
인덱스 탐색
-- 조건절 1
where C1 = 'B'
-- 조건절 2 (스캔량 줄임)
where C1 = 'B'
and C2 = 3
-- 조건절 3 (스캔량 줄임)
where C1 = 'B'
and C2 >= 3
-- 조건절 4 (스캔량 줄임)
where C1 = 'B'
and C2 <= 3
-- 조건절 5 (스캔량 줄임)
where C1 = 'B'
and C2 between 2 and 3
-- 조건절 6 (스캔량 줄이는데 역할 못함)
where C1 = between 'A' and 'C'
and C2 between 2 and 3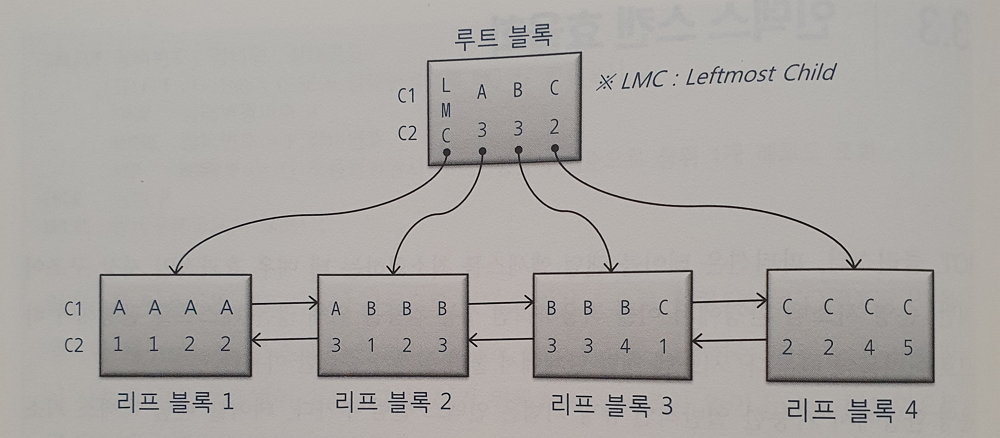
인덱스 스캔 효율성
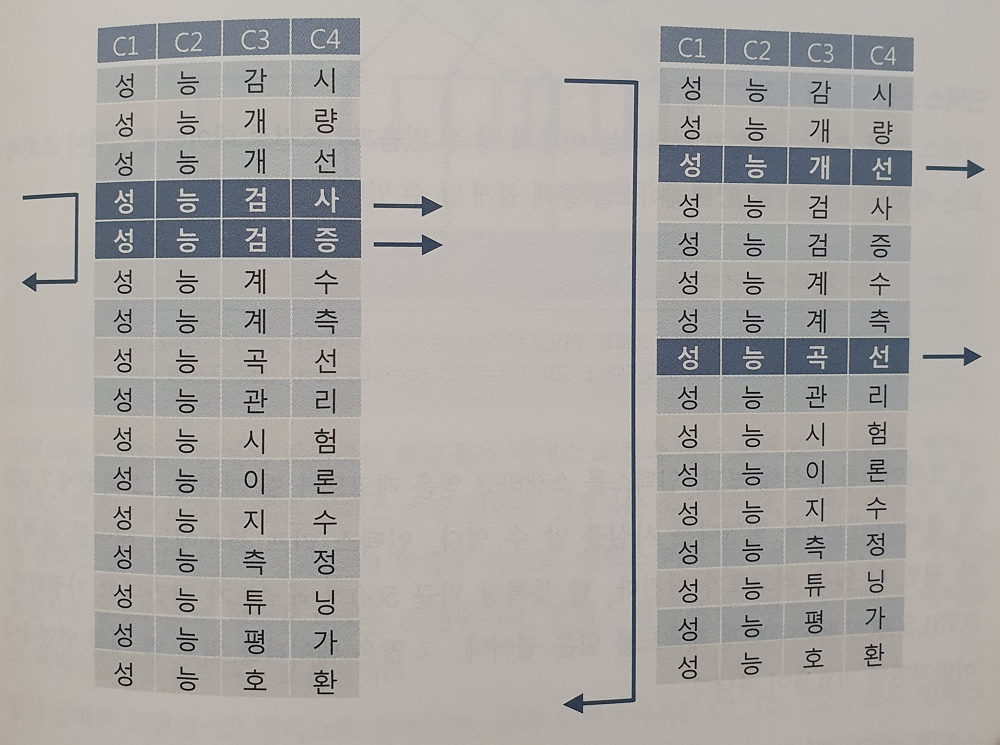
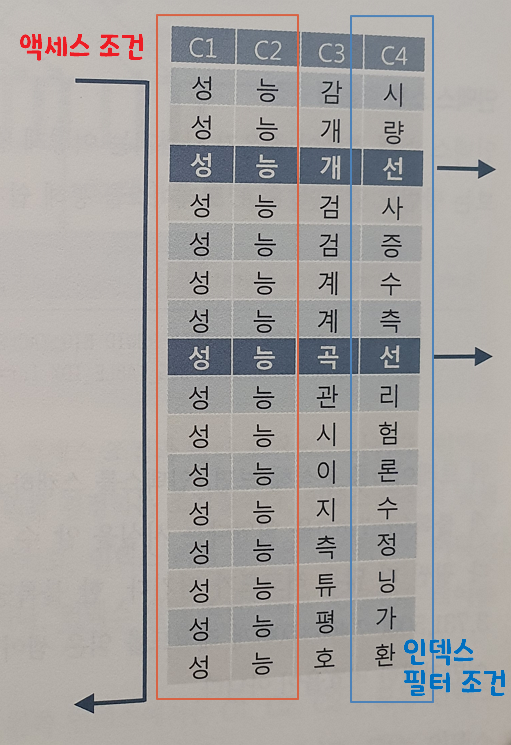
액세스 조건과 필터 조건
액세스 조건
- 인덱스 스캔 범위를 결정하는 조건절이다.
- 스캔 시작점과 인덱스 리프 블록을 스캔하다가 어디서 멈출지를 결정하는데 영향을 미치는 조건절이다.
필터 조건
- 테이블로 액세스할지를 결정하는 조건절이다.
옵티마이저의 비용 계산 원리
비용
= 인덱스 수직적 탐색 비용 + 인덱스 수평적 탐색 비용 + 테이블 랜덤 액세스 비용
= 인덱스 루트와 브랜치 레벨에서 읽는 블록 수 + 인덱스 리프 블록을 스캔하는 과정에서 읽는 블록 수 + 테이블 액세스 과정에서 읽는 블록 수
비교 연산자 종류와 컬럼 순서에 따른 군집성
테이블과 달리 인덱스는 같은 값을 갖는 레코드들이 군집해 있음.
첫번째 나타나는 범위검색 조건까지만 만족하는 인덱스 레코드는 모두 연속해서 모여 있지만, 그 이하 조건까지 만족하는 레코드는 비교 연산자 종류에 상관없이 흩어진다.
where C1 = 1 and C1 = 'A' and C3 = '나' and C4 = 'a'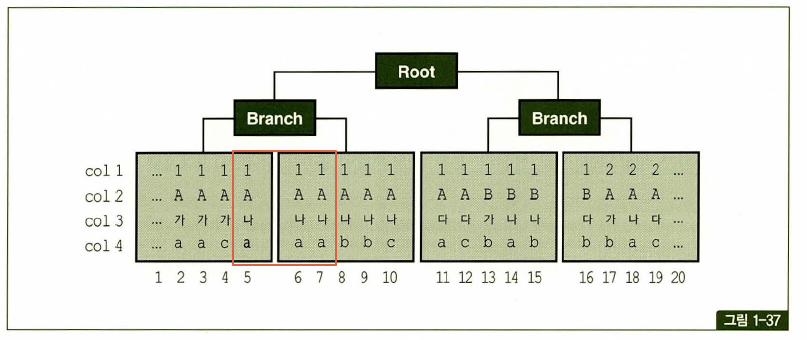
where C1 = 1 and C1 = 'A' and C3 = '나' and C4 >= 'a'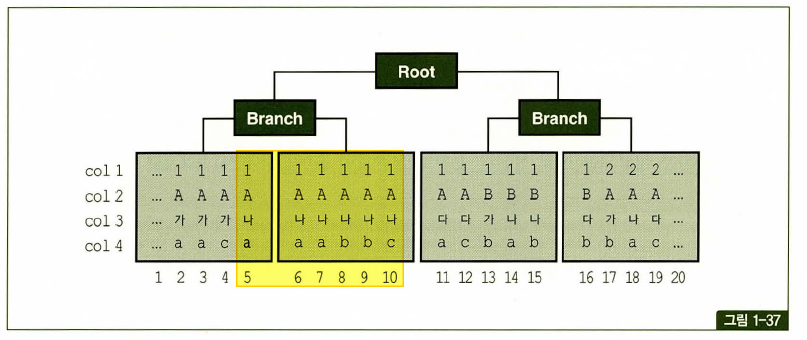
where C1 = 1 and C1 = 'A' and C3 between '가' and '다' and C4 = 'a'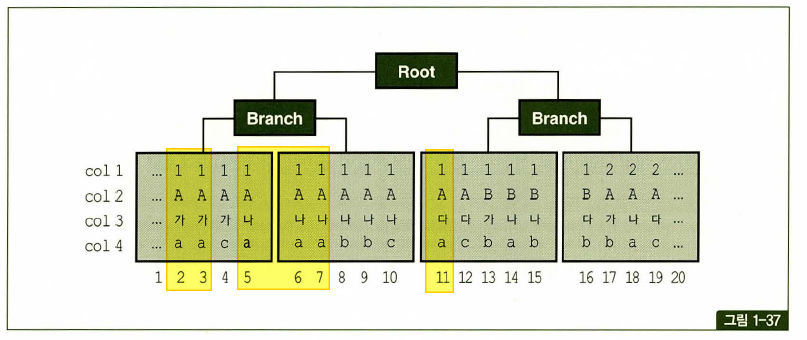
where C1 = 1 and C1 <= 'B' and C3 ='나' and C4 between 'a' and 'b'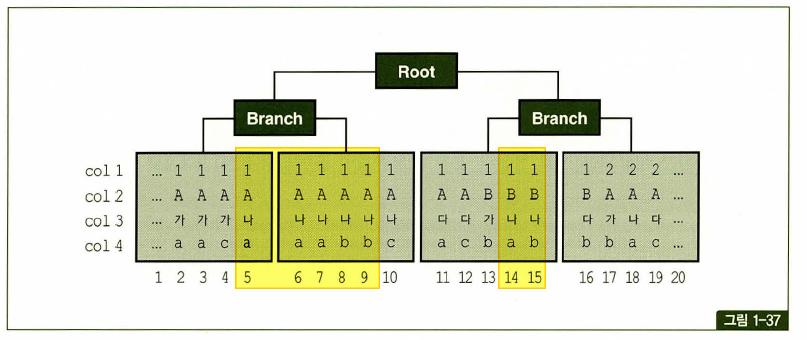
인덱스 선행 컬럼이 등치(=) 조건이 아닐 때 생기는 비효율
인덱스 컬럼을 조건절에 모두 등치(=) 조건으로 사용할 때 효율이 가장 좋다.
where 아파트시세코드 = :a
where 아파트시세코드 = :a and 평형 = :b
where 아파트시세코드 = :a and 평형 = :b and 평형타입 = :c
where 아파트시세코드 = :a and 평형 = :b and 평형타입 between :c and :d반면, 인덱스 선행 컬럼이 조건절에 없거나 부등호, BETWEEN, LIKE 같은 범위검색 조건이면, 인덱스를 스캔하는 단계에서 비효율이 발생
select 해당층, 펑당가, 입력일, 해당동, 매물구분, 연사용일수, 중개업소코드
from 매물아파트매매
where 아파트시세코드 'A01011350900056'
and 평형 = '59'
and 평형타입 = 'A'
and 인터넷매물 between '1' and '3'
order by 입력일 desc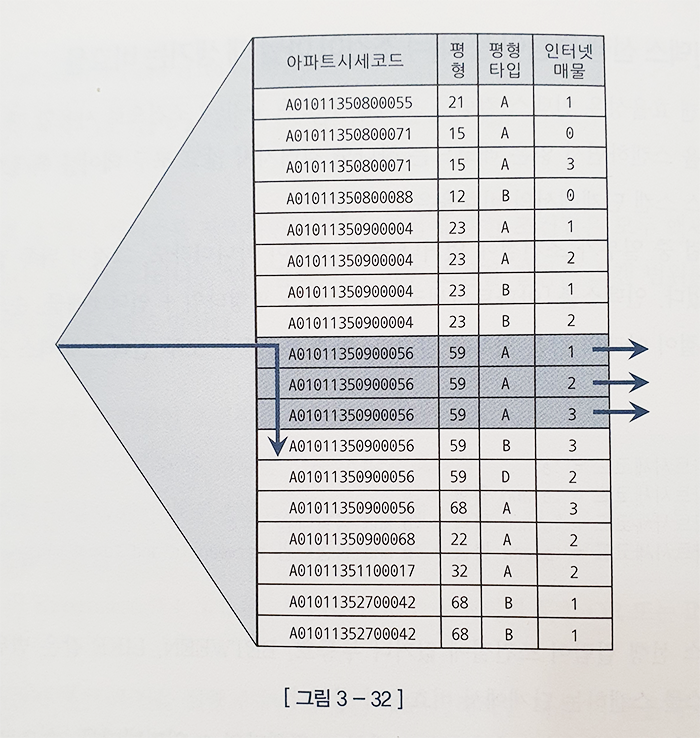
- 인덱스 : 아파트시세코드 + 평형 + 평형타입 + 인터넷매물
인덱스 선행 컬럼이 모두 '='조건일 때 필요한 범위만 스캔하고 멈출수 있는 것은 조건을 만족하는 레코드가 모두 한데 모여 있기 때문
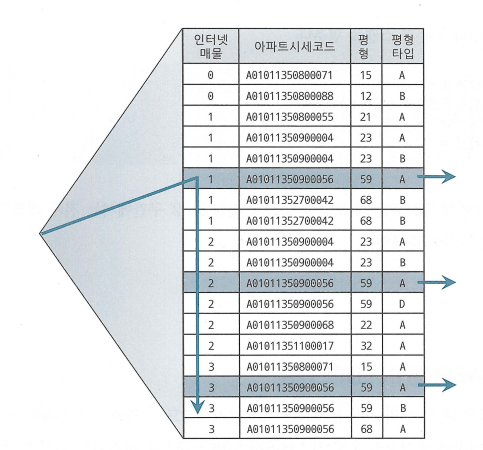
- 인덱스 : 인터넷매물 + 아파트시세코드 + 평형 + 평형타
인덱스 선두 컬럼 인터넷매물에 BETWEEN이 사용되어서 나머지 조건을 만족하는 레코드들이 뿔뿔이 흩어진다.
BETWEEN을 IN-List로 전환
- 범위검색 컬럼이 맨 뒤로 가는 인덱스(BETWEEN 조건을 IN-List로 바꾸면 큰 효과를 얻음)
- In-List 개수 만큼 UNION ALL 브랜치가 생성되고 각 브랜치마다 모든 컬럼을 '='조건으로 검색
- In-List 개수가 늘어날 수 있다면 BETWEEN 조건을 IN-List로 전환하는 방식은 사용하기 곤란
select 해당층, 평당가, 입력일, 해당동, 매물구분, 연사용일수, 중개업소코드
from 매물아파트매매
where 인터넷매물 in ('1', '2', '3')
and 아파트시세코드 'A01011350900056'
and 평형 = '59'
and 평형타입 = 'A'
order by 입력일 desc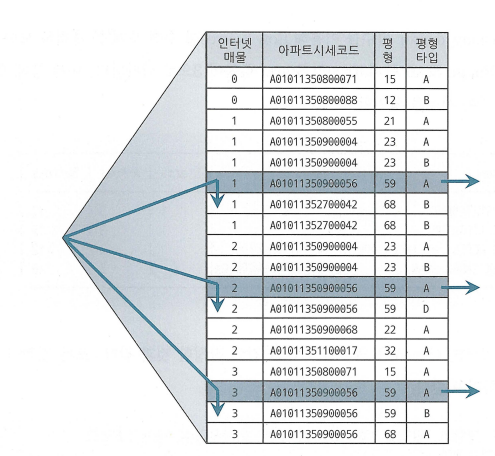
BETWEEN 조건을 IN-List로 전환할 때 주의 사항
아 안돼.. 머.. 멈춰!!!
- IN-List 개수가 많지 않아야 한다.
- 인덱스 스캔과정에 선택되는 레코드들이 서로 멀리 떨어져 있을 때만 유용하다.
- BETWEEN 조건 때문에 인덱스를 비효율적으로 스캔하더라도 블록 I/O 측면에서는 대개 소량에 그치는 경우가 있다.
Index Skip Scan 활용
선두 컬럼이 BETWEEN이어서 나머지 검색 조건을 만족하는 데이터들이 서로 멀리 떨어져있을 때 Index Skip Scan의 위력이 나타난다.
IN 조건은 ‘=’인가
- IN 조건은 '='이 아니다. IN 조건은 필터 조건이다.
select * from 고객별가입상품 where 고객번호 = :cust_no and 상품id in ('NH00037', 'NH00041', 'NH00050') select * from 고객별가입상품 where 고객번호 = :cust_no and 상품id = 'NH00037' union all select * from 고객별가입상품 where 고객번호 = :cust_no and 상품id = 'NH00041' union all select * from 고객별가입상품 where 고객번호 = :cust_no and 상품id = 'NH00050' - 인덱스를 어떻게 구성하느냐에 따라 성능이 달라진다.
- 인덱스 구성에따라 IN-List Iterator를 사용하냐 안하냐에 따라 성능이 달라질 수 있다. 오히려 IN-List Iterator를 사용하면 성능이 떨어지는 경우도 있다.
- NUM_INDEX_KEY 힌트 : 인덱스 액세스 조건으로 사용한다.
- NUM_INDEX_KEY 힌트의 세번째 인자는 인덱스 n번째 컬럼까지만 액세스 조건으로 사용하라는 의미한다.
/*+ num_index_keys(테이블 컬럼 명 n) */BETWEEN과 LIKE 스캔 범위 비교
select * from 월별고객별판매집계
where 판매월 like '2019%'
select * from 월별고객별판매집계
where 판매월 between '201901' and '201912'- LIKE와 BETWEEN은 둘다 범위검색 조건이다.
- LIKE와 BETWEEN은 범위검색 조건을 사용할 때의 비효율이 똑같이 적용됨.
- 하지만 데이터 분포와 조건절 값에 따라 인덱스 스캔량이 서로 다를 수 있다.
- LIKE보다 BETWEEN을 사용하는게 낫다.
where 판매월 between '201901' and '201912'
and 판매구분 = 'B'
where 판매월 like '2019%'
and 판매구분 = 'B'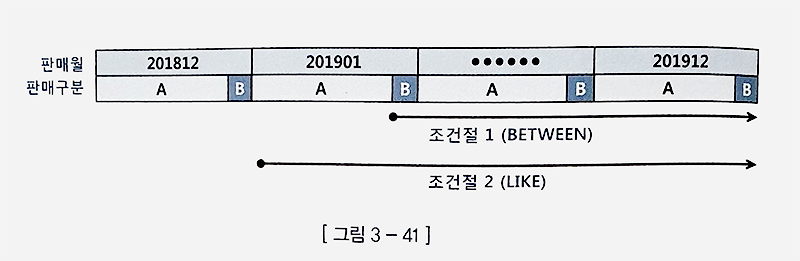
where 판매월 between '201901' and '201912'
and 판매구분 = 'A'
where 판매월 like '2019%'
and 판매구분 = 'A'
범위검색 조건을 남용할 때 생기는 비효율
- 인덱스 컬럼에 범위 검색 조건을 남용하면 인덱스 스캔 비효율이 생긴다.
- 인덱스 스캔 비효율이 성능에 미치는 영향이 적을 수도 있지만, 대량의 테이블을 넓은 범위로 검색할 때는 그 영향이 매우 클 수도 있다.
- 데이터 분포에 따라 인덱스 컬럼에 대한 비교 연산자를 신중하게 선택해야 한다.
select 고객ID, 상품명, 지역코드, ...
from 가입상품
where 회사코드 = :com
and 지역코드 = :reg
and 상품명 like :prod || '%'
select 고객ID, 상품명, 지역코드, ...
from 가입상품
where 회사코드 = :com
and 상품명 like :prod || '%'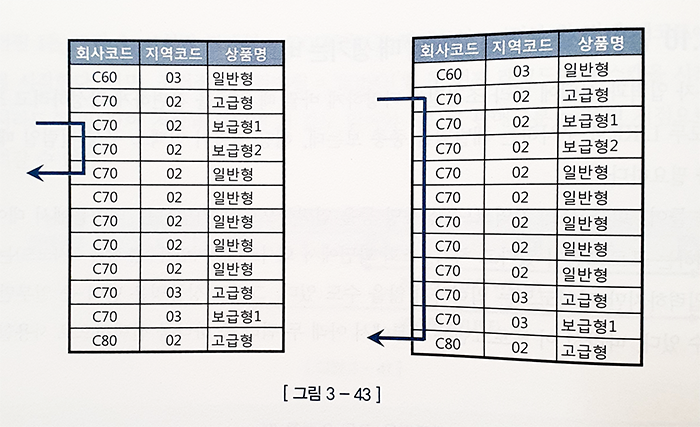
select 고객ID, 상품명, 지역코드, ...
from 가입상품
where 회사코드 = :com
and 지역코드 like :reg || '%'
and 상품명 like :prod || '%'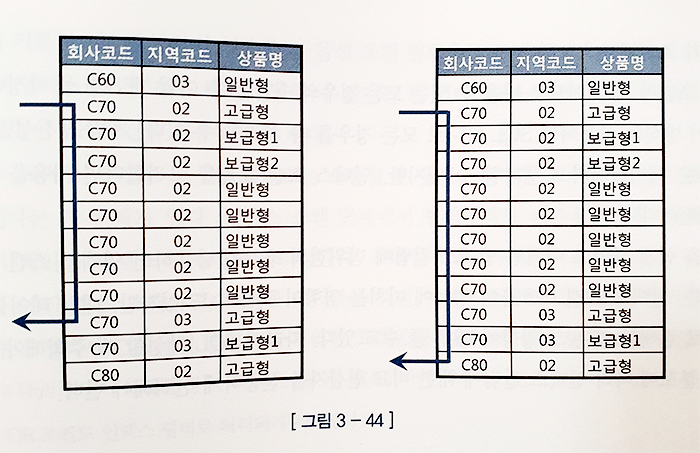
다양한 옵션 조건 처리 방식의 장단점 비교
OR 조건 활용
- 인덱스 액세스 조건으로 사용 불가
- 인덱스 필터 조건으로 사용 불가
- 테이블 필터 조건으로만 사용 가능
- 단, 인덱스 구성 컬럼 중 하나 이상이 Not Null 컬럼이면, 18c부터 인덱스 필터 조건으로 사용 가능
LIKE/BETWEEN 조건 활용
- 인덱스 선두 컬럼 (LIKE/BETWEEN)
- NULL 허용 컬럼 (LIKE/BETWEEN)
- 숫자형 컬럼 (LIKE)
- 가변 길이 컬럼 (LIKE)
UNION ALL 활용
UNION ALL 방식은 옵션 조건 컬럼도 인덱스 액세스 조건으로 사용한다는 사실이 중요하다.
NULL 허용 컬럼이더라도 사용하는데 문제 없음.
유일한 단점은 코딩량이 길어진다.
NVL/DECODE 함수 활용
- 옵션 조건 컬럼을 익데스 액세스 조건으로 사용할 수 있다.
- NVL/DECODE 함수를 여러개 사용하면 그중 변별력이 가장 좋은 컬럼 기준으로 한 번만 OR Expansion이 일어난다.
- 따라서 OR Expansion 기준으로 선택되지 않으면 인덱스 구성 컬럼이어도 모두 필터 조건으로 처리된다.
함수 호출부하 해소를 위한 인덱스 구성
PL/SQL 함수의 성능적 특성
PL/SQL 함수는 개발자들이 일반적으로 생각하는 것보다 매우 느리다.
PL/SQL 사용자 정의 함수가 느린 이유
- 가상머신상에서 실행되는 인터프리터 언어
- 호출 시마다 컨텍스트 스위칭 발생
- 내장 SQL에 대한 Recursive Call 발생 (성능을 떨어뜨리는 가장 결정적이 요소)
효과적인 인덱스 구성을 통한 함수호출 최소화
회원 테이블을 Full Scan 하는 방식으로 읽는것과, 인덱스를 통해 일부 또는 한번만 호출하도록 인덱스 구성을 잘 하면 함수 호출을 최소화 할 수 있다.
select * from 회원 a where 암호화된_전화번호 = encryption(:phone_no)
create index 회원_X03 on 회원 (생년, 암호화된_전화번호);