CUDA Thread Hierarchy 정리
CUDA 프로그래밍 모델은 스레드→워프→블록→그리드 의 4단계 계층 구조로 이루어져 있음. cuda는 기본적으로 Thread 단위로 연산을 하기 때문에 Thread와 관련되 위계구조를 파악해야 함
1. Thread (스레드)
- 정의: 커널 함수 내에서 하나의 워크아이템(work-item)을 처리하는 최소 실행 단위
- 식별자:
threadIdx.x,threadIdx.y,threadIdx.z - 역할
- 배열 원소, 픽셀 좌표 등 하나의 데이터 조각을 처리
- 레지스터(초고속 저장소)에 스칼라 변수 저장
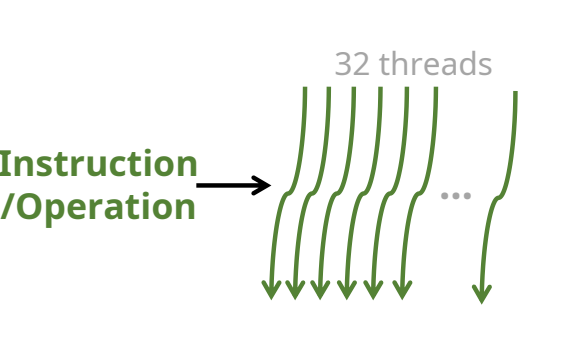
2. Warp (워프)
- 정의: 하드웨어가 동시에 실행하는 스레드 묶음(32개)
- 크기: 32 threads per warp (고정)
- 특징
- 모든 스레드가 lock-step 으로 동일 명령어 실행 (SIMT)
- 분기 다이버전스(divergence) 발생 시 부분 스레드는 대기 → 성능 저하
- TIP: 분기문(
if) 내부 코드가 워프 단위로 균일하도록 작성
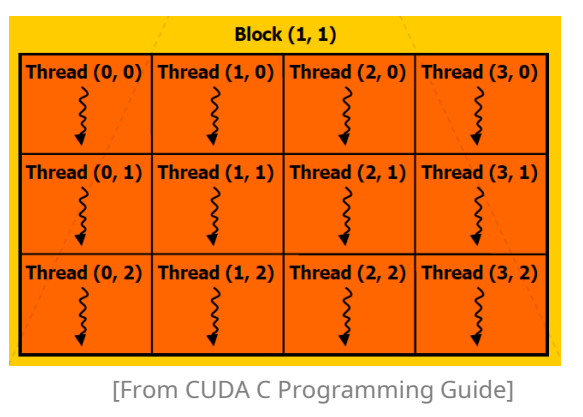
3. Block (스레드블록)
-
정의: 여러 워프를 포함하는 스레드 그룹
-
식별자:
blockIdx.x,blockIdx.y,blockIdx.z -
크기 제한
차원 최대값 x, y 1,024 z 64 총 스레드 ≤ 1,024 -
특징
- 공유 메모리(
__shared__) 와__syncthreads()동기화 사용 가능 - 워프 간 협업 및 데이터 재사용(타일링) 최적화
- 공유 메모리(
-
TIP: 블록 크기는 32의 배수(워프 크기)로 설정하고,
-
SM 자원(공유메모리·레지스터) 점유율(occupancy)을 고려해 블록당 스레드 수를 128∼512 사이로 튜닝
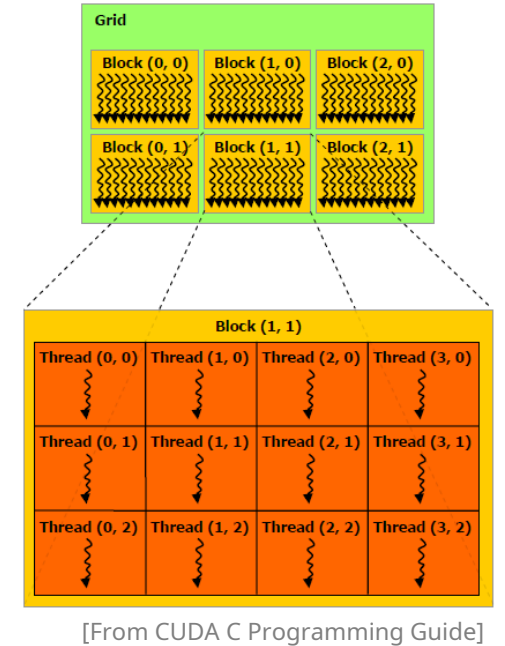
4. Grid (그리드)
-
정의: 하나의 커널 런칭에서 생성되는 모든 블록들의 모음
-
크기 제한
차원 최대값 x 2³¹ − 1 (≈2.1e9) y, z 65 535 -
특징
- 블록 간 공유 메모리·동기화 없음 → 독립 실행
- 여러 스트림(stream)에서 동시 실행 시 resident grids 한도(최대 128 grids on Ampere+)
-
TIP:
int threadsPerBlock = 256; int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock; myKernel<<<blocksPerGrid, threadsPerBlock>>>(…);

imageprocessing and Data science