분산 표현 (Distributed representation)
분포 가설은 유유상종이라는 사자성어처럼 비슷한 의미를 지닌 단어는 주변 단어의 분포도 비슷하다는 가설이다.
예를 들어서 나는 귀여운 강아지를 봤다와 나는 예쁜 강아지를 봤다라는 두문장이 있다
이때 귀여운과 예쁜은 해당 단어 주변에 분포한 단어가 유사하기 때문에 비슷한 의미를 지닐 것이라고 가정하는 것이 바로 분포 가설이다.
그리고 이 분포 가설에 기반해 주변 단어 분포를 기준으로 단어의 벡터 표현이 결정되기 때문에 분산 표현이라고 부른다.
One-hot Encoding
원-핫 인코딩은 단어를 벡터화 할 때 선택가능한 제일 쉬운 방법이다.
머신러닝을 배울 때 이미 한번 접했던 것이라서 간단하게 원핫 인코딩이 어떻게 되는지만 짚고 넘어가려고 한다.
I saw a cute puppy 라는 문장을 원핫 인코딩 했을 때 다음과 같이 인코딩 된다.

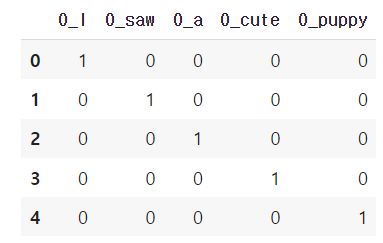
원핫 인코딩은 위와 같이 인코딩을 진행하기 때문에 단어 간 유사도를 구할 수 없다는 단점을 갖고 있다.
임베딩 (Enbedding)
임베딩은 원핫 인코딩의 단점을 해결하기 위해서 등장했다. 단어를 차원이 일정한 벡터로 나타내기 때문에 임베딩이라는 이름이 붙었다고 한다.
임베딩에서는 벡터 내의 각 요소가 바이너리한 값(0과 1)이 아닌 연속적인 값을 가지게 된다.
Word2Vec
Word2Vec은 단어를 벡터로 (Word to Vector) 나타내는 방법으로 가장 많이 사용되는 임베딩 방법 중 하나이다. Word2Vec은 특정 단어의 양 옆에 위치한 단어들의 관계를 활용하기 때문에 분포가설을 잘 반영하고 있다는 특징을 갖고 있다.
CBoW & Skip-gram
Word2Vec에는 두가지 방법이 있는데 바로 CBoW와 Skip-gram이다. 이 둘의 차이는 어느 단어를 기반으로 정보를 예측하느냐이다.
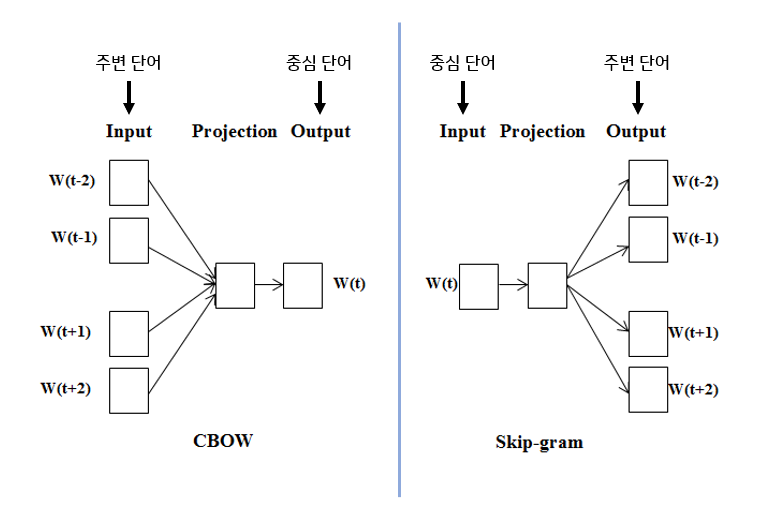
위의 그림처럼 CBoW는 주변 단어에 대한 정보를 기반으로 중신 담어의 정보를 예측하고, Skip-gram은 중심 단어에 대한 정보를 기반으로 주변 단어의 정보를 예측한다.
I like puppy로 예를 들어보자면 CBoW의 경우에는,
I [ -- ] puppy
Skip-gram의 경우에는,
[ -- ] like [ -- ]
인 것이다. CBoW와 Skip-grame 둘 다 [ -- ]에 들어갈 단어를 예측하는 과정으로 학습이 진행된다.
이렇게 문장으로 예시를 들어보면 단어 하나만 맞추면 되는 CBoW의 성능이 더 좋을것 같아 보이지만, 역전파의 관점에서 보면 Skip-gram에서 CBoW에서 일어나는 학습보다 더 많은 양의 학습이 일어나기 때문에 의외로 Skip-gram의 성능이 조금 더 좋다
모델 구조
- 입력층: 원-핫 인코딩 된 단어 벡터
- 은닉층: 임베딩 벡터의 차원수 만큼의 노드로 구성됨. 은닉층은 1개가 존재
- 출력층: 단어의 개수만큼의 노드로 이루어짐. 활성화 함수는 softmax를 사용함
fastText
OOV (Out of Vocabulary) 문제
~ 추가 예정 ~
Character level Embedding
~ 추가 예정 ~
