오늘 배운 내용은 코드는 나름 괜찮은 거 같은데 개념을 이해하는 난이도가 진짜 헬이었다. 통계를 처음 접한 입장에서는 진짜 어질어질하고 이런 걸 계속 쓴다고? 진짜야? 하는 생각이 많이 들었다.. 오늘 개념을 그래도 이해해놓으면 나중이 편하다고 하셔서 최대한 이해해보려고 했는데 그냥 외운 수준밖에 안된다 🤣🤣
가설 검정
가설 검정은 주어진 상황에 대해서, 하고자 하는 주장이 맞는가 틀린가를 판정하는 과정이다. 그 전에 검정과 검증의 차이를 짚고 넘어가야한다.
일단 검증은 법률용어로 어떤 사실의 진위를 판단하기 위해 증거자료를 수집해 옳고 그름을 증명하는 것이고, 검정은 일정 규칙에 따라 자격이나 조건을 검사해 결정하는 것이다. 검증이 Fact check라면 검정은 Test라고 볼 수 있다.
T-test
정확히는 Student T-test라고 한다. 강의에서 듣기로는 Student는 닉네임 같은 거라고... 자기 이름 대신 닉네임을 썼다고 했었다.
T-test는 두가지 방법이 있다. 그 방법들을 살펴보기 전에 알아야 하는 필수적인 개념들도 있다!
T-test Process
먼저 알아야 할 개념은 귀무가설과 대안가설 그리고 P-value다.
귀무가설(Null Hypothesis)은 검증하는 가설을 말한다.
대립가설(Alternative Hypothesis)은 기존의 가설과 반대되는 가설을 말한다.
그리고 P-value는 귀무가설에 대해서 얼마나 근거가 있는지에 대한 값을 0과 1 사이의 값으로 scale한 지표이다. 결과의 신뢰성을 보여주는 값으로 p-value가 작아질수록 가정하는 주장에 대한 신뢰도가 올라간다.
T-test의 과정은 5단계로 나눌 수 있다.
-
귀무 가설을 설정한다
-
대립 가설을 설정한다
-
신뢰도를 설정한다 => 모수가 신뢰구간 안에 포함될 확률, 보통 95% 혹은 99%를 사용한다
신뢰도 95%의 의미는 모수가 신뢰구간 안에 포함될 확률이 95%, 귀무가설이 틀렸지만 우연히 성립할 확률이 5%라는 의미이다 -
P-value를 확인한다
-
P-value를 바탕으로 가설에 대한 결론을 내린다
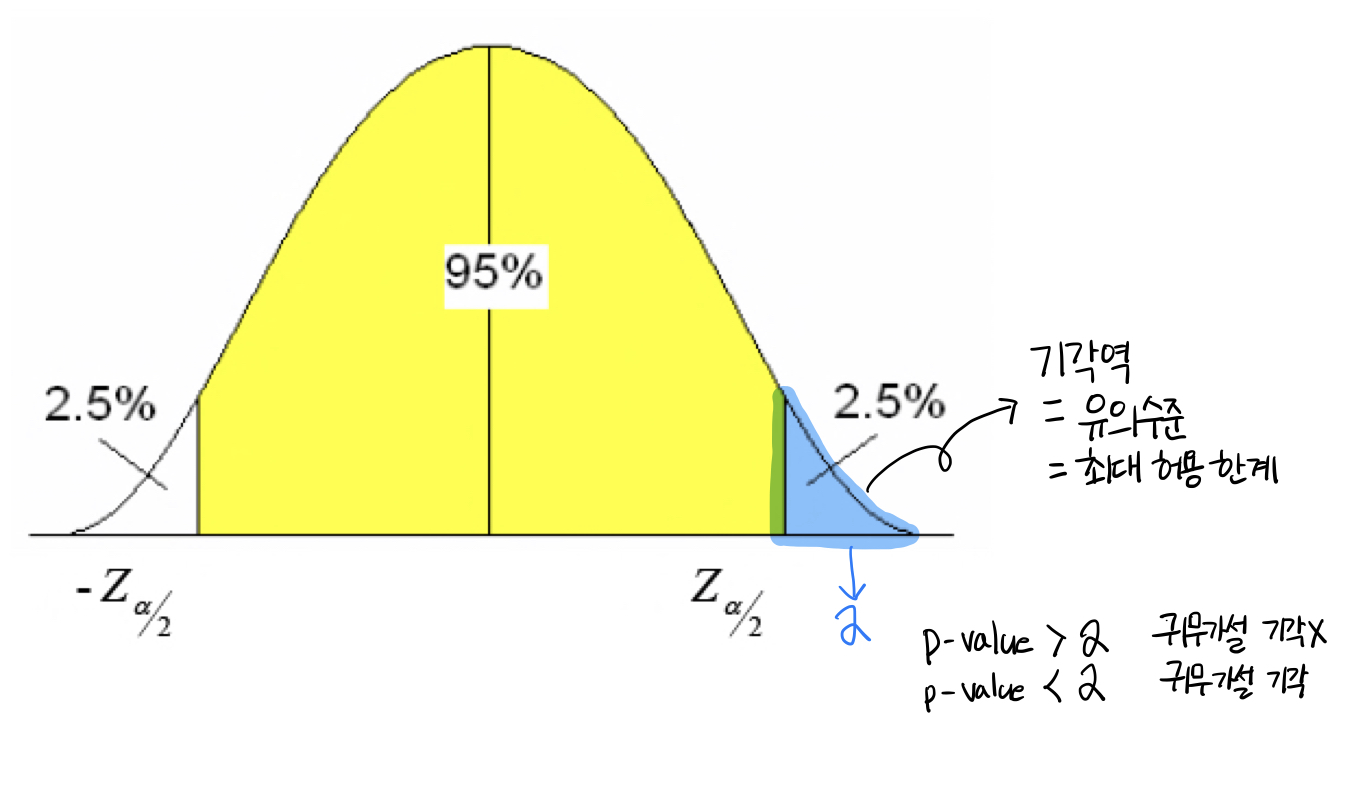
위의 그림에서 α는 유의수준(significance level)로 판단의 기준으로 사용하는 5% 혹은 1%를 말한다. 유의수준이 지나치게 크면 가설 검정 결과에 대한 신뢰도가 낮아지게 된다.
P-value의 기준
-
p-value < 0.01: 귀무가설이 옳을 확률이 1% 이하 -> 틀렸다(깐깐함)
-
p-value < 0.05: 귀무가설이 옳을 확률이 5% 이하 -> 틀렸다(일반적)
-
p-value가 0.05~0.1 사이인 경우: 애매함 -> 다시 해보기(데이터를 다시 뽑고, 샘플링을 다시 한 뒤 기존의 경험/인사이트를 바탕으로 가설에 대한 결론을 내리기)
-
p-value > 0.1 : 귀무가설을 틀리지 않았을 것이다. (옳다와는 약간 다름)
여기서 틀렸다는 귀무가설이 틀렸다는게 아니라 아닐 확률이 높다는 뜻이다. 그리고 틀리지 않았을 것이다는 옳다와 다르다고.. 나는 이게 너무 헷갈렸다. 틀렸으면 틀린거고 맞았으면 맞은거지 왜 이렇게 다들 애매모호한 표현을 써서 말을 하는건지...😂
One Sample t-test
1개의 샘플 값들의 평균이 특정 값과 동일한지 비교한다.
아래는 t 검정의 수식인데, 유튜브에서 강의를 보면서 예제를 들어주셨는데 아무래도 이거인 것 같아서 이렇게 정리를 했다. 혹시 틀렸다면 꼭 말해주세요! 이거인거 같아! 하면서 작성한 내용이라 저도 긴가민가합니다.

아래는 내가 강의를 들으면서 정리한 내용이다.

One Sample t-test는 ttest_1samp()함수를 이용하면 굉장히 쉽게 할 수 있다. 함수가 p-value값도 구해주기 때문에 p-value 값을 확인하고 판단을 내리면 된다.
from scipy import stats
stats.ttest_1samp(Sample_data, 비교하려는 값)Two Sample T-test
2개의 샘플 값들의 평균이 서로 동일한지 비교하는 방식으로 One Sample T-test와 사용하는 함수만 빼고 거의 비슷한 것 같다.
- 귀무가설: 두 확률은 같다 (차이가 없다)
- 대립가설: 두 확률은 같지 않다
- 신뢰도 설정
- p-value 확인
- 판단
from scipy import stats
stats.ttest_ind(Sample_data1, Sample_data2)위의 코드를 돌리면 One Sample T-test의 결과와 똑같이 statistic과 pvalue를 반환해준다.
