Requirements
PIP Package
#pip install pytesseract pillowWindows Installation
Download Tesseract Windows Installer executable from the link below.
github.com/UB-Mannheim/tesseract/wiki
Install on Windows system.

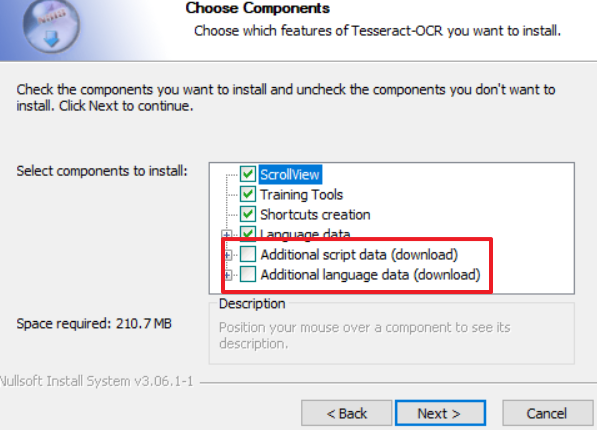
Don't forget to include the options, Additional script data and Korean under the subcategory of Additional language data:
Sample Code
from PIL import Image
import pytesseract
pytesseract.pytesseract.tesseract_cmd = r'C:\Users\User\AppData\Local\Tesseract-OCR\tesseract.exe'
# 이미지 파일명
image_path = r'C:\Users\User\Desktop\image_toLoad.png'
# 이미지 불러오기
img = Image.open(image_path)
# 이미지에서 텍스트 추출
text = pytesseract.image_to_string(img, lang='kor+eng')
# 추출된 텍스트 출력
print(text)Notice that configuring the absolute path of tesseract.exe was done at the beginning.
Verification
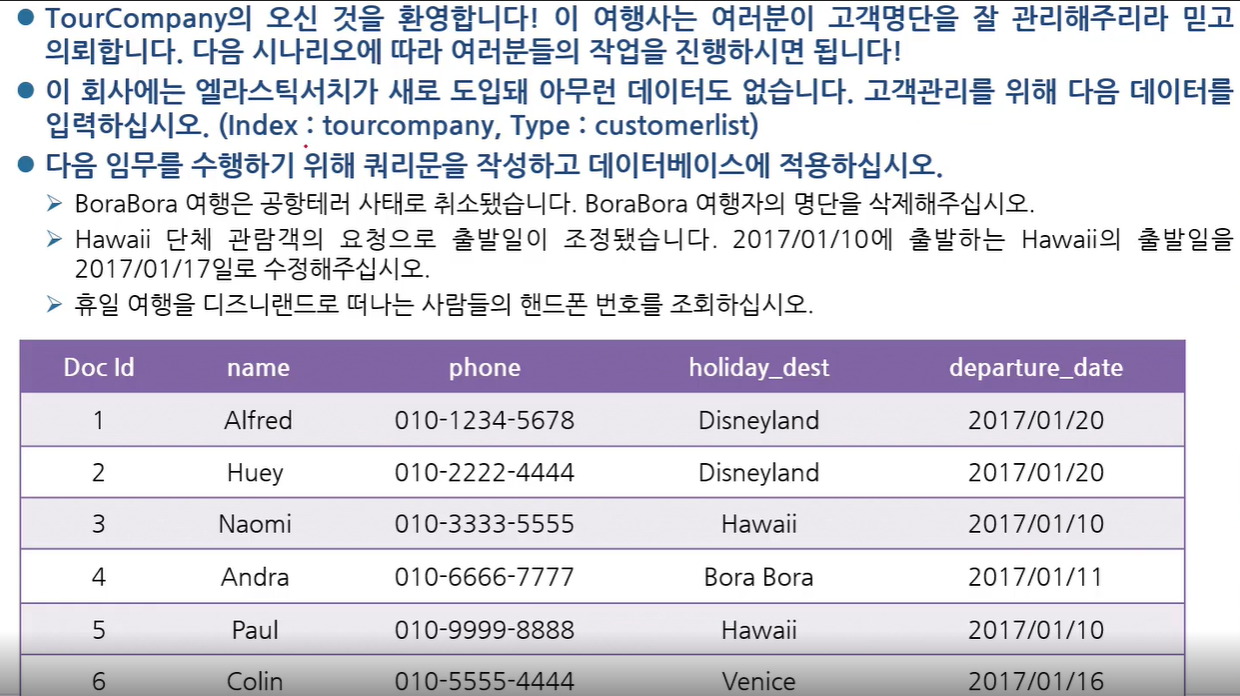
Sample Image
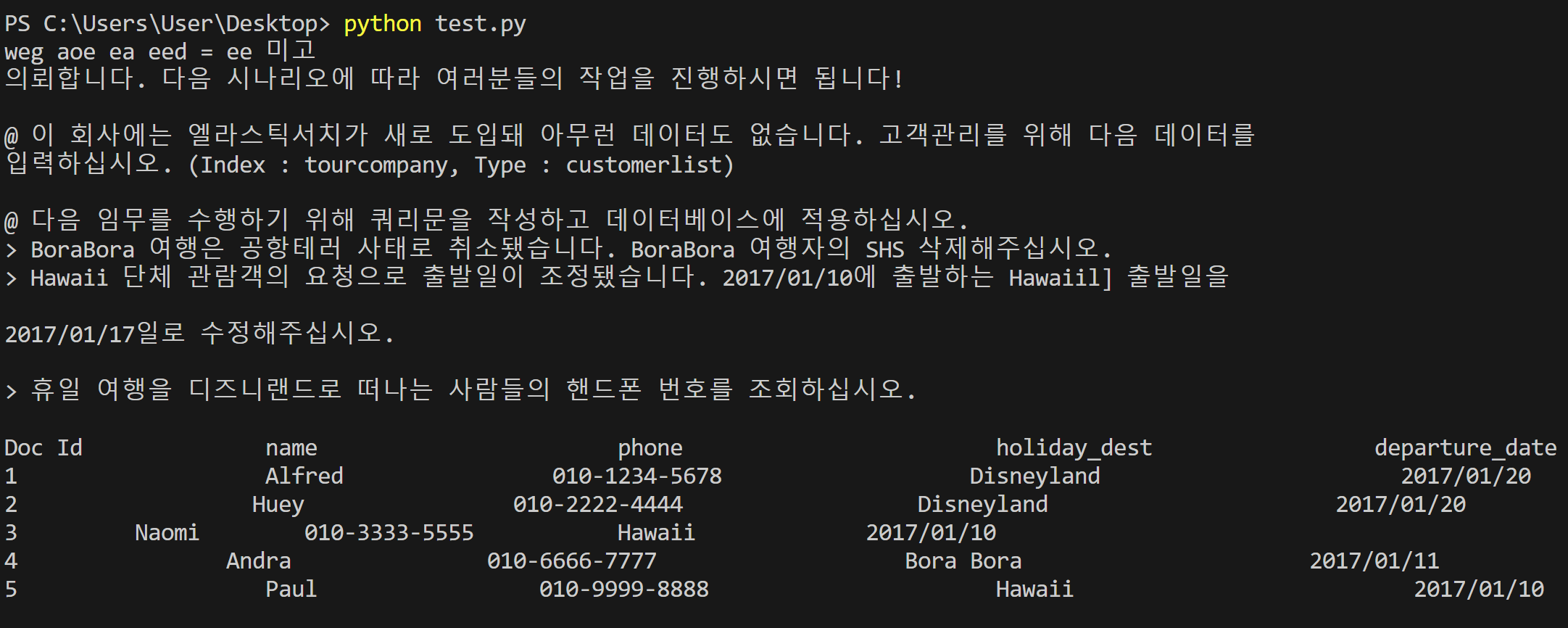
Result
Reference
https://najakprogram.tistory.com/8