인덱스 설계가 어려운 이유
인덱스가 많으면 아래와 같은 문제가 생긴다
- DML 성능 저하 (TPS 저하)
- 데이터베이스 사이즈 증가 (디스크 공간 낭비)
- 데이터베이스 관리 및 운영 비용 상승
테이블에 인덱스가 여러개 달려 있으면, 신규 데이터를 입력할 때마다 여러개의 인덱스에도 데이터를 입력해야 한다.
테이블과 달리 인덱스는 정렬 상태를 유지해야 하므로 수직적 탐색을 통해 입력할 브,ㄹ록부터 찾는다. 찾은 블록에 여유공간이 없으면 인덱스 분할(Index Split)도 일어난다.
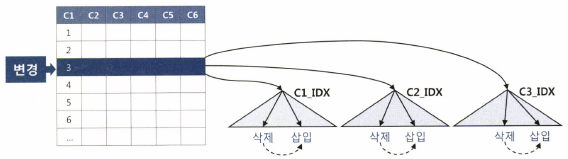
테이블에 데이터가 변경될 때, 3개의 인덱스에도 똑같이 수정해준다.
- 핵심 트랜잭션이 참조하는 테이블에 대한 DML 성능 저하는 TPS 저하로 이어진다.
- 필요하지 않은 인덱스를 많이 만들면 디스크 공간을 낭비한다.
- 데이터베이스 사이즈가 커지면 백업, 복제, 재구성을 위한 운영 비용도 상승한다.
가장 중요한 두가지 선택 기준
인덱스 스캔 방식에 가장 정상적인 방식은 Index Range Scan이다. 이를 사용하기 위해 선두컬럼을 조건절에 반드시 사용해야 한다.
- 결합 인덱스를 구성할 때, 조건절을 항상 사용하거나, 자주 사용하는 컬럼을 선정한다.
- 선정한 컬럼 중 ‘=’ 조건으로 자주 조회하는 컬럼을 앞쪽에 둬야 한다.
스캔 효율성 이외의 판단 기준
그 외 고려해야 할 기준
- 수행빈도 (저자 pick⭐)
- 자주 수행하지 않는 SQL은 비효율이 조금 있어도 큰 문제가 아니다.
- 자주 수행되는 SQL은 최적의 인덱스를 구성해줘야 한다.
- 업무상 중요도
- 클러스터링 팩터
- 데이터량
- DML 부하
(= 기존 인덱스 개수, 초당 DML 발생량, 자주 갱신하는 컬럼 포함 여부 등) - 저장공간
- 인덱스 관리 비용
수행빈도 예시
(사실 여기 이해를 못하겠음..)
수행빈도와 관련해, NL 조인할 때 어느 쪽에서 자주 액세스 되는지도 중요한 판단 기준이 된다.
SELECT /** leadling(a) use_nl(b) */
b.상품코드, b.상품명, a.고객번호, a.거래일자, a.거래량, a.거래금액
FROM 거래 a, 상품 b
WHERE a.거래구분코드 = ‘AC’
AND a.거래일자 BETWEEN ‘20090101’ AND ‘20090131’
AND b.상품번호 = a.상품번호
AND b.상품번호 = ‘가전’SELECT /** leadling(b) use_nl(a) */
b.상품코드, b.상품명, a.고객번호, a.거래일자, a.거래량, a.거래금액
FROM 거래 a, 상품 b
WHERE a.거래구분코드 = ‘AC’
AND a.거래일자 BETWEEN ‘20090101’ AND ‘20090131’
AND b.상품번호 = a.상품번호
AND b.상품번호 = ‘가전’
- 수행빈도가 매우 높은 SQL이라면, 인덱스를 최적으로 구성해 줘야 한다.
- NL 조인 Inner 쪽 인덱스는 ‘=’ 조건 컬럼을 선두에 두는 것이 중요
- 테이블 액세스 없이 인덱스에서 필터링을 마치도록 구성
데이터량도 인덱스를 설계할 때 중요한 판단 기준이다. 데이터량이 적다면 Full Scan으로도 충분히 빠르기 때문에 굳이 인덱스를 많이 만들 필요가 없다.
반대로, 인덱스를 많이 만들어도 저장 공간이나 트랜잭션 부하 측면에서 그다지 문제될 것이 없다. 테이블이 작으면, 심각하게 고민할 이유가 없다는 뜻이다.
초대용량 테이블은 INSERT도 많다. 초당 DML 발생량은 트랜잭션 성능(TPS)에 직접적인 영향을 준다.
NL 조인
SELECT /*+ ordered use_nl(e) */
E.EMP_NO, E.ENAME, D.DNAME, E.JOP, E.SAL
FROM DEPT D, EMP E
WHERE E.DEPT_NO = D.DEPT_NO --- [1]
AND D.LOC = 'SEOUL' --- [2]
AND D.GB = '2' --- [3]
AND E.SAL >= 1500 --- [4]
ORDER BY SAL DESC;
Answer :: [2] -> [3] -> [1] -> [4]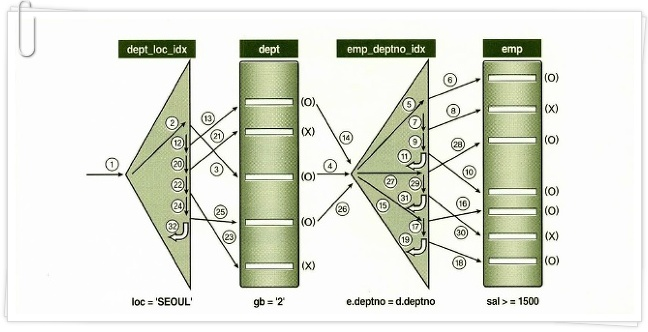
공식을 초월한 전략적 설계
조건절 패턴이 10개가 있을때, 패턴마다 인덱스를 다 만들 수 없다.
10개중 최적을 달성해야 할 가장 핵심 액세스 경로 한두개를 선택해 최적 인덱스를 설계한다.
나머지 엑세스는 목표 성능을 만족하는 수준으로 인덱스 구성해야 한다.
소트 연산을 생략하기 위한 컬럼 추가
인덱스는 항상 정렬상태라 ORDER BY, GROUP BY를 위한 소트 연산을 생략할 수 있게 해줌. 조건절에 사용하지 않는 컬럼이라도 소트 연산을 생략할 목적 인덱스 구성에 포함시켜 성능개선 가능.
SELECT 계약ID, 청약일자, 입력자ID, 계약상태코드, 보험시작일자, 보험종료일자
FROM 계약
WHERE 취급지점ID = :trt_brch_id
AND 청약일자 BETWEEN :sbcp_dt1 AND :sbcp_dt2
AND 입력일자 >= TRUNC(SYSDATE - 3)
AND 계약상태코드 IN (:ctr_stat_cd1, :ctr_stat_cd2, :ctr_stat_cd3)
ORDER BY 청약일자, 입력자IDORDER BY 절 순서대로 『청약일자 + 입력자ID』로 구성하여 소트연산 생략
I/O를 최소화하면서도 소트 연산을 생략하려면, 아래 공식에 따라 인덱스를 구성하면 된다.
- ‘=’ 연산자로 사용한 조건절 컬럼 선정
- ORDER BY 절에 기술한 컬럼 추가
- ‘=’ 연산자가 아닌 조건절 컬럼은 데이터 분포를 고려해 추가 여부 결정
이 공식에 따라 위에서 제시한 SQL에는 인덱스를 『취급지점ID + 청약일자 + 입력자ID』 순으로 구성
결합 인덱스 선택도
인덱스 생성 여부를 결정할 때는 선택도가 충분히 낮은지가 중요한 판단기준이다.
- 선택도(Selectivity)
- 전체 레코드 중에서 조건절에 의해 선택되는 레코드 비율
카디널리티 = 선택도 * 총레코드 수
- 인덱스 선택도
- 인덱스 컬럼을 모두 ‘=’으로 조회할 때 평균적으로 선택되는 비율
인덱스를 생성할 때 선택도/카디널리티 를 확인해야 한다.
컬럼 순서 결정 시, 선택도 이슈
컬럼의 액세스 조건이라 어떤 컬럼이 먼저 오든 스캔범위는 같다.
인덱스 설계할 때..
- 항상 사용하는 컬럼을 앞쪽에 두기
- 그중 '=' 조건 앞쪽에 위치 시키는 것 뿐
인덱스 생성 여부를 결정할때는 선택도가 중요하다.
컬럼간 순서를 정할 때는 컬럼의 선택도보다는 ’필수조건 여부’, ‘연산자 형태’가 더 중요한 판단 기준이다.
중복 인덱스 제거
- X01 : 계약ID + 청약일자
- X02 : 계약ID + 청약일자 + 보험개시일자
- X03 : 계약ID + 청약일자 + 보험개시일자 + 보험종료일자
이 인덱스들은 중복이다. 포함 여부를 보면 X03 > X02 > X01 이기 때문에, X03을 남기고 나머지는 지워도 된다.
- X01 : 계약ID + 청약일자
- X02 : 계약ID + 보험개시일자
- X03 : 계약ID + 보험종료일자
- X04 : 계약ID + 데이터생성일시
위의 인덱스들은 중복이 아니나, 계약 ID의 평균 카디널리티가 매우 낮다면 사실상 중복이다. 이를 불완전 중복이라 부름
아래 하나만 만들면 충분하다.
- X01 : 계약ID + 청약일자 + 보험개시일자 + 보험종료일자 + 데이터생성일시
실습1
거래일자, 결제일자는 항상 BETWEEN 또는 부등호로 조회됨
- PK : 거래일자 + 관리지점번호 + 인련번호
- N1 : 계좌번호 + 거래일자
- N2 : 결제일자 + 관리지점번호
- N3 : 거래일자 + 종목코드
- N4 : 거래일자 + 계좌번호
| 거래일자 | 2,356 |
|---|---|
| 관리지점번호 | 127 |
| 일련번호 | 1,850 |
| 계좌번호 | 5,956 |
| 종목코드 | 1,715 |
| 결제일자 | 2,356 |
| - 정답1 |
거래일자가 항상 BETWEEN이면 N3, N4는 둘다 거래일자가 액세스 조건임. 그래서 인덱스를 2개나 만들 필요 없다. N3, N4를 합쳐준다.
- N4 삭제
- N3 : `거래일자 + 종목코드 + 계좌번호` 로 수정
- PK : 거래일자 + 관리지점번호 + 인련번호
- N1 : 계좌번호 + 거래일자
- N2 : 결제일자 + 관리지점번호
- **N3 : 거래일자 + 종목코드 + 계좌번호**
- ~~N4 : 거래일자 + 계좌번호~~- 정답2하지만 관리지점번호가 선두인 인덱스가 없어 PK를 관리지점, 거래일자로 조회하는 인덱스로 사용한다.
- PK : 관리지점번호 + 거래일자 + 인련번호
- N1 : 계좌번호 + 거래일자
- N2 : 결제일자 + 관리지점번호
- N3 : 거래일자 + 종목코드
- ~N4 : 거래일자 + 계좌번호~
- N4를 삭제하고 N3를 그대로 둔다. 계좌번호 관련 조회는 N1을 사용한다.
실습2
- PK : 주소ID + 건물동번호 + 건물호번호 + 관리번호
- N1 : 상태구분코드 + 관리번호
- N2 : 관리번호
- N3 : 주소ID + 관리번호
- 정답그렇게 되면 N2는 중복이 되므로 삭제한다.
- PK : 주소ID + 건물동번호 + 건물호번호 + 관리번호
- N1 : 관리번호 + 상태구분코드
- N2 : ~관리번호~
- N3 : 주소ID + 관리번호
- 상태구분코드는 NDV가 낮아 N1인덱스가 사용되지 않음. 그래서 관리번호랑 상태구분코드의 순서를 바꿔주는게 좋다.
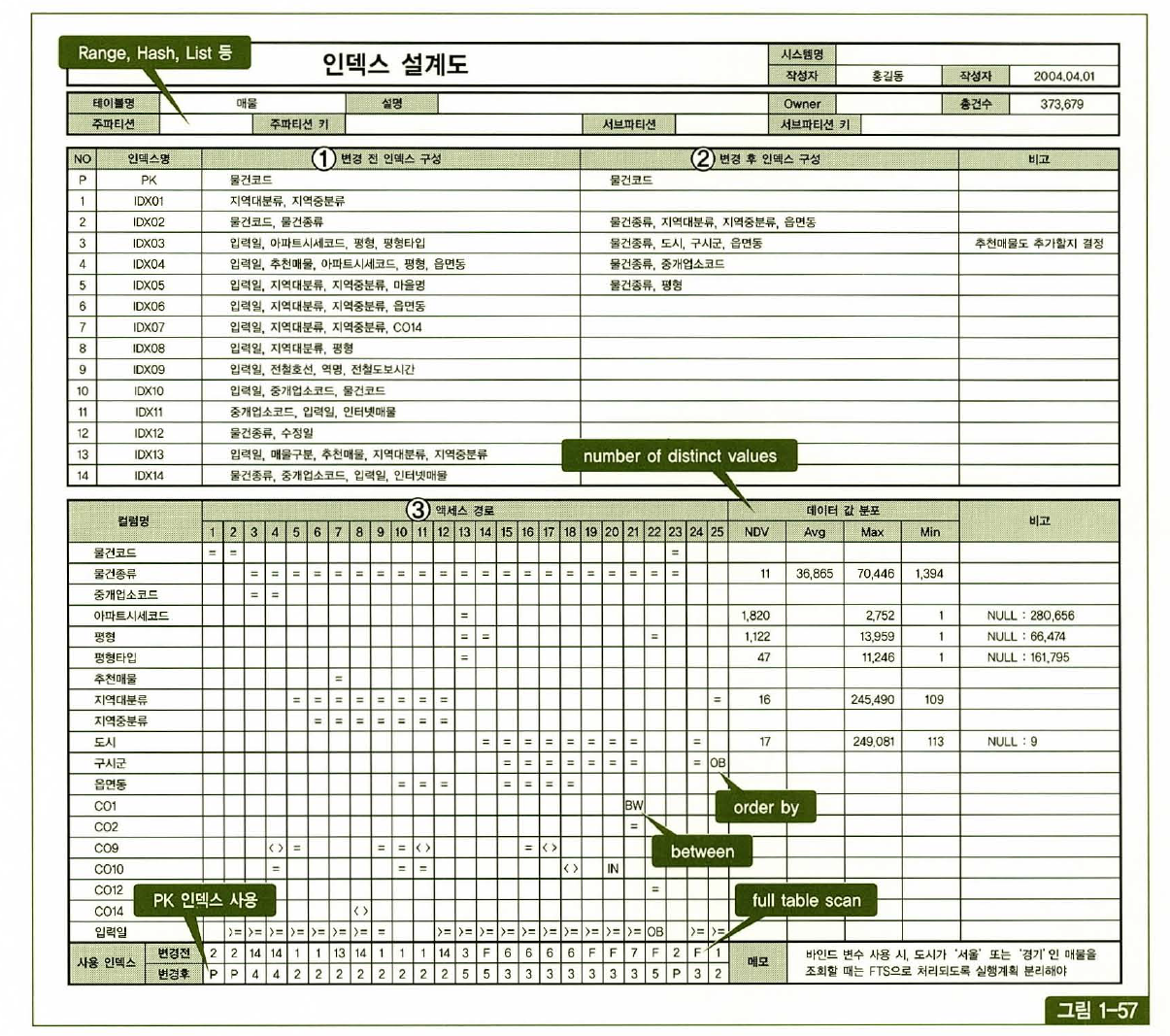
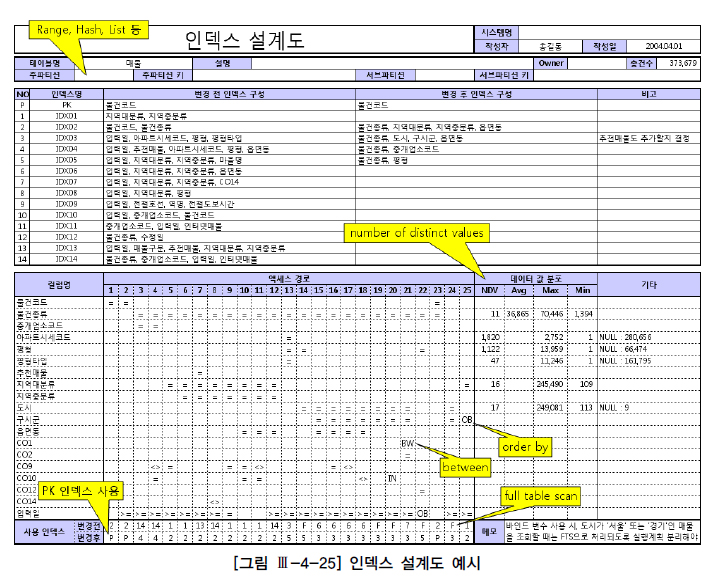
인덱스 설계도 작성
인덱스 설계 시 시스템 전체 효율을 고려해야 한다. 조화를 이룬 건축물을 짓기 위해 설계도가 필수인 것처럼 인덱스 설계 시에도 전체를 조망할 수 있는 설계도면이 필요한 이유다.
)