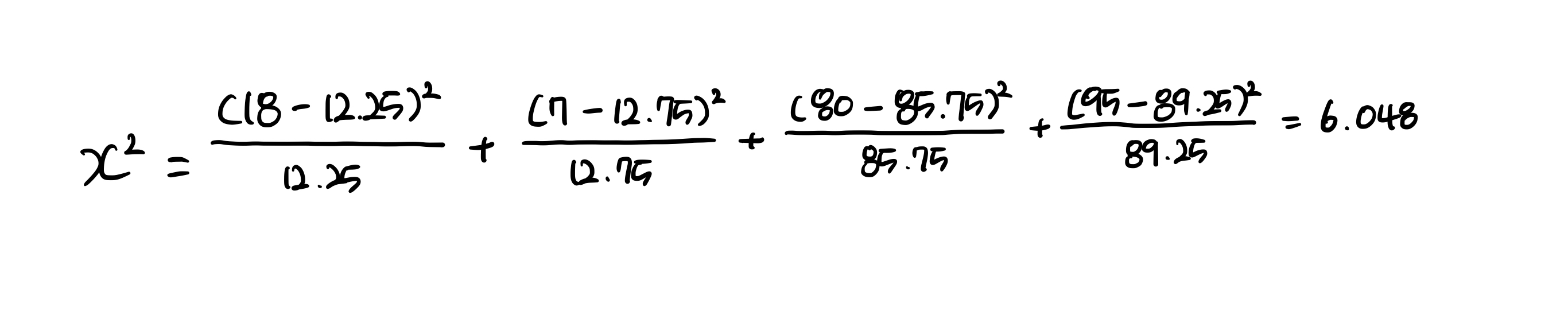지난주에 카이제곱검정에 대해서 배웠는데 오늘 과제를 풀면서 막히는 부분이 많았다. 그래서 따로 유튜브를 보고 정리를 한번 해봤다. 두번째 듣는 내용이라서 그런지 처음 들었을 때보단 이해가 잘 가는 것 같다
카이제곱검정 (x² test)
카이제곱검정은 주어진 변수가 모두 독립 변수 (Qualitative variable 혹은 Categorical variable) 일 때 사용한다. 다만 이때 데이터(자료)의 값은 모두 개수(count)여야한다.
또한, 그룹이 2개일 경우에는 Binomial Test를 실시하고 그룹이 여러개라면 카이제곱검정을 실시한다.
목적
변수가 한 개일 경우는 변수 내 그룹 간의 비율이 같은지 다른지, 변수가 두개일 경우에는 변수 사이의 연관성 (Association)이 있는지 없는지를 확인한다.
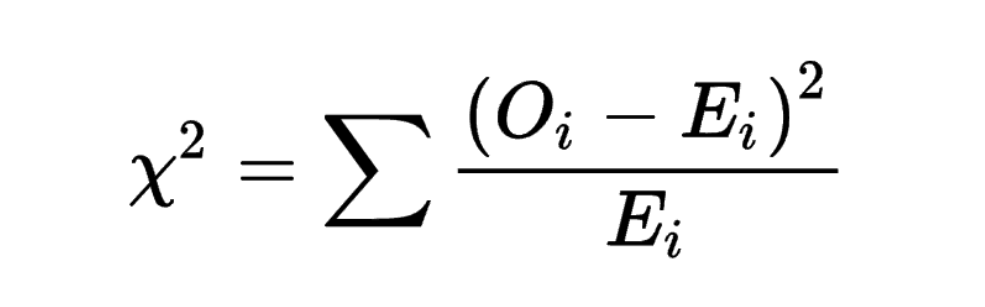
카이제곱검정의 값은 위와 같이 계산한다. 여기서 O는 관찰 빈도(Observed frequency)이고 E는 기대 빈도(Expected frequency)이다.
관찰 빈도는 데이터(자료)에서 자연적으로 주여지는 값이고, 기대 빈도는 별도의 방법으로 구할 수 있다. 기대 빈도는 개념적으로 이래야 한다는 기대 수치와 유사한 개념이다.
일원 카이제곱검정 (One-way x² test)
일원 카이제곱검정은 변수가 한개일 때 실시한다. 변수는 당연히 독립변수이다. 변수는 2개 이상의 범주(Category)를 가지며 코딩 시 한개의 column에 코딩한다.
일원 카이제곱검정에서 유의성이 의미하는 것은 무엇인가 다르다 정도이다. 여기서 다르다는 사전에 정해진 기대빈도와 다르다는 의미로 사용된다.
from scipy.stats import chisquare
chisquare(data, axis=None)
# return value: statistic, pvalue일원 카이제곱검정은 위의 코드로 실시할 수 있으며, 적합도(goodness of fit)이라고도 불린다.
이원 카이제곱검정 (Two-way x² test)
이원 카이제곱검정은 일원 카이제곱검정과 다른 점이 그저 변수가 두개라는 것 뿐이다! 변수가 2개이므로 당연히 column도 2개를 사용한다.
이원 카이제곱검정의 가장 단순한 형태는 2x2 형태로 분할표(contingency table)을 사용한다.
분할표는 데이터의 빈도만 단순화된 표에 작성한 것이다. 두 개의 변수를 행(Row)와 열(Column)으로 나누어 빈도를 정리한 표이다. 분할표를 통해서 행과 열 사이 즉, 두 변수 사이에 연관성이 있는지 확인해 볼 수 있다.
그에 대한 예제로 brain cancer와 cellphone 사용의 연관성을 확인해보려고 한다.
귀무가설: brain cancer와 cellphone 사용 간에는 연관성이 없을 것이다
대립가설: brain cancer와 cellphone 사용 간에는 연관성이 있을 것이다
기대빈도는 ((행 합계) x (열 합계)) / 총 합계 로 계산할 수 있다.
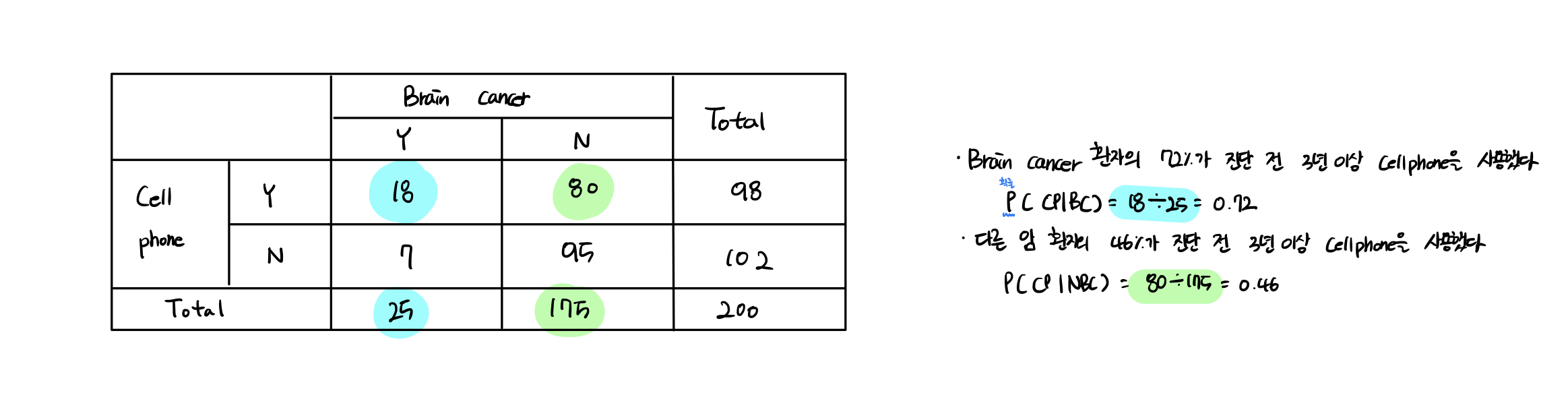
위의 표에서 확률을 구할 때는 확률을 구하고자 하는 칸과 해당 칸의 열 합계를 나눠주면 확률을 구할 수 있다.
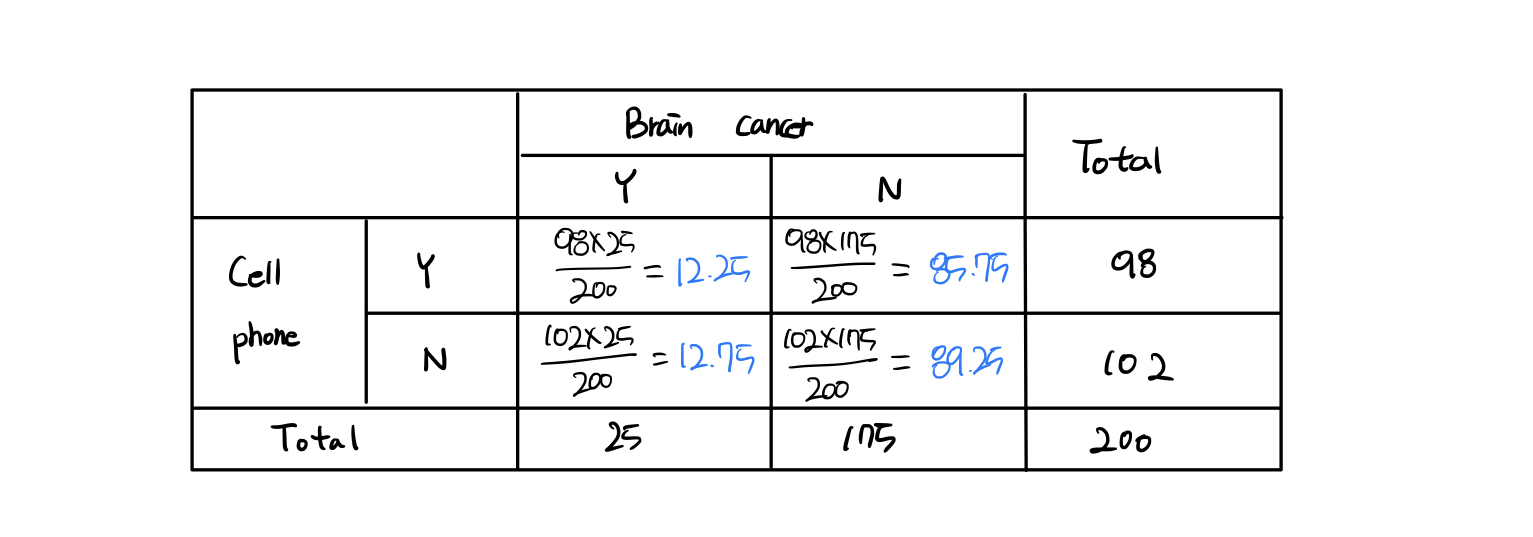
기대빈도는 위처럼 구할 수 있다. 우선 기대빈도를 구하고자 하는 칸의 행 합계와 열 합계를 곱해준다. 그 후 총 합계로 나눠주면 기대빈도를 구할 수 있다.
그 후 카이제곱검정의 값을 계산하면 다음과 같은 값이 나온다.