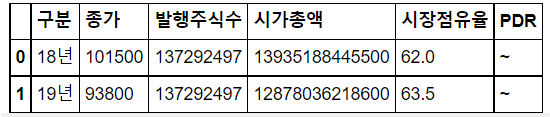
오늘 배운 내용 한 줄 정리
쉼표가 섞인 숫자를 replace를 통해 쉼표를 제거하고 apply 함수를 통해 전체 columns에 변경 내용을 적용한다.
문자열(string) 다루기
문자열(string)을 다루는 방법은 여러가지가 있는데 그 중에서 오늘 배운 내용은 바로 replace 함수를 사용하는 것이다. 사실 replace는 js에서 이미 쓴 경험이 있었기 때문에 오늘 강의는 좀 더 편안하게 들을 수 있었다.
replace 함수는 내가 바꿔야하는 문자열을 지정한 뒤 바꾸고 싶은 문자열을 지정해주면 내가 바꾸고 싶은 문자열로 바꿔주는 함수다.
replace 함수는 아래와 같이 사용한다
x = 'Py,tho,n'
x = x.replace(',', '')위와 같은 코드를 작성한 뒤 x를 print 해주면 다음과 같은 결과를 얻을 수 있다.

추가적으로 문자열의 길이는 len()을 통해서 얻을 수 있고, in 키워드를 통해서 문자열 안에 특정 문자가 포함되어 있는지도 알 수 있다. 반대로 문자열 안에 특정 문자가 포함되지 않았을 경우를 확인하려면 not in 키워드를 사용하면 된다.
text = 'If you saw me on the train would you look the other way'
if 'saw' in text:
print('saw is here!')
# 문자열 길이 확인
print(len(text))apply()
pandas의 apply 함수는 특정 columns 값들을 한번에 바꿔주는 함수이다. 나는 오늘 apply 함수를 사용해 string에서 쉼표를 제거한 뒤 int로 바꿔주는 작업을 했다.
def toint(x):
return int(x.replace(',',''))
df['매출액'] = df['매출액'].apply(toint)
df.head()위의 코드를 실행하면 데이터가 아래와 같이 바뀌는 것을 확인할 수 있다.

Na, NaN, Null, undefined
Na, NaN, Null은 모두 '정해지지 않은 값'이라는 의미를 갖고 있다.
NaN은 Not a Number의 약자라는 설명을 봐서 Na와 다른 것인줄 알았는데 구글링을 해보니 NaN(Na)라고 쓰시는 분들이 대다수인걸 보아 Na와 NaN은 같은 의미인 것 같다.
Undefined는 검색 결과가 거의 없는걸 보니 아무래도 파이썬에서는 사용하지 않는 값인것 같았다.
js의 경우 undefined로 인해서 에러가 떴기 때문에 파이썬도 비슷할 거라고 예상했는데 결과를 보니 없는게 확실한 것 같다😥
함수에서의 print와 return의 차이
함수에서 print와 return의 차이는 값의 반환이다. print는 단순히 결과값을 출력하기만 할 뿐이지만, return은 결과값은 변수에게 값을 돌려주기 때문에 함수 밖에서 변수를 print 해보면 결과하 확실하게 드러난다.
def test1(x):
return x * 2
def test2(x):
print(x * 2)
a = test1(5)
b = test2(3)
print(a, b) // 10, Nonetest1 함수의 경우는 return으로 결과값을 돌려줬기 때문에 10이란 결과가 나온다. 하지만 test2 함수의 경우는 return이 아닌 print문을 사용했기 때문에 변수 b에게 결과값을 돌려주지 못한다. 그래서 변수 b는 print 했을 때 None 값이 출력된다.
오늘의 뻘짓1, 2
- read_excel() 실행 중 오류
read_excel()로 엑셀 url을 열려고 했는데 코드를 실행하니 XLRDError가 발생했다. 그래서 바로 에러를 복사해서 구글링을 했더니
"엑셀 파일이 제대로 되어 있는지 확인해야한다. 본인은 파일 이름뿐만 아니라 엑셀 파일이 손상된 파일이었다."
"pandas 버전 확인 후 openpyxl 설치한다. read_excel의 인자에 engine='openpyxl'를 추가해준다."
라는 결과를 봤고, 그에 의문점이 생겼다.
"코드스테이츠 측에서 제공해준 url 링크인데 파일이 손상되었다고..? 심지어 코랩을 사용하는데 pandas 버전을 확인해보라고?"
그래서 확장자를 봤는데 csv인거다. 1일차에 read_csv를 렉쳐 노트에서 봤던게 생각이 나서 read_excel에서 read_csv로 바꿔서 썼는데 그게 바로 정답이었다.
- 오타때문에 오후 과제 시간을 모두 날려먹은 일
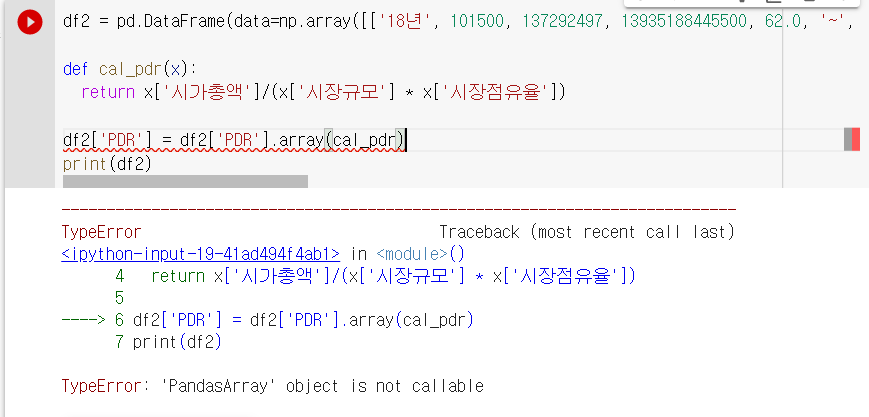
도저히 어디가 잘못됐는지 모르겠는데 계속해서 뜨는 TypeError: 'PandasArray' obejct is not callable ...
구글링으로 충분히 해결할 수 있을줄 알고 한 두시 반부터 열심히 구글링을 했던 것 같다. 근데 구글링으로 나오는 사례들은 모두 내가 해당하는 결과가 없었다.
결국 디코 제너럴 채널에다가 구글링을 어떻게 해야 좋을지까지 물어봤는데 해결을 못했다.
그래서 Q&A 시간에 질문 하려고 열심히 질문 정리까지 했는데 코드를 봐야하니 헬프 데스크에 올려달라고 하셨다.
문득 헬프 데스크는 안 찾아본게 생각이 나서 나같은 사례가 있는지 뒤늦게 찾아보고 없다는 걸 확인한 뒤 헬프 데스크에 코드를 올렸는데... 다른 분이 지적해주셨다.
df2['PDR'] = df2['PDR'].array(cal_pdr)문제점이 한눈에 보이셨나요...? 저는 이걸 오후 내내 못찾았습니다...🤣
apply를 써야하는데 array를 썼더라고요 제가... 네 이거때문에 에러가 났었습니다.
지적해주신 덕분에 후다닥 코드를 고쳤지만 저 코드는 이미 엉망진창이라서 돌아가지가 않더라고요.
주말에 다시 한번 도전해 볼 예정입니다. 주말이라고 해봐야 내일이지만...내일 도전해서 원하는 결과를 얻었으면 좋겠네요 😂😂
+) 추가적으로 나는 과제할때만 코랩을 사용하고 혼자 공부할 때는 주로 vscode를 사용하는데, 이미 pandas를 깔아놨음에도 불구하고 import 할 때 에러가 발생했다.
혹시라도 같은 에러가 나는 사람들을 위해서 구글링 한 결과를 적어보자면
- Ctrl + Shift + P
- Python:Select Interpreter 검색
- Python 뒤에 ('base':conda)가 붙은 걸 선택
간단하게 import 에러를 해결할 수 있었다.
또한, 방금 vscode를 사용해 df.head()를 찍어보고 안 사실인데 데이터를 다룰 때는 vscode보다 코랩이 훨씬 보기가 깔끔하고 편하다
↓ vscode에서 나오는 df.head() ↓

↓ colab에서 나오는 df.head() ↓