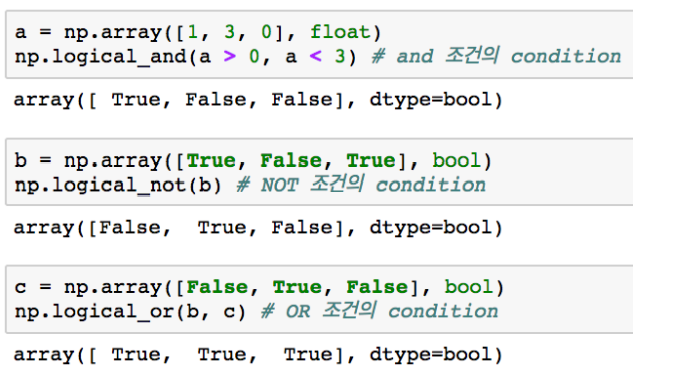
6.3 where()
a라는 array에 대해,
np.where(condition of a): 조건에 맞는 인덱스 반환
a = np.arange(10, 20)
print(np.where(a>15))
>>> (array([6, 7, 8, 9]),)np.where(condition of a, A, B): 조건에 맞을 경우 A, 아닐 경우 B를 대입한 array 반환
print(np.where(a>15, "A", "B"))
>>> array(["B", "B", "B", "B", "B", "B", "A", "A", "A", "A"])7. boolean & fancy index
특정 조건에 따른 값을 배열 형태로 추출
test_array = np.array([1, 4, 0, 2, 3, 8, 9, 7], float)
print(test_array > 3)
>>> array([False, True, False, False, False, True, True, True], dtype=bool)
print(test_array[test_array > 3]) # 조건이 True인 index의 element만 추출
>>> array([4., 8., 9., 7.])array를 index value로 사용 가능
test_array = np.array([2, 4, 6, 8], float)
index_value = np.array([0, 0, 1, 3, 2, 1], int) # 반드시 int로 선언
print(test_array[index_value]) # test_array.take(index_value)와 같음
>>> array([2., 2., 4., 8., 6., 4.])matrix 형태의 데이터도 가능
test_array = np.array([[1, 4], [9, 16]], float)
row_index = np.array([0, 0, 1, 1, 0], int)
column_index = np.array([0, 1, 1, 1, 1], int)
print(test_array[row_index, column_index])
>>> array([1., 4., 16., 16., 4.])