CLT (Central Limit Theorem)
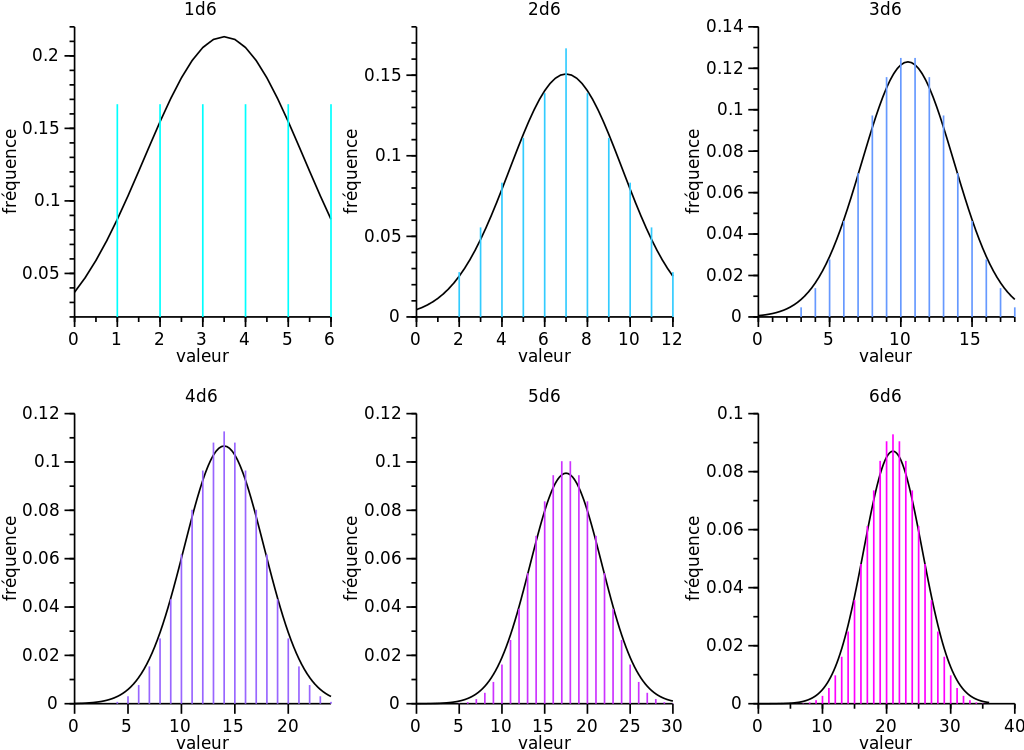
CLT, 즉 중심극한정리는 표본의 데이터가 많아질수록 표본의 평균은 정규분포에 근사한 형태로 나타나는 것이다. 이때 그래프는 종 모양을 띄게 되는데 이 종 모양에 관한 핵심 키워드는 바로 "평균" 이다
여기서 평균은 모집단으로부터 추출한 표본(sample)들을 평균한 것을 의미한다. 표본들을 무수히 많이 평균하게 된다면 표본 평균의 분포는 정규분포와 근사하게 된다.
모집단이 어떤 분포이던 상관없이 표본 평균의 분포는 정규 분포를 따르게 된다는 것이 바로 중심극한정리이다. 여러 모집단에서 따로 추출한 표본이어도 상관 없지만 독립적으로 추출한다는 가정이 필요하다.
신뢰구간
신뢰구간은 우리가 관찰한 것을 기반으로 합리적으로 추정된 값의 범위이다. 신뢰 백분율이 클수록 구간이 넓어진다.
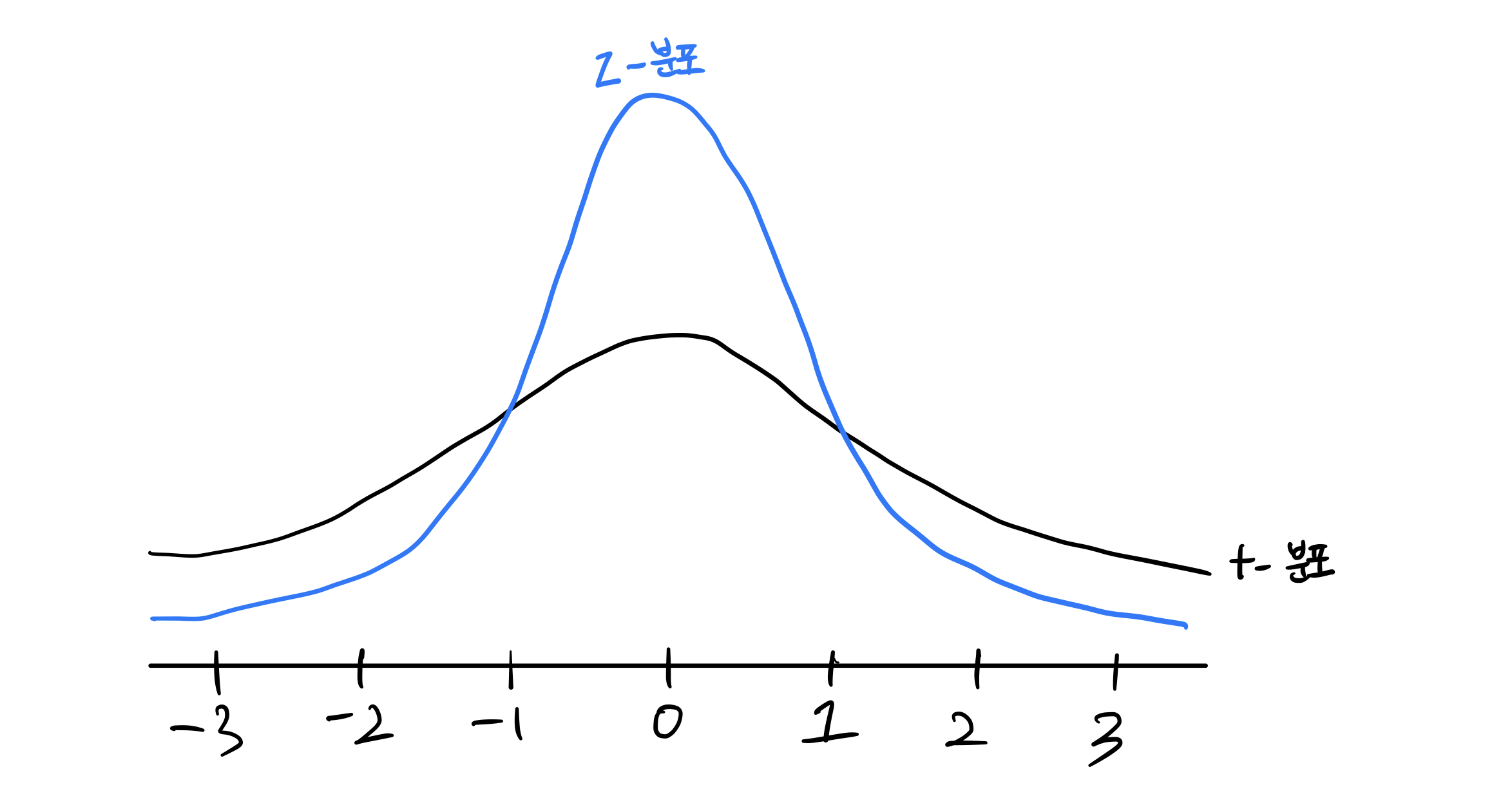
표본의 크기가 작아지면 표본 평균의 분포가 항상 정확히 정규화 되지 않으므로 데이터의 중간 95%가 어디 있는지 찾기 위해 z-분포 대신 t-분포를 사용하는 경우가 많다.
t-분포란 z-분포와 마찬가지로 단봉(unimodal)인 연속 확률 분포이다, 샘플링 분포를 나타내는 유용한 방법으로 정보의 양에 따라서 그래프의 모양이 바뀐다.
표본 크기가 작으면 정보가 적기 때문에 데이터가 많지 않을 때 추정치가 불확실 하다는 것을 나타내기 위해서 t- 분포의 꼬리가 두꺼워진다. 그러나 더 많은 데이터를 얻을 수록 t-분포는 z- 분포와 동일해진다.
신뢰구간 시각화
오늘 과제에서 신뢰구간을 시각화 하는 문제가 있었다. 시각화 할 때 plt.bar를 이용해서 시각화를 구현해야했는데 모르는 함수들 + 헷갈리는 함수가 있어 찾아서 정리해봤다.
df.sample()
df.sample 메소드는 df로부터 무작위로 표본을 추출하는 방법이다. 저번에도 한번 사용했던 메소드인데 오늘 사용하려니 이걸 어떻게 사용하는지가 가물가물해서..다시 한번 정리했다.
df.sample(
n = 추출할 표본 개수,
frac = 추출할 표본 비율,
replace = 복원 추출 여부 (True or False),
weights = 가중치 부여 (column name),
random_state = 난수 발생 초기값,
axis = 0(index 기준) or 1(column기준)
)
# random_state는 이 코드를 다시 돌려도 무작위로 뽑았던 값과 똑같은 값이 나오게 만들어준다.np.std()
np.std 메소드는 표준 편차 함수로 지정된 축을 따라 주어진 배열의 표준 편차를 계산한다.
import numpy as np
np.std(
array,
axis = 0(index 기준) or 1(column 기준) or None,
dtype = float64
)
std 메소드는 주어진 배열의 표준 편차 또는 지정된 축을 따라 표준 편차가 있는 배열을 반환해준다.
t.interval()
과제에서는 t.interval 메소드를 사용해서 신뢰구간을 구해서 대충 신뢰구간을 구하는 함수이지 않을까? 싶었는데 t.interval 키워드로 검색해보니 나오는 대부분이 영어라서 살짝..당황했다. 그래서 그냥 공식 문서를 참고하자! 싶어서 공식 문서를 봤는데 딸랑 한 줄이 적혀 있었다
interval(alpha, df, loc=0, scale=1)
Endpoints of the range that contains fraction alpha [0, 1] of the distribution
설명을 번역하니 "분포의 분수 알파 [0,1]을 포함하는 범위의 끝점" 이라고만 나와서 더욱 더 아리송해졌다...😐🤔😓😟
그래서 대충 신뢰구간을 구하는 함수인걸로..!
내가 과제를 풀면서 렉쳐노트를 참고해 이해했던 내용을 적어보면 아래와 같다!
from scipy.stats import t
CI = t.interval(
.95 (95% 신뢰구간),
dof (자유도),
loc = mean (평균의 평균),
scale = std_err(표준 오차)
)plt.axhline()
plt.axhline 메소드는 축을 따라서 수평선을 그려주는 메소드다. 비슷한 메소드가 3가지 더 있는데 axvline(축 따라 수직선), hlines(지정한 점 따라 수평선), vlines(지정한 점 따라 수직선)가 있다.
import matplotlib.pyplot as plt
plt.axhline(y = 수평선의 위치, xmin, xmax, colors, linestyle)
위의 코드에서 xmin과 xmax는 0에서 1사이의 값이 들어간다. 0은 왼쪽 끝, 1은 오른쪽 끝을 의미한다. 이에 대해서 이해가 잘 안간다면 예제 코드를 만들어서 한번 돌려보는 것을 추천한다. 왜냐하면 나도 글로 볼 때는 이해가 잘 안갔는데 내가 직접 숫자를 넣어가면서 코드를 돌려보니까 아 이게 이렇게 작동하는거구나~ 하는 부분이 있었기 때문이다. 꼭 코드를 직접 돌려보는 것을 추천한다 !!
plt.bar()
plt.bar는 막대 그래프를 만들어주는 메소드로 분명 한번 사용했던것 같은 메소드인데 오늘 처음 보는 파라미터들을 봐서 한번 정리해야겠다 싶어서 정리해봤다.
import matplotlib.pyplot as plt
plt.bar(x, height, color, xerr, yerr, capsize, edgecolor, linewidth)plt.bar에서 xerr 혹은 yerr을 파라미터로 추가하면 에러 바(error bar)를 추가할 수 있다고 한다. xerr을 파라미터로 추가할 경우 x 방향으로 error bar를 그려주고, yerr을 추가하면 y 방향으로 error bar를 그려준다.
capsize는 error bar의 위 아래로 모자를 쓴 것 처럼 수평의 짧은 줄이 다음과 같이 생기게 된다.
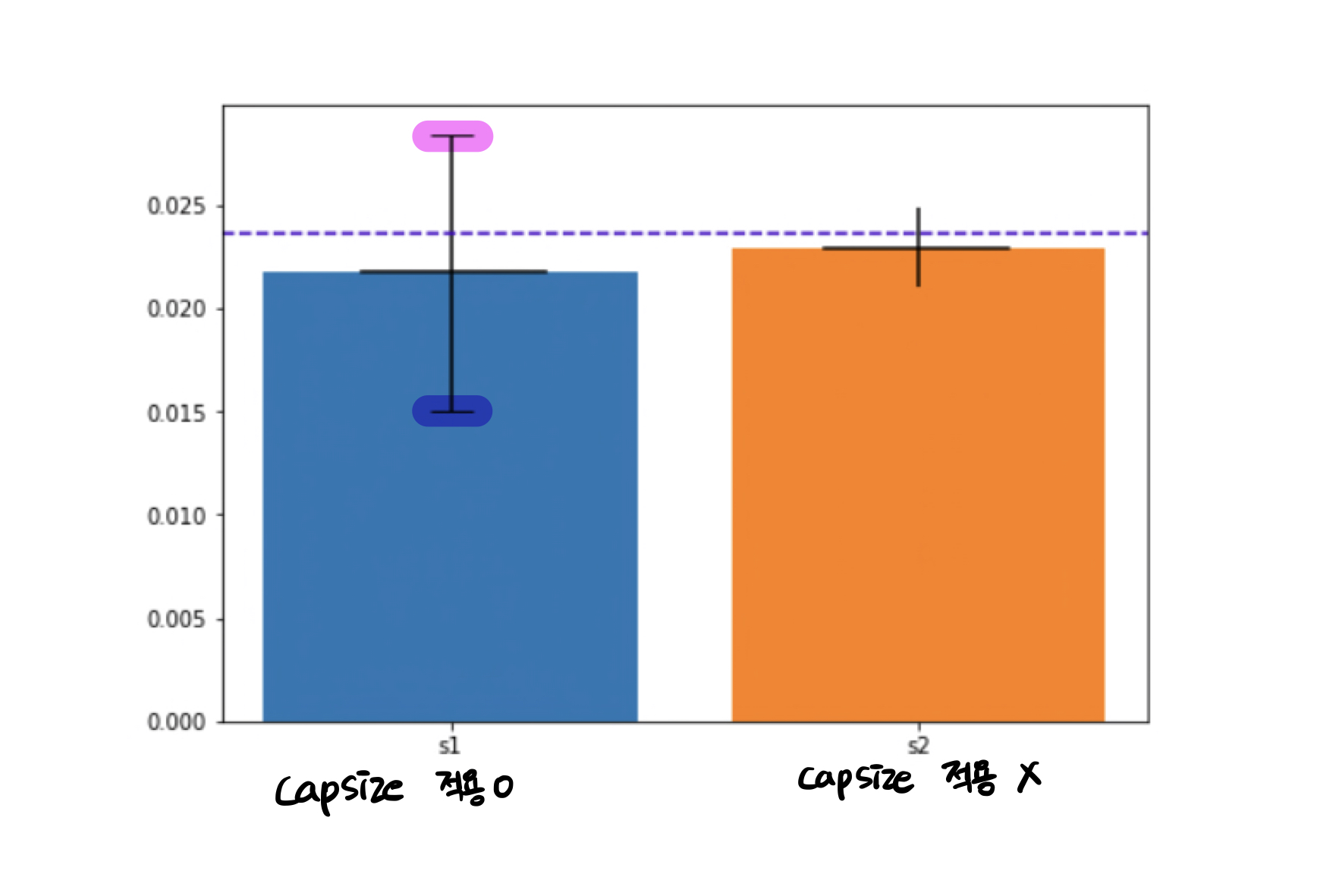
edgecolor는 막대 그래프의 경계선에 색을 추가하는 파라미터고 linewidth는 그 경계선의 두께를 지정해주는 파라미터다.
