concat
concat은 concatenation의 줄임말로 연결을 뜻한다. 두개의 데이터프레임을 하나의 데이터프레임으로 만들 때 사용한다.
df1 = pd.DataFrame({
'fruit': ['apple', 'cherry', 'peach', 'banana'],
'age': [23, 19, 30, 27]
})
df2 = pd.DataFrame({
'fruit': ['lemonn', 'mango', 'rasberry', 'watermelon'],
'age': [16, 25, 23, 31]
})
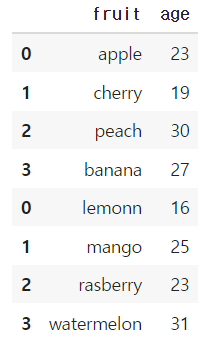
df1 = pd.concat([df1, df2])위의 코드를 실행하면 df1에는 다음과 같은 값들이 들어가있다.
merge
merge는 concat과 비슷한데 조금 다르다. merge는 공통의 열을 기준으로 두 데이터프레임을 합쳐준다.
merge의 how라는 파라미터가 있는데 그 값으로 letf, right, outer, inner, cross가 들어갈 수 있다. 그 중에서 cross를 제외한 나머지 방법들에 대해서 검색해봤다.
아래는 how 속성을 설명하기 위해서 간단하게 만든 두개의 데이터프레임이다
df1 = pd.DataFrame({
'fruit': ['apple', 'cherry', 'peach', 'banana'],
'age': [23, 19, 30, 27]
})
df2 = pd.DataFrame({
'fruit': ['apple', 'banana', 'mango'],
'loc': ['Seoul', 'DeaGu', 'Busan']
})how = left
왼쪽에 오는 데이터프레임을 기준으로 합쳐주며, 오른쪽 데이터프레임에 값이 없을 경우에는 NaN이 들어가게 된다.
df1 = merge(df1, df2, how = 'left)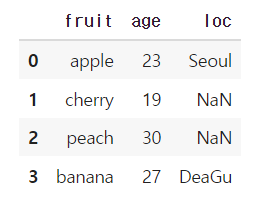
how = right
오른쪽에 오는 데이터프레임을 기준으로 합쳐주며, 왼쪽 데이터프레임에 값이 없을 경우 NaN이 들어간다.
df1 = merge(df1, df2, how = 'right')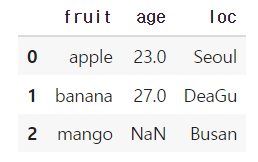
how = inner
inner는 두 데이터프레임의 교집합이 나타나게 된다. 즉, df1과 df2이 공통적으로 갖고 있는 값만 나타난다.
df1 = merge(df1, df2, how = 'inner')
how = outer
outer는 두 데이터프레임에 들어있는 모든 값들이 나타난다. 없는 값들은 위에서와 마찬가지로 NaN이 들어간다.
df1 = merge(df1, df2, how = 'outer')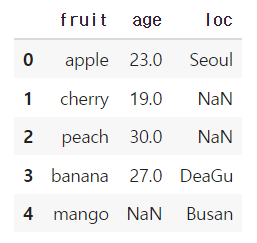
index
행 인덱스를 다루는 함수 두가지를 공부했는데, 찾아보니까 인덱스를 다룰 수 있는 방법은 이 함수 두개 외에도 많은 함수들이 있었다. 주말에 시간이 나면 정리해야겠다.
set_index()
set_index 함수는 딱 보면 알지만 행 인덱스를 설정하는 함수이다. 다만, 행 인덱스를 설정할 때 특정 열을 인덱스로 설정할 때 사용한다.
예제는 위에서 작성해놓은 df1을 가지고 실험해봤다.
df1.set_index('age') 
set_index를 사용해 column으로 인덱스를 지정하게 되면 해당 column은 없어지는걸 확인할 수 있다.
reset_index()
reset_index 함수는 설정한 인덱스를 초기화 시키는 함수이다. 초기화시키게 되면 인덱스는 저절로 0부터 시작하게 된다.
또한 set_index에서 인덱스로 사용한 column이 자동으로 없어졌던 것처럼 reset_index도 인덱스로 사용된 값이 자동으로 column의 첫 열로 삽입된다.
df1.reset_index()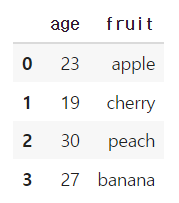
이때, reset_index에 drop=True 값을 전달해주면 인덱스로 사용된 값이 column으로 돌아오는게 아니라 삭제된다.

tidy
Tidy data는 깔끔한 데이터라고 한다. Tidy data의 설명을 위해서 변수 하나를 만들었다
df3 = pd.DataFrame({
'fruit': ['apple', 'cherry', 'peach', 'banana'],
'age': [23, 19, 30, 27],
'loc': ['Seoul', 'DeaGu', 'Busan', 'Ilsan']
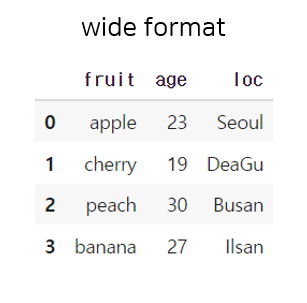
})위의 변수를 출력하면 다음과 같이 나오는데 이건 wide 형식인 데이터로 지저분한 형식이라고 한다.
다음과 같은 형식으로 나오면 Tidy data, 즉 깔끔한 데이터이다.
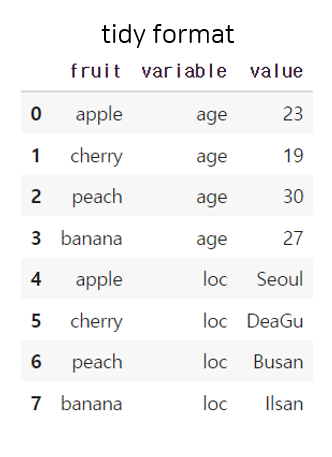
wide 형식의 데이터가 어떻게 tidy 형식의 데이터로 변하는지 한번 정리해봤다.
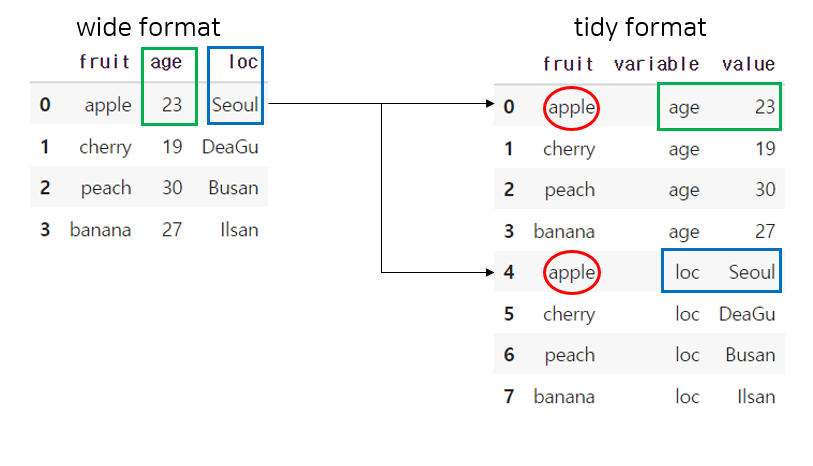
tidy data의 2행이 wide data의 1행과 같은 의미를 가진 데이터이다. fruit를 기준점 삼았기 때문에 남은 열인 age와 loc 변수 두가지로 나뉘게 된 것이라고 이해했다.
(아직도 아리까리하니 혹시라도 아시는 분이 댓글로 설명해주시면 감사하겠습니다🤩)
melt
pandas에서는 wide format의 데이터를 tidy format 데이터로 바꿀 수 있도록 도와주는 함수가 있는데 그게 바로 melt 함수이다.
df3 = df3.melt(id_vars='fruit', value_vars=['age', 'loc'])위와 같이 작성하면 tidy format의 데이터를 얻을 수 있다.
id_vars는 기준점이라고 이해했고, value_vars는 melt의 대상이 될 칼럼들이라고 이해했다.
그 외의 옵션들이 있는데 그건 나에게 지금 당장 필요한 게 아닌지라 나중에 공식문서에서 확인하면서 하면 될 것 같아서 따로 정리는 안했다.
+) tidy data로 seaborn을 사용해 boxplot을 그리려는데 아래와 같은 오류가 났었다.

저 줄의 코드는 코드스테이츠측에서 제공해준 한줄의 코드로.. 저 코드가 문제없이 돌아가야만 했는데 내가 df_tidy의 데이터 타입을 제대로 확인 안하고 잘 풀린다며 슝슝 진행하다보니 저기서 에러가 나서 살짝 멘붕이었다.
하필 아래쪽을 제대로 캡쳐를 안했는데.. 방문 기록을 찾아보니
TypeError: Neither the `x` nor `y` variable appears to be numeric.요 에러였다. 그래프를 그릴 땐 꼭 데이터 타입이 str이 아닌지 확인하고 그리자..!!
나는 당연하게도 데이터 타입이 int 아님 float일 줄 알고 진행했었다.. 멍청하게도 저기서 조금 헤메는 바람에 과제를 일찍 끝낼 수 있었는데 일찍 못 끝냈다.. 아쉬워😂
