MINST 숫자 분류 학습
1. MINST 개요
- Mnist는 미국 국가 표준 기관에서 만든 숫자 데이터 셋을 의미함
- 각 직원의 손으로 쓴 숫자를 28*28 의 행렬형태로 표현되어 있음

- 캐글 대회에서 주어진 훈련셋은 Label과 픽셀좌표에 대한 값 정보를 CSV로 저장 해뒀기 때문에 별도의 텐서 데이터 셋으로 변환이 필요함
x_train = pd.read_csv('/kaggle/input/ncr/train.csv')
x_test = pd.read_csv('/kaggle/input/ncr/test.csv')
submit = pd.read_csv('/kaggle/input/ncr/sample_submission.csv')2. 학습 모델 개요
-
MNIST 학습을 위해서 DNN을 활용하여 학습하여도 되지만 픽셀의 위치가 바뀌거나 전혀 다른 이미지가 입력되면 학습에 한계가 명확하기 때문에 CNN을 활용하여 진행하려고함
-
CNN은 대표적으로 합성곱층과 풀링층을 통해서 학습을 진행하는데 합성곱층은 이미지의 각영영역에 커널이라는 필터를 적용하여 출력값을 뽑는데 사용하고, 풀링층은 이미지의 사이즈를 줄이기 위해 일정영역을 샘플링하는 방법임
-
2.1 Convolution layer
Convolution layer는 입력 행렬에 대해 커널필터를 곱하여 필터링 된 값을 출력 해줌.의 형태의 의 원소를 가진 행렬 커널을 이용하여 입력된 이미지와 곱셈 연산을 진행함
여기서 는 커널연산으로 출력되는 데이터 이고, 는 입력 되는 이미지를 의미함. 여기서 a는 커널 행렬의 , b는 를 의미하게 됨.
-
2.2 Pulling layer
풀링층은 이미지의 크기를 줄이기 위해 사이즈를 조절 하는 연산을 의미함풀링층에서 추출된 원소값을 의미하는 것이고
는 풀링 되는 서브 매트릭스의 사이즈, 은 서브매트릭스 의 좌표를 의미함. 일반적으로 가장 유의미한 데이터를 추출 하기 위해서 최대값을 활용하도록 되어있음 -
2.3 CNN layer 셋팅
최종 분류 DNN 설계는 생략하여 CNN층만 표현하면 아래와 같다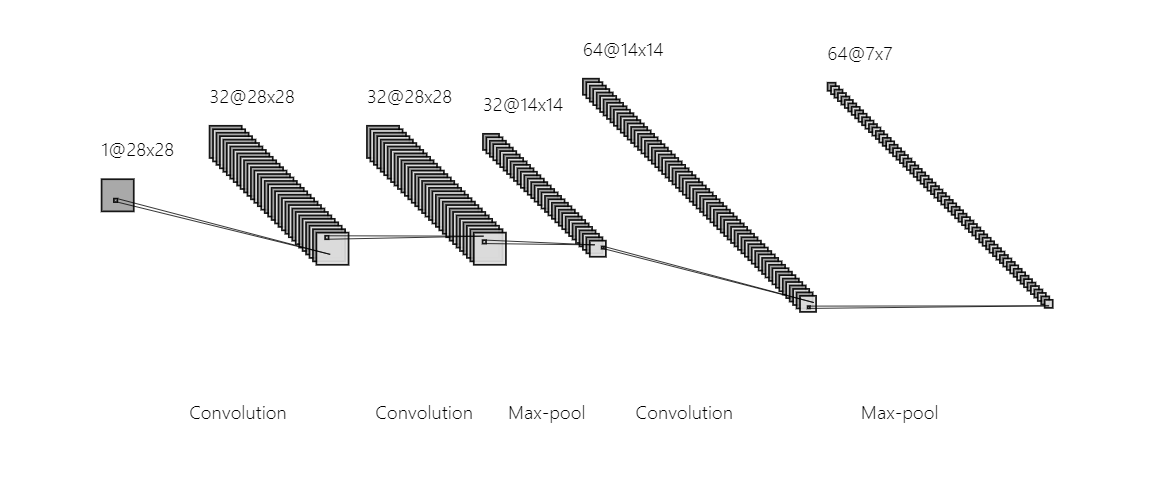 각 신경망 층의 커널과 입출력 정보
각 신경망 층의 커널과 입출력 정보 참고 사이트: https://alexlenail.me/NN-SVG/LeNet.html
참고 사이트: https://alexlenail.me/NN-SVG/LeNet.html
-
3. 입력 데이터 CSV 파일을 Tensor로 전환
-
우선 Kaggle에서 입력으로 주어진 Train.csv 데이터 파일을 확인해야 될 필요가 있음
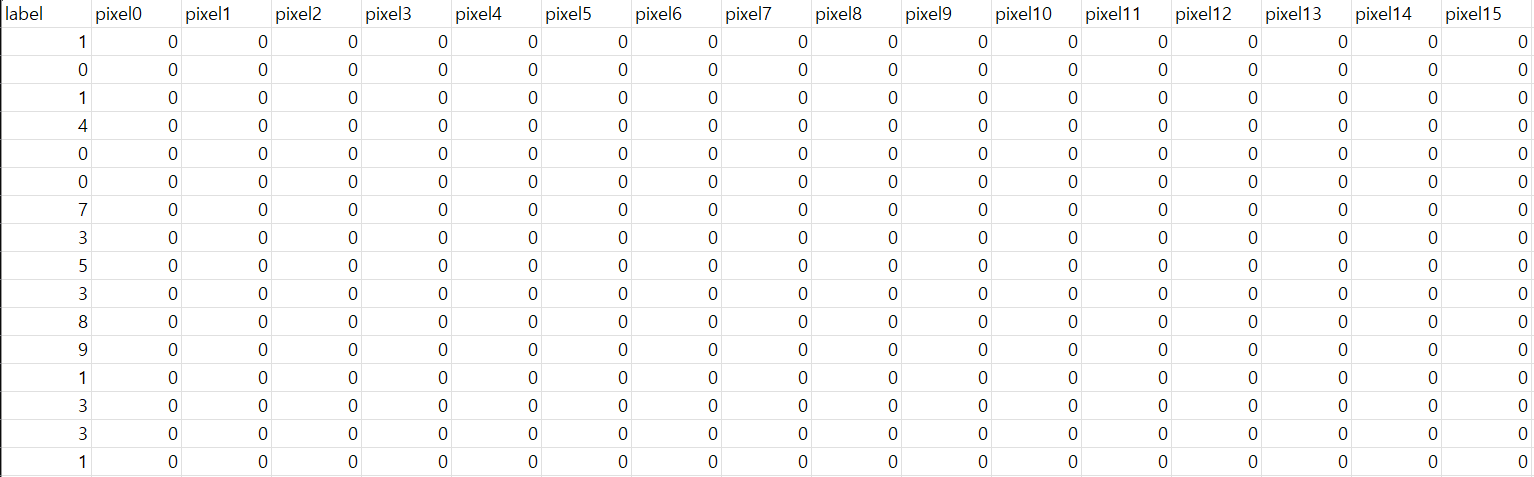 CSV 파일을 엑셀로 열어보면 위와 같이 되어있음. 우선 각 행은 이미지 1장에 정보를 나타내고 있고, 각 열은 아래와 같이 표현되어 있음
CSV 파일을 엑셀로 열어보면 위와 같이 되어있음. 우선 각 행은 이미지 1장에 정보를 나타내고 있고, 각 열은 아래와 같이 표현되어 있음- Label : 이미지가 표현된 숫자 정보 (0~9)
- pixel : 좌표위치 (0~783) 에 대한 픽셀정보
-
현재의 CSV파일이 MNIST 학습이 아래의 이유에서 학습에 적합하지 않음
- CSV 형태에서는 라벨과 픽셀정보가 분리되지 않았다는 것
- 이미지 정보가 1*784 크기의 1차원 벡터 형태로 되어 있다는것
- 데이터형이 Pandas로 읽어 들어오면 자료형이 Dataframe 임
-
그래서 아래와 같은 조건으로 데이터 데이터 전처리가 필요하다
- 라벨과 이미지를 분리하여 별도의 텐서를 생성해야 함
- 이미지 개별 크기를 사이즈의 3차원 텐서로 변환 시켜 주어야 함
-
위의 전처리를 파이썬으로 구현하면 다음과 같이 가능
# 데이터셋 불러오기
x_train = pd.read_csv('/kaggle/input/ncr/train.csv')
x_test = pd.read_csv('/kaggle/input/ncr/test.csv')
submit = pd.read_csv('/kaggle/input/ncr/sample_submission.csv')# 이미지 정보와 Label을 분리
x_label = x_train.loc[:,'label']
x_image = x_train.drop('label',axis=1)
test_label = x_test#Change data frame to Tensor
x_train_np = np.reshape(x_image,(-1,1,28,28))
print(x_train_np.shape)이미지 데이터프레임의 자료형을 numbpy로 전환하여 (42000, 1, 28, 28) 사이즈로 전환시켜주고
x_train_tenser = torch.Tensor(x_train_np)
x_train_tenser = x_train_tenser.float()
y_train_tenser = torch.Tensor(x_label)
y_train_tenser = y_train_tenser.long()
print(x_train_tenser[0])
print(x_train_tenser[0].shape)아래와 같이 tenser 자료형으로 변환 시켜준다
4. 학습셋 생성
- 이렇게 생성된 데이터셋을 pytorch로 학습하기 위해서는 아래와 같이 커스템 데이터 셋을 생성 하면 됨
class My_Number_set(Dataset):
def __init__(self,x_data,y_data):
self.x_data = torch.FloatTensor(x_data)
self.y_data = torch.LongTensor(y_data)
# 총 데이터의 개수를 리턴
def __len__(self):
return len(self.y_data)
# 인덱스를 입력받아 그에 맵핑되는 입출력 데이터를 파이토치의 Tensor 형태로 리턴
def __getitem__(self, idx):
x = self.x_data[idx]
y = self.y_data[idx]
return x, y
- 그리고 생성된 데이터셋을 다시 데이터크기가 100인 미니 배치로 다시 옮겨고 학습률과 epoch를 설정해준다
batch_size = 100
data_loader = torch.utils.data.DataLoader(dataset=TRAIN_MNIST,
batch_size=batch_size,
shuffle=True,
drop_last=True)
torch.manual_seed(777)
learning_rate = 0.02
training_epochs = 30- 이렇게 하면 최종적으로 batch size가 100이고 batch 수가 420 개인 학습셋을 생성 완료 함
5. CNN 모델 생성
- 위에서 CNN 모델을 pytorch로 다시 옮겨 준다
class CNN_arch2(torch.nn.Module):
def __init__(self):
super(CNN_arch2, self).__init__()
self.layer1 = torch.nn.Sequential(
torch.nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU())
self.layer2 = torch.nn.Sequential(
torch.nn.Conv2d(32, 32, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2),
torch.nn.Dropout(0.25))
self.layer3 = torch.nn.Sequential(
torch.nn.Conv2d(32, 64, kernel_size=2, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=1),
torch.nn.Dropout(0.25))
self.fc = torch.nn.Linear(12544, 10, bias=True)
torch.nn.init.xavier_uniform_(self.fc.weight)
def forward(self, x):
x_normal = x/torch.max(x)
out = self.layer1(x_normal)
out = self.layer2(out)
out = self.layer3(out)
out = out.view(out.size(0), -1) # 전결합층을 위해서 Flatten
out = self.fc(out)
return out- 여기서 forword 을 보면
라는 코드를 삽입 했는데, 이코드를 삽입하여 이미지간 콘트라스트 대비를 보정하기 위해서 0~1 사이의 값으로 정규화를 실행한다.x_normal = x/torch.max(x)
딥러닝 학습시 학습셋의 숫자범위가 넓어지는것도 학습에 영향을 주기 때문이 이부분을 보정하여 학습률을 높이는 방향으로 데이터셋의 전처리가 아닌 학습 모델에서 전처리를 다시한번 진행해준다.
6. CNN 모델 훈련
-
학습을 하기 위한 준비가 끝나면 학습을 진행한다.
model = CNN_arch2() criterion = torch.nn.CrossEntropyLoss() # 비용 함수에 소프트맥스 함수 포함되어져 있음. optimizer = torch.optim.Adagrad(model.parameters(), lr=learning_rate)우선 위와 같이 모델을 지정하여 주고 기준함수와 옵티마이저를 설정하여주고 아래와같이 학습을 진행함
for epoch in range(training_epochs): avg_cost = 0 for X, Y in data_loader: X = X Y = Y optimizer.zero_grad() hypothesis = model(X) cost = criterion(hypothesis, Y) cost.backward() optimizer.step() avg_cost += cost / total_batch print('[Epoch: {:>4}] cost = {:>.9}'.format(epoch + 1, avg_cost)) -
학습이 완료되면 테스트 셋으로 학습을 시켜주고 결과를 submisson에다가 기입한뒤 제출 하면 kaggle 제출 완료
with torch.no_grad(): X_test = x_test_tensor prediction = model(X_test) correct_prediction = torch.argmax(prediction, 1)df = pd.DataFrame(data=correct_prediction) submit['Label'] = np.array(correct_prediction) submit.to_csv('submission.csv',index=False) print("Your submission was successfully saved!") -
이렇게 하면 최종적으로 학습률이 98%인 MNIST 모델 훈련이 완료됨