웹 캐시란
브라우저가 웹 서버에 접속하여 받아온 정적 컨텐츠(html, 이미지, js 등)를 메모리 또는 디스크에 저장해 놓는 것을 말한다. 이후 HTTP요청을 할 경우 해당 리소스가 캐시에 있는지 확인하고 이를 재사용함으로써 응답시간과 네트워크 대역폭을 줄일 수 있다
웹 캐시의 장점
1. 불필요한 네트워크 통신을 줄인다
클라이언트가 서버에게 문서를 요청할 때, 서버는 해당 문서를 클라이언트에게 전송하게 된다. 재차 똑같은 문서를 요청할 경우 똑같이 전송하게 된다.
캐시를 이용하면, 첫번째 응답은 브라우저 캐시에 보관되고, 클라이언트가 똑같은 문서를 요청할 경우 캐시된 사본이 이에 대한 응답으로 사용될 수 있기 때문에 중복해서 트래픽을 주고받는 네트워크 통신을 줄일 수 있다.
2. 네트워크 병목을 줄여준다
많은 네트워크가 원격 서버보다 로컬 네트워크에 더 넓은 대역폭을 제공한다. WAN보다 LAN이 구성이 더 쉽고 거리도 가까우며, 비용이 적게 들기 때문이다. 만약 클라이언트가 빠른 LAN에 있는 캐시로부터 사본을 가져온다면, 캐싱 성능을 대폭 개선할 수도 있다.
예를 들어 샌프란시스코 지사에 있는 사용자는 애틀랜타 본사로부터 문서를 받는 데 30초가 걸릴 수 있다. 만약 이 문서가 샌프란시스코의 사무실에 캐시되어 있다면, 로컬 사용자는 같은 문서를 이더넷 접속, 즉 LAN을 통해 1초 미만으로 가져올 수 있을 것이다.
3. 거리로 인한 네트워크 지연을 줄여준다.
대역폭이 문제가 되지 않더라도, 거리가 문제될 수 있다. 캐시는 이러한 거리를 수천 킬로미터에서 수십 미터로 줄일 수 있다.
4. 갑작스런 요청 쇄도(Flash Crowds)에 대처 가능하다.
원 서버로의 요청을 줄이기때문에 갑작스런 요청 쇄도 (Flash Crowds) 에 대처할 수 있다.
cache hit, cache miss
캐시에 요청이 도착했을 때, 그에 대응하는 사본이 있다면 이를 요청해 처리할 수 있다. 이를 캐시 적중(cache hit)라고 하고, 대응되는 사본이 없다면 원 서버로 요청이 전달된다. 이를 캐시 부적중(cache miss)라고 한다
캐시 포톨로지
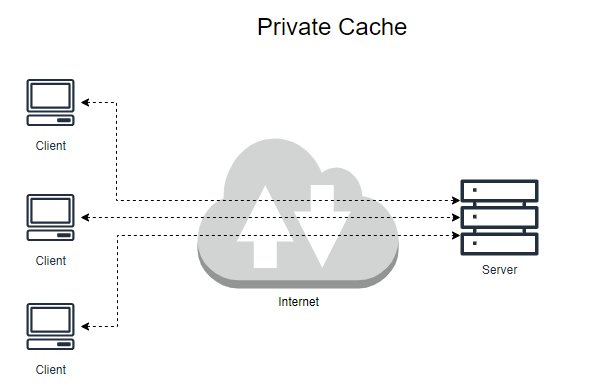
캐시는 한 명의 사용자에게만 할당될 수 있고, 수천 명의 사용자에게 공유될 수도 있다. 한명에게만 할당된 캐시를 전용 캐시, private cache라고 하고, 여러 사용자가 공유하는 캐시는 공용캐시, public cache라고 한다.
private cache의 대표적인 예는 브라우저 캐시이다. 웹 브라우저는 개인 전용 캐시를 내장하고 있으며, 컴퓨터의 디스크 및 메모리에 캐시해놓고 사용한다.
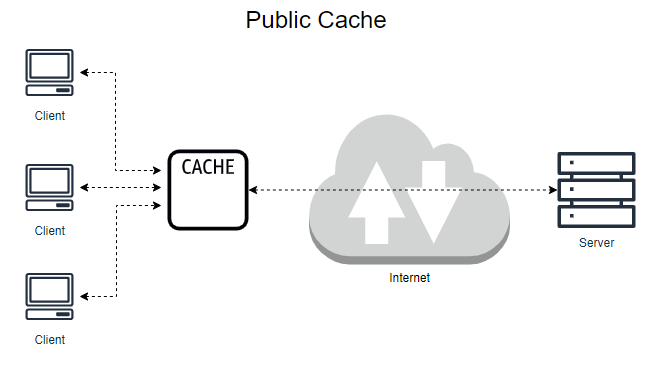
public cache의 대표적인 예는 프록시 서버이다. 각각 다른 사용자들의 요청에 대해 공유된 사본을 제공할 수 있어 private cache보다 네트워크 트래픽을 줄일 수 있다
프록시 서버
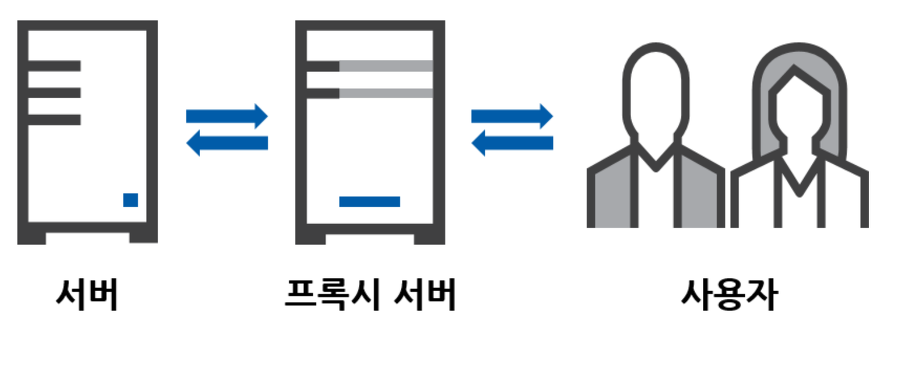
프록시 서버는 클라이언트와 서버 사이에 중간자 역할을 하는 서버이다. 클라이언트가 요청을 프록시 서버에 보내면, 프록시 서버는 이를 다시 받아서 실제 서버로 전달하고, 응답을 다시 클라이언트로 반환한다.
쉽게 말해, 클라이언트와 서버 간의 대리자 역할을 수행하는 서버이다.
프록시 서버의 동작 방식
- 클라이언트가 요청을 프록시 서버에 보낸다
- 프록시 서버는 요청을 분석하고, 필요한 경우 수정하거나 특정 정책을 적용한다
- 요청을 실제 서버로 전달한다
- 실제 서버에서 응답을 받으면 이를 클라이언트에게 반환한다
프록시 서버의 주요 역할 및 용도
- IP주소 숨기기 및 익명성 보장
- 클라이언트는 프록시 서버의 ip주소를 사용하여 서버에 접근하므로, 클라이언트의 실제 ip주소가 노출되지 않는다
- 예: 인터넷에서 사용자의 위치나 신원을 숨길 때
- 트래픽 필터링 및 보안
- 프록시 서버는 클라이언트 요청을 분석하여 악성 요청을 차단하거나, 특정 사이트로의 접근을 제한할 수 있다
- 예: 기업이나 학교에서 비업무적인 웹사이트 접근 차단
- 캐싱
- 자주 요청되는 데이터를 프록시 서버에 저장(캐싱)하여 클라이언트 요청에 빠르게 응답할 수 있다
- 예: 웹페이지, 이미지 등
- 콘텐츠 필터링
- 특정 유형의 콘텐츠(예: 성인 콘텐츠, 광고)를 차단하여 클라이언트에 전달되지 않도록 한다
- 로드 밸런싱
- 여러 서버로 트래픽을 분산하여 서버 부하를 분산하고 시스템의 안정성을 높인다
- 접근 제어 및 인증
- 프록시 서버를 통해 특정 사용자만 서버에 접근할 수 있도록 제한하거나, 사용자 인증을 수행할 수 있다
- 인터넷 속도 향상
- 캐시와 로드 밸런싱을 통해 사용자가 빠르게 콘텐츠에 접근할 수 있도록 도와준다
프록시 서버의 장점
- 보안 강화 : 클라이언트와 서버 간의 직접적인 연결을 막아 외부 공격을 차단
- 속도 향상 : 캐시를 통해 자주 사용하는 데이터를 빠르게 제공
- 접근 제어 : 사용자별, 그룹별 접근 제어 가능
- 비용 절감 : 네트워크 트래픽을 줄이고 서버 부하를 감소시켜 비용 절약
프록시 서버의 단점
- 속도 저하 가능성 : 캐싱되지 않은 요청은 중간 단계가 추가되어 응답 속도가 느려질 수 있음
- 구성 및 관리 복잡성 : 정책 설정, 인증 관리 등으로 관리가 복잡해질 수 있음
- 프라이버시 문제 : 프록시 서버가 모든 트래픽을 관리하고 모니터링할 수 있으므로, 개인 정보가 노출될 가능성이 있음
프록시 서버의 종류
1. Forward 프록시
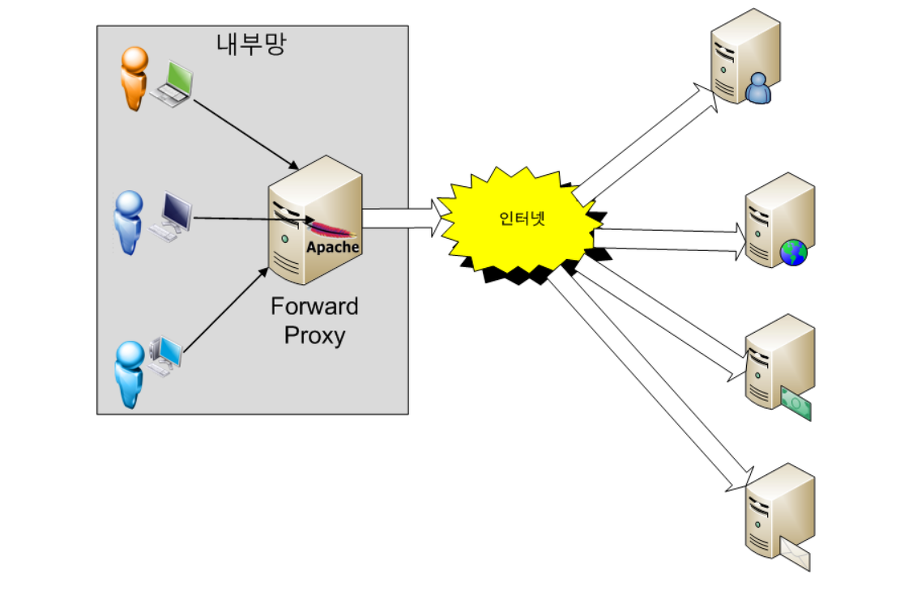
- 프록시 서버를
클라이언트 호스트들과 접근 하고자 하는 원격 리소스 사이에 위치시킨다. 즉, 사용자가 naver.com에 연결하려고 하면 사용자가 직접 pc에 연결하는 것이 아니라 forward 프록시 서버가 요청을 받아 naver.com에 연결하여 그 결과를 사용자에게 전달해준다. - 이 서버는 전형적으로 로컬 디스크에 데이터를 저장하며, 클라이언트 호스트들은 사용 중인 웹 브라우저를 이용해 프록시 서버 설정을 해야 하므로 프록시 서버를 사용하고 있다는 것을 인식할 수 있다
- 이 방식은 대역폭 사용을 감소시킬 수 있다는 것과, 접근 정책 구현에 있어 다루기 쉬우면서도 비용이 저렴하다는 장점이 있다. 사용자의 정해진 사이트만 연결할 수 있는 웹 사용환경을 제한할 수 있으므로 기업에서 많이 사용된다
2. Reverse 프록시
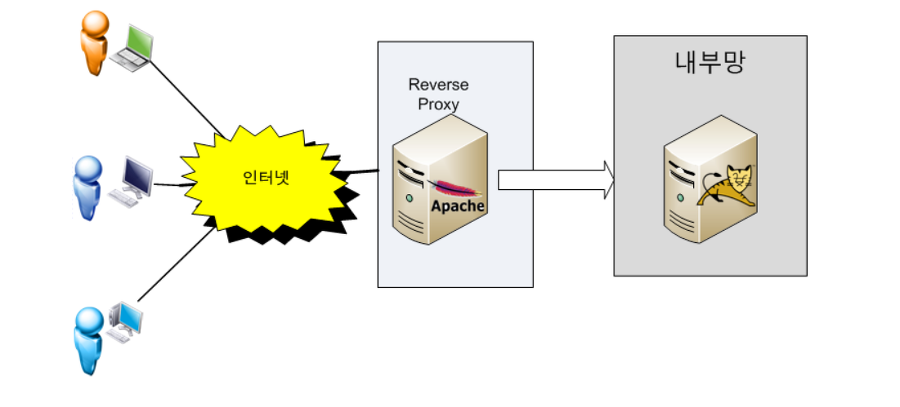
- 프록시 서버를 인터넷 리소스 또는 인트라넷 리소스 앞에 위치시키는 방식, 즉 사용자가 naver.com 웹 서비스에 데이터를 요청하면, reverse 프록시가 이 요청을 받아 내부 서버에서 데이터를 받은 후 이 데이터를 사용자에게 전달하는 방식이다.
- 이 방식을 사용하면 클라이언트들이 프록시 서버에 연결되었다는 것을 인식하지 못하며 마치 최종 사용자가 요청 리소스에 직접 접근하는 것과 같이 느껴진다
- 내부 서버가 직접 리소스를 제공해도 되지만 이렇게 구성하는 이유는 보안 때문이다. 보통 기업의 네트워크 환경은 DMZ라고 하는 외부 네트워크와 외부 네트워크 사이 위치하는 구간이 존재하며, 이 구간에는 메일 서버, 웹 서버, FTP 서버 등 외부 서비스를 제공하는 서버가 위치하게 된다
3. 오픈 프록시
- 모든 인터넷 사용자가 엑세스 할 수 있는 프록시 서버로 익명 공개 프록시는 사용자가 브라우징을 하거나 다른 인터넷 서비스를 이용하는 동안 자신의 IP주소를 숨길 수 있도록 해준다. IP추적을 방지하거나 우회해서 접속하는 기능을 수행할 수 있다
L7 로드 밸런서
L7 로드 밸런서는 OSI 7계층 중 애플리케이션 게층에서 작동하는 로드밸런서이다. 즉, HTTP, HTTPS, FTP 등과 같은 애플리케이션 레벨의 프로토콜을 이해하고, 이를 기반으로 트래픽을 분산한다
L7 로드밸런서는 요청의 헤더, 쿠키, URI, HTTP 메서드 등 애플리케이션 계층 데이터를 분석하여 더 세부적인 트래픽 제어를 수행한다. 이 방식은 컨텐츠 기반 로드 밸런싱(Content-Based Load Balancing)이라고도 부른다
L7 로드 밸런서의 주요 기능
1. 컨텐츠 기반 분산
- 요청의 URI, 헤더, 쿠키 등을 기반으로 특정 서버에 트래픽을 전달
- 예:
/image요청은 이미지 서버로,/api요청은 API 서버로 라우팅
2. 세부적인 트래픽 제어
- 특정 클라이언트 요청(예: 모바일 사용자, 특정 지역 사용자)에 대해 다른 서버를 할당하거나 다른 응답을 제공
- 예: 한국 사용자는
kr.example.com, 미국 사용자는us.example.com으로 분산
3. SSL 종료 및 오프로드
- HTTPS 요청의 SSL/TLS 암호화를 로드 밸런서에게서 해제(종료)하여, 백엔드 서버의 부하를 줄임
4. 요청 필터링 및 리디렉션
- 악성 요청 차단, 특정 요청에 대한 리디렉션 수행
- 예: 오래된 API버전에 대한 요청을 새 버전으로 리다이렉트
5. 상태 점검
- 각 서버의 상태를 애플리케이션 레벨에서 점검하여 비정상적인 서버로 트래픽이 전달되지 않도록 관리
6. 세션 유지
- 동일한 사용자의 요청을 항상 같은 서버로 전달.
- 예: 로그인 상태를 유지해야 할 때
L7 로드 밸런서의 동작 방식
- 클라이언트 요청을 수신
- 요청 내용을 분석(URI, 쿠키, 헤더 등)
- 설정된 규칙에 따라 요청을 적절한 백엔드 서버에 전달
- 백엔드 서버에서 응답을 받고 이를 클라이언트에게 반환
대표적인 L7 로드 밸런서 도구
- NGINX
고성능 HTTP 및 리버스 프록시 서버로, 정교한 L7 로드 밸런싱 기능 제공. - HAProxy
고가용성과 성능을 제공하는 오픈소스 로드 밸런서. - AWS Elastic Load Balancer (Application Load Balancer)
AWS에서 제공하는 L7 로드 밸런서 서비스로, 클라우드 환경에 최적화. - Traefik
컨테이너 중심의 L7 로드 밸런서로, Kubernetes 환경에서 자주 사용.
커넥션 타임아웃, 리드 타임아웃
커넥션 타임아웃(Connection Timeout)
-
정의
클라이언트가 서버와 연결을 설정하는 데 걸리는 최대 시간을 의미합니다.
TCP 연결을 맺기 위한 시도(Connection Establishment) 단계에서 타임아웃이 발생하면 연결이 실패합니다. -
동작 시점
클라이언트가 서버에 요청을 보내기 위해 TCP 3-way handshake를 시도할 때 발생. -
주요 원인
서버가 응답하지 않거나 다운된 경우.
네트워크 연결 상태가 불안정하거나 손실된 경우.
방화벽이 TCP 연결 요청을 차단하는 경우.
설정 목적
너무 긴 대기 시간을 방지하고, 빠르게 재시도를 유도하여 시스템 자원을 효율적으로 사용하기 위함. -
사용 사례
대기 시간이 긴 서버와의 연결 시도 시 적절한 값을 설정해 클라이언트가 불필요하게 대기하지 않도록 함.
리드 타임아웃(Read Timeout)
-
정의
클라이언트가 서버로부터 응답 데이터를 읽는 데 걸리는 최대 시간을 의미합니다.
연결이 성공적으로 맺어진 후, 서버에서 응답 데이터를 읽는 도중 지정된 시간 내에 데이터가 수신되지 않으면 타임아웃이 발생합니다. -
동작 시점
서버가 데이터를 전송하는 단계에서 클라이언트가 데이터를 읽는 동안 발생. -
주요 원인
서버가 작업을 완료하는 데 시간이 오래 걸리는 경우.
(예: 복잡한 데이터 처리 또는 백엔드 지연)
네트워크 속도가 느리거나 손실이 발생한 경우. -
설정 목적
서버의 응답 지연이 있을 때 클라이언트가 무한히 기다리지 않도록 제한하고, 더 나은 사용자 경험을 제공. -
사용 사례
REST API 호출이나 파일 다운로드 같은 작업에서, 서버 응답이 지연될 때 이를 감지하고 대기 시간을 제한.
커넥션 타임아웃과 리드 타임아웃의 비교
| 항목 | 커넥션 타임아웃 | 리드 타임아웃 |
|---|---|---|
| 정의 | 연결 설정에 걸리는 최대 시간 | 응답 데이터를 읽는 데 걸리는 최대 시간 |
| 동작 시점 | TCP 3-way handshake 단계 | 연결 후 데이터 읽기 단계 |
| 주요 원인 | 서버 다운, 네트워크 장애 | 서버 응답 지연, 네트워크 속도 저하 |
| 설정 목적 | 연결 시도의 대기 시간을 제한 | 데이터 수신 대기 시간을 제한 |
| 타임아웃 발생 시 결과 | 연결 시도가 중단 | 연결은 유지되지만 응답 처리가 중단 |
설정 예시(Java의 HttpURLConnection)
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
// 커넥션 타임아웃 설정 (5초)
connection.setConnectTimeout(5000);
// 리드 타임아웃 설정 (10초)
connection.setReadTimeout(10000);
// 요청 실행
connection.connect();출처 : https://tlatmsrud.tistory.com/119,
https://velog.io/@jangwonyoon/Proxy-Server%ED%94%84%EB%A1%9D%EC%8B%9C-%EC%84%9C%EB%B2%84%EB%9E%80
