SegNet: A Deep Convolutional
Encoder-Decoder Architecture for Image
Segmentation 논문에 대한 정리 내용
논문 출저 : https://arxiv.org/pdf/1511.00561v3
1. Introduction
- 기존에 자율주행등에 도입이 되면서 Unet 과같은 senetic segmentation의 수요가 늘어나는 상황임
- 하지만 기존 모델에서는 sub-sampling 및 max pooling를 진행하는 과정에서 세그멘트 사이의 경계선의 윤곽이 거칠어지는 문제가 발생을 했음.
즉, CNN layer 상에서 stride가 넓으면 누락된 픽셀에서의 feature를 캡쳐하지 못하게 되고, 커널이 작을수록 인접 픽셀의 관계만 연산 할 수 있는 한계가 존재함.
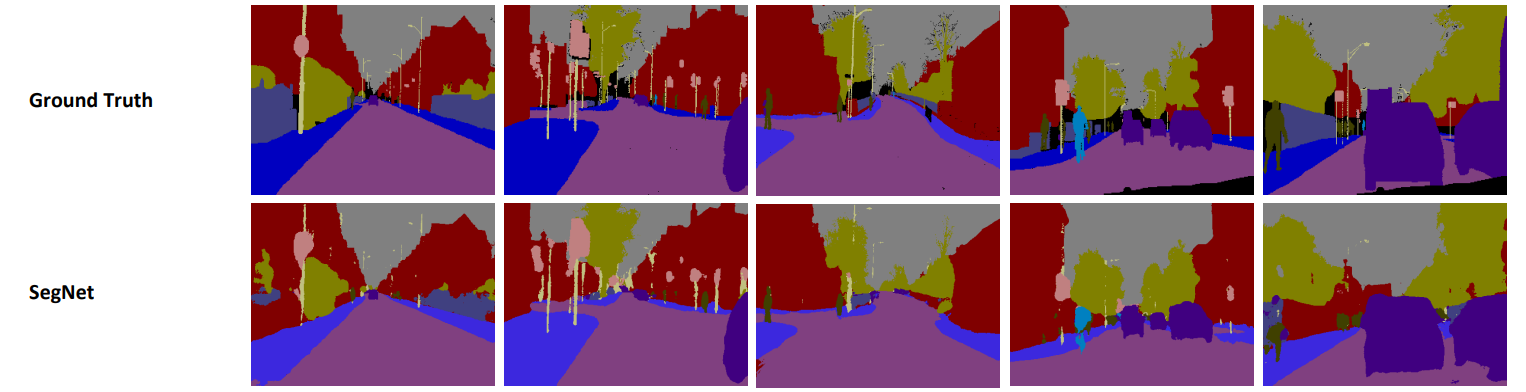

- 위의 이미지의 FCN의 segmetation의 결과와 같이 사물의 엣지를 명확하게 구분을 못하게 됨
2. Model archture
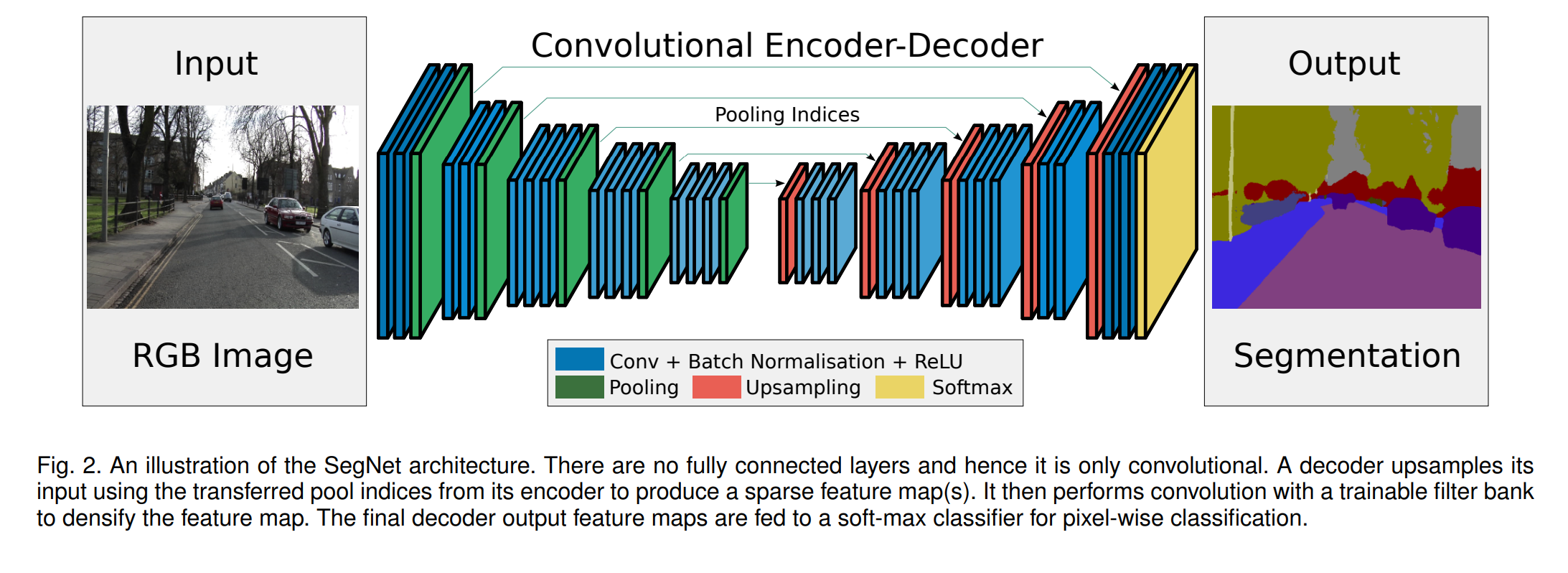
- 기존 모델 구조는 Unet과 유사함, 하지만 Decoding을 진행하는 중에 Encoding된 레이어에서 Pooling indces 정보만 가지고 up-sampling을 하는 것만 차이가 있음
Encoder
-
Encoder는 VGG16-Network의 첫 13-layer를 기반으로 구성되어 있음.
- 미리 학습된 모델을 가져와서 분류학습이 완료된 상태로 학습 초기상태로 구성하기 위함 이고
- 후반부 fully connected layer를 제거하여 파라미터 개수를 줄일 수 있음 (134M 에서 14.7M)
-
각 Feature map의 다운샘플링 과정에서는 stride = 2,kernel size =2 로 구성된 maxpooling을 하게 됨. max pooling으로 인해 작은 공간적 변화(spatial shift)에 대해서는 robust한 특성을 가지게 되지만 feature map의 크기가 작아질수록 공간 해상도의 정보가 같이 사라지는 문제점을 가지게 된다.
-
기존 U-net과 같이 maxpooling 이전에 레이어 정보를 저장하여 up sampling 과정시 전달하여줘도 되지만, Segnet에서는 메모리의 효율성을 위해서 maxpooling이 각 커널 max값의 index를 저장하여 메모리를 절약한다.
Decoder
- Decoder 과정에서 Upsampling에서 기존 Unet과 차이가 뚜렷함
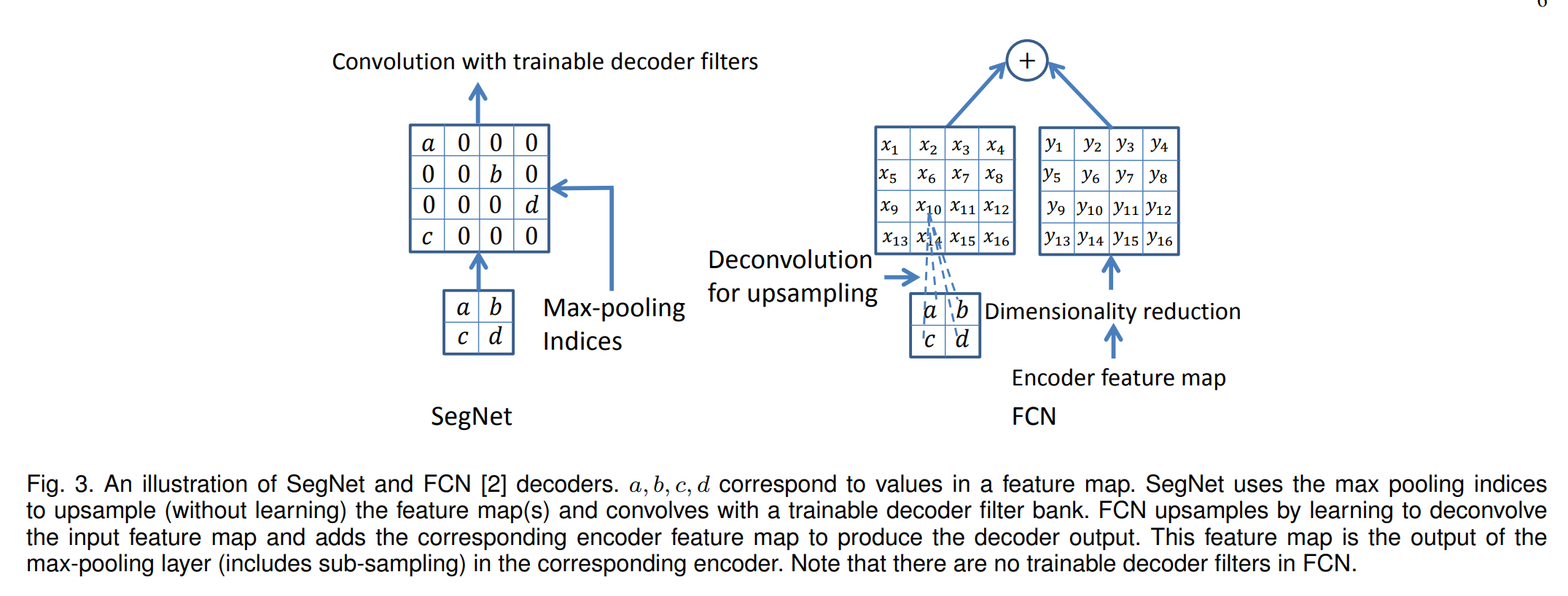
- 좌측의 FCN의 경우에는 RNN과 유사하게 동일한 채널의 Feature map을 합산해주는 과정에서 각 채널마다 행렬 덧셈을 진행하게 되고, 합산 후 Transpose CNN을 진행하게 되면서 각 채널마다 CNN 커널 연산을 다시진행해줘야 되기 때문에 계산의 복잡성이 증가하게 됨
- 반면 Segmap은 Encodering후 Maxpooling값의 인덱스 정보만 활용해서 업샘플링을 진행하기 때문에 별도의 CNN연산 없이 Up sampling이 가능한 장점이 있다.
Classifier
- Decoder를 통해서 입력사이즈와 동일한 텐서로 구성이 된다면, 각 pixel 마다 softmax classifier를 계산하여 확률을 계산함.
- 이를 통해서 최종 RGB 색깔을 분류하여 출력
3. Model 평가
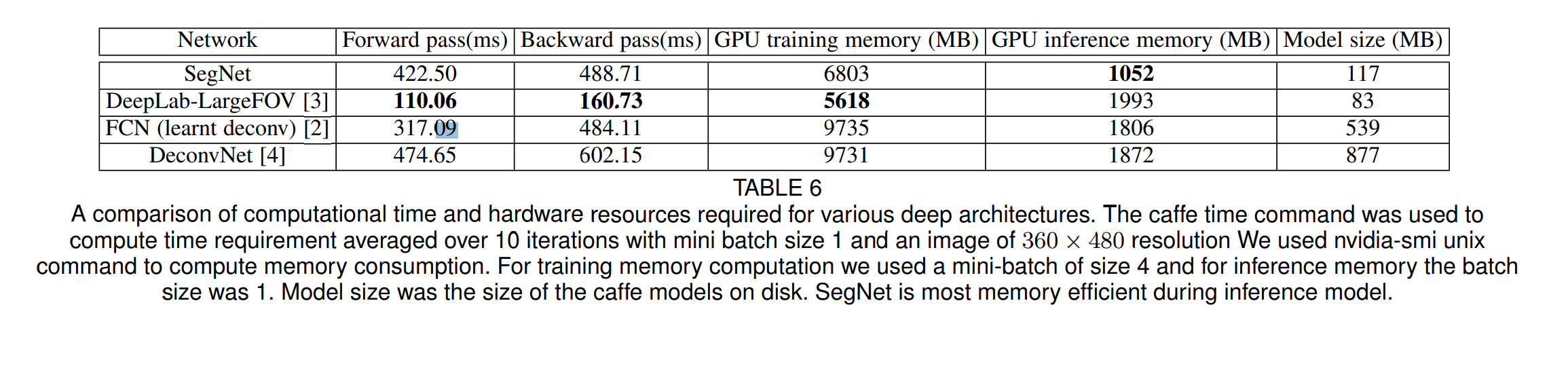
- 최종적으로 모델 평가를 해보면 FCN에 비해서 연산속도는 느리다. 왜냐하면 FCN 디코더의 경우에는 행렬연산을 하기 때문에 GPU 리소스를 효과적으로 활용할 수 있지만, 인덱스를 접근해야되는 Segnet의 경우에는 비효율이 발생함 (segnet : 422.5ms, FCN : 317.09)
- Decoder에서 Upscaling시 CNN레이어를 거치지 않기 때문에 더 적은 변수로 학습이 가능하기 때문에 GPU 메모리 점유율과 Model size에서는 큰 이점이 있다.

imageprocessing and Data science