
부분범위 처리
DBMS는 클라이언트에게 데이터를 전송할때 일정량 나누어 전송하는데, 여기서 클라이언트가 매번 추가로 Fetch Call을 한다.
대용량 데이터를 부분범위 처리를 하면 빠르게 결과를 얻을 수 있다.
만약, 아래의 쿼리를 실행하면 데이터를 언제 볼 수 있을까?
select * from flow_user이 쿼리로 얻는 데이터는 즉각적으로 결과를 받을 수 있다. 그 이유는 DBMS가 데이터를 모두 읽어 한번에 전송하지 않고, 일부 데이터 일정량(Array Size)을 전송하고 멈추기 때문이다.
(데이터를 전송하고 나면 서버 프로세스는 CPU를 OS에 반환하고 대기큐에서 잠을 잠.)
그다음 클라이언트로부터 Fetch Call을 받으면 다시 대기 큐에서 나와 일정량 전송한다.
이렇게 사용자로부터 Fetch Call이 있을때 데이터 일정량을 나누어 전송하는 것이 '부분범위 처리'
전체 범위 처리
만약 아래의 쿼리는 언제 데이터를 볼 수 있을까?
select * from flow_user order by user_idorder by를 하면 user_id로 sort 해야 결과를 받을 수 있기 때문에 이것은 "전체 범위 처리"이다.
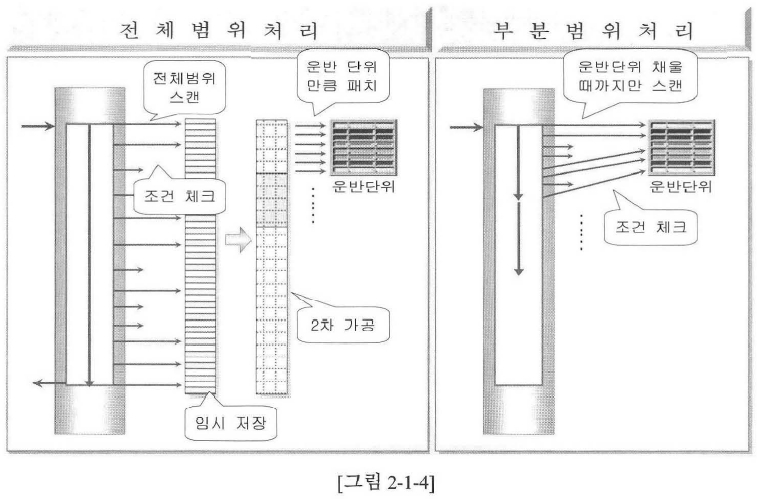
- 전체 범위 처리 : 풀 스캔 후 가공하여 Array Size(운반 단위) 만큼 추출되어야 결과를 얻음
- 부분 범위 처리 : 조건을 만족하는 Row 수가 Array Size에 도달되면 결과를 얻음
Array Size 조정을 통한 Fetch Call 최소화
Array Size는 전송해야 할 데이터량에 따라 조절해야한다.
- 모두 전송해야하는 대량의 데이터 : Array Size 크게해서 Fetch Call을 줄인다.
- 앞쪽 일부 데이터만 Fetch하는 데이터 : Array Size를 작게 해서 불필요하게 전송하고 버려지는 데이터를 줄인다.
쿼리툴에서 부분처리
쿼리툴에서 Array Size를 조절하는 옵션이 있다. 쿼리툴마다 다름.
부분범위 처리 구현
책 164 page에 예시가 있는데, 책에서는 프레임워크에 다 구현되어있으니 가져다 쓰라고 한다.
OLTP 환경에서 부분범위 처리에 의한 성능개선 원리
OLTP는 'Online Transaction Processing'의 줄임말
- OLTP는 소량의 데이터를 읽고 갱신한다. (항상 소량 데이터만 조회하는 것은 아님)
- OLTP는 특정한 정렬 순서로 상위 일부 데이터만 확인한다.
- 인덱스와 부분범위 처리 원리를 활용하면 OLTP 환경에서 극적인 성능 개선 효과를 얻을 수 있다.
부분범위 처리 유도
쿼리 뒷쪽에 order by를 사용하여 부분처리를 유도하지 못한다면, 인덱스를 사용하여 order by를 생략해 부분 범위 처리를 유도할 수 있다.
-- 전체 범위 처리
select * from [user]
where reg_date between '2020-04-09' and '2020-04-10'
order by reg_date
-- 부분 범위 처리
select * from [user]
with(index(idx_reg_date))
where reg_date between '2020-04-09' and '2020-04-10'-- 전체 범위 처리
select max(reg_date) from [user]
-- 부분 범위 처리
select top 1 reg_date
from [user] with(index(idx_reg_date))전체 범위 처리는 전체를 처리하여 레포팅 하는 것에 적합하고 부분 범위 처리는 온라인으로 결과를 출력할때 즉, 반응이 빨라야 할때 사용하는 방법입니다.
부분 범위 처리가 전체 범위 처리 보다 시간이 더 오래 걸릴 수도 있으므로 용도에 맞게 써야 합니다.
출처 : https://devjino.tistory.com/105
배치 I/O
배치 I/O는 읽는 블록마다 건건이 I/O Call을 발생시키는 비효율을 줄이기 위해 고안된 기능이다.
