cuda
1.cuda 내 메모리 할당

GPU 메모리를 동적으로 할당하는 함수. C의 malloc()처럼 동작하지만 GPU 내부에서 동적할당이 이루어진다.devPtr: GPU 메모리 주소를 받을 포인터size: 할당할 크기 (바이트 단위)cudaSuccess: 성공그 외: 오류 코드 (예: 메모리 부족)GP
2.CUDA Thread Hierarchy
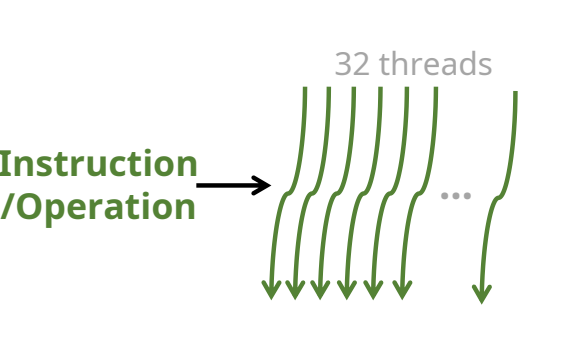
CUDA 프로그래밍 모델은 스레드→워프→블록→그리드 의 4단계 계층 구조로 이루어져 있음. cuda는 기본적으로 Thread 단위로 연산을 하기 때문에 Thread와 관련되 위계구조를 파악해야 함정의: 커널 함수 내에서 하나의 워크아이템(work-item)을 처리하는
3.CUDA에서 행렬곱 연산
정방행렬 $A,B\\in\\mathbb{R}^{N\\times N}$를 곱하는것을 쿠다로 구현하기 이전에 병렬로 연산하는 방법에 대해서 정리를 하면 다음과 같음. 먼저 각 행렬을 $p\\times p$개의 사이즈를 가지는 부분행렬로 나눈 다음에 각각 구간의 곱을 구한다
4.GPU 메모리 구조
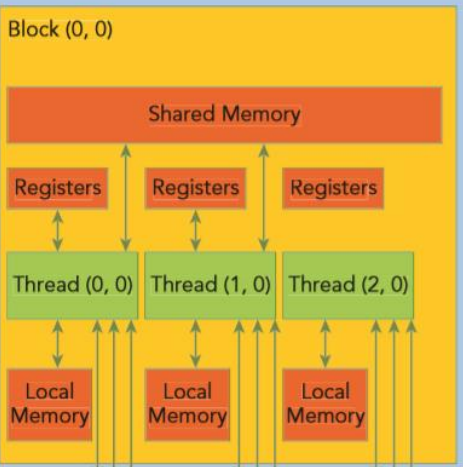
본인 사용중인 RTX 4090기준으로 스펙정리(chip nam : AD102-300-A1)위치: SM(Streaming Multiprocessor) 내부의 레지스터 파일 특징 4090기준 64K 32bit 레지스터가 개별 SM에 할당됨쓰레드 전용, 컨텍스트 스위칭
5.CUDA WarpShuffle
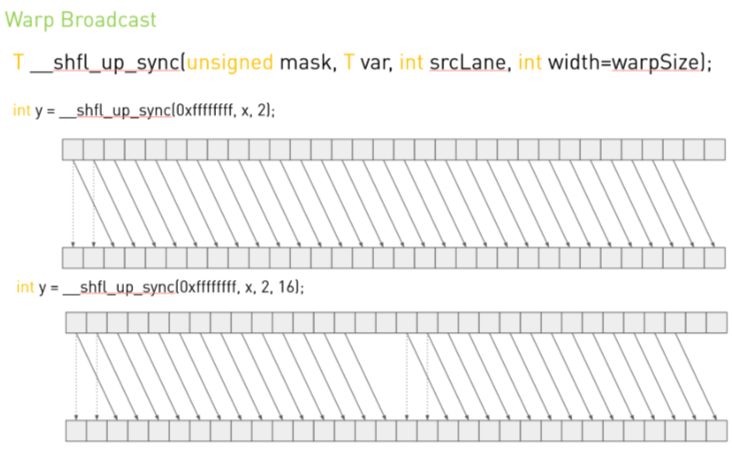
CUDA 에는 Warp 내 스레드 간 레지스터 수준으로 데이터를 교환할 수 있는 intrinsics 함수가 있음.공유 메모리와 \_\_syncthreads() 오버헤드를 줄여 성능을 높일 때 유용합니다.지원 버전: Compute Capability 3.0 이상헤더: &
6.CUDA 연산 시간 측정 정리
high_resolution_clock— 가장 정밀도가 높은 시계(clock) 타입time_point— high_resolution_clock::time_pointduration<double, std::milli>— time_point 차이를 밀리초(ms) 단위의