
이번 글은 게임 전적 사이트 프로젝트를 진행하면서 성능 최적화하를 위해서 SQL 튜닝한 내용을 정리하기 위해 작성해보려고한다.
SQL을 튜닝한 부분은 방명록을 조회하는 기능이었다. 서비스 요구사항에는 유저를 검색하거나 유저의 전적을 확인하면 방명록을 보여주어야한다.
아래의 사진과 같이 하나의 방명록은 유저 이름도 보여주어야한다.
하지만 ERD를 살펴보면 유저와 프로필 테이블로 나누어서 설계하였다. 아래와 같이 설계한 이유는 프로젝트 진행 시, Spring Security를 이용하기 때문에 최소한의 필드로만 구성하기 위해 유저 테이블에 email과 password 필드로만 구성했다.
이외의 회원정보는 프로필 테이블을 생성하여 1:1관계를 맺었다.
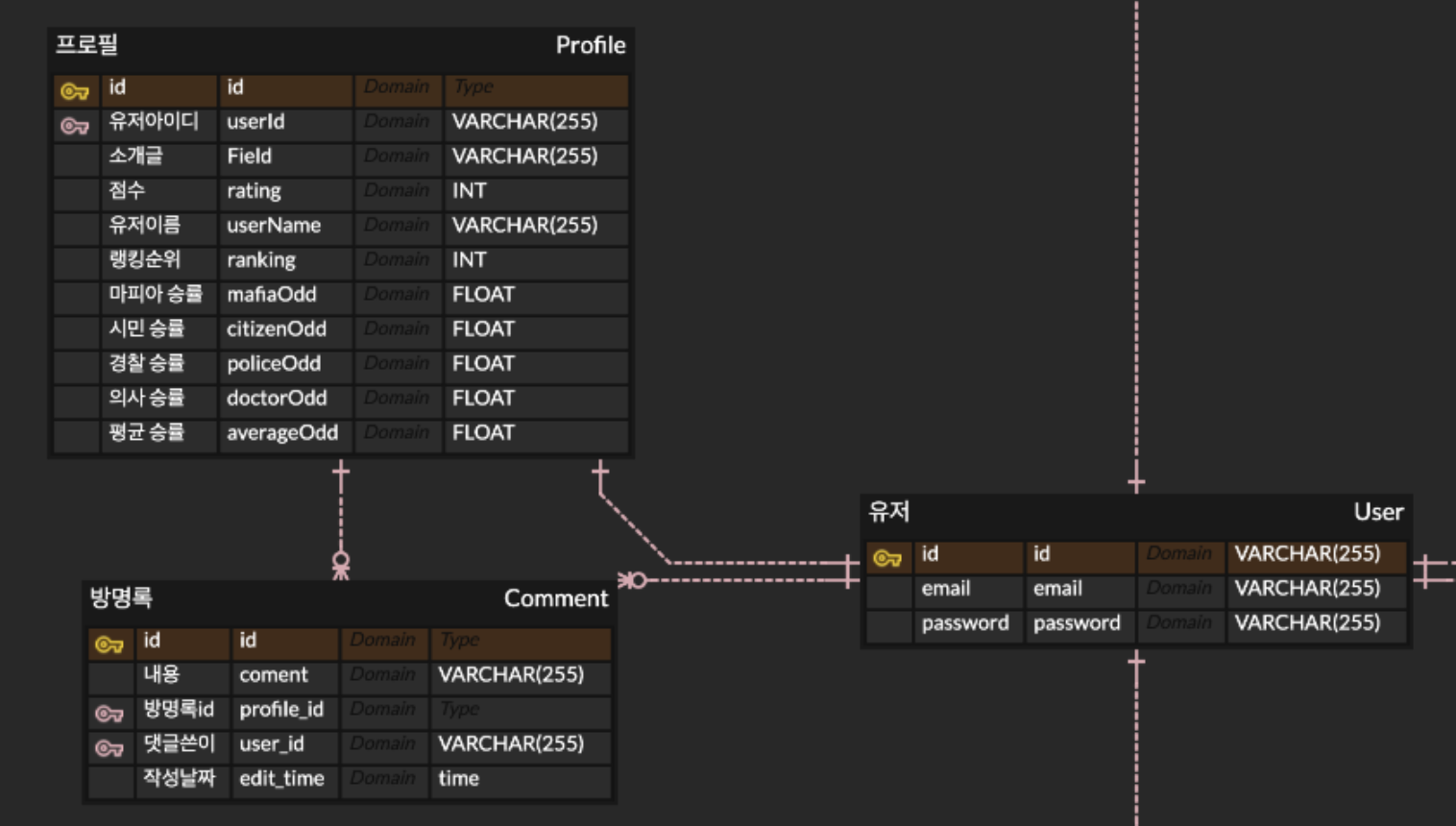
이러한 설계를 바탕으로 유저이름을 보여주는 방명록을 조회하기 위해서는 join이 발생한다.
그리고 방명록 조회는 많이 발생하기 때문에 성능 최적화를 하면 좋겠다는 생각을 하게 되었다.
기존의 코드는 thetaJoin을 이용해서 방명록을 조회했다.
ThetaJoin을 이용한 코드
QProfile profile = QProfile.profile;
QComment comment = QComment.comment;
List<CommentResponse> fetch = queryFactory
.select(
new QCommentResponse(
profile.userName, comment
)
)
.from(comment)
.join(profile)
.on(comment.user.id.eq(profile.user.id))
.offset(0L)
.limit(10000L)
.where(comment.profile.id.eq(프로필ID)).fetch();위 코드가 기존의 코드이다.
코드를 설명하면 Comment 엔티티의 userId와 Profile의 userId가 동일한 데이터 중 Comment 엔티티의 profileId가 요청 프로필 id가 동일한 데이터만 추출하여 CommentResponse 리스트로 반환한다.
그리고 성능 향상을 시키기 위해 고민을 하던 중 scalar subquery를 적용해보면 어떨지 고민하게 되었다.
scalar subquery를 생각하게 된 이유는 캐싱 효과를 통해 성능을 높일 수 있다는 것을 알게되었기 때문이다.
하지만 scalary subquery는 조건 데이터가 지속적으로 바뀌게 된다면 캐싱의 효율성이 떨어지고 서브쿼리는 반복수행 되기 때문에 오히려 성능이 떨어진다.
쿼리를 생각해보면 조건 데이터(프로필id)가 자주 변경된다. 그렇기 때문에 효율적이지 않을 것 이라고 생각한다. 하지만 하나의 프로필에 한 사람이 여러개의 댓글을 작성할 수 있기 때문에 데이터의 양이 많아진다면 성능이 향상될 수도 있다고 생각했다.
궁금증을 풀기위해 성능이 향상되는지, 떨어지는지 궁금해서 직접 테스트를 진행해보았다.
테스트 조건
- User Data Count : 1000
- Profile Data Count : 1000
- Comment Data Count : 60000
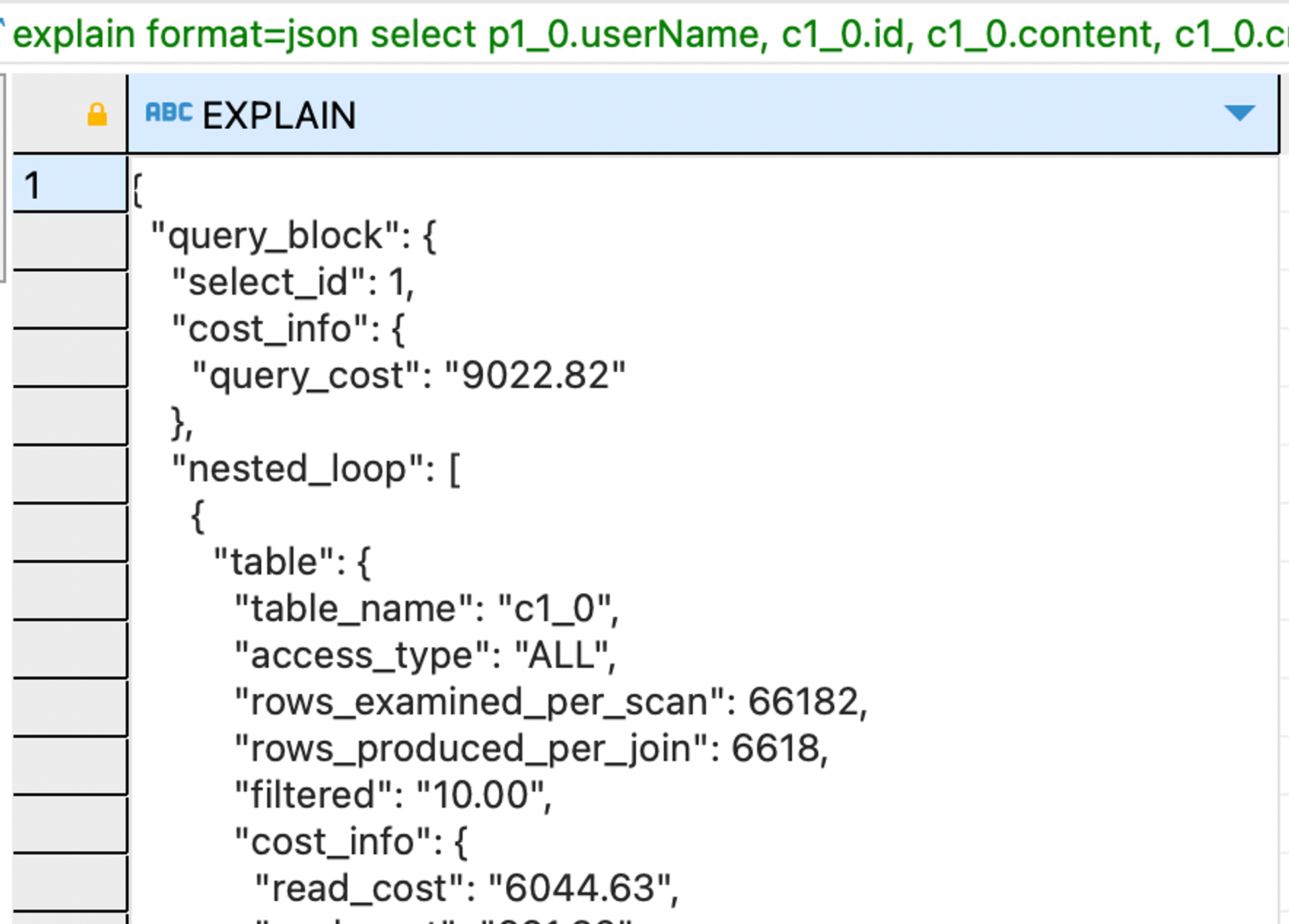
Theta Join 실행계획
explain format=json
select
p1_0.userName,
c1_0.id,
c1_0.content,
c1_0.createdAt,
c1_0.profile_id,
c1_0.updatedAt,
c1_0.user_id
from
Comment c1_0
join
Profile p1_0
on c1_0.user_id=p1_0.user_id
where
c1_0.profile_id=287 limit 0,1000;결과

Scalar SubQuery 실행계획
explain format=json
select
p1_0.userName,
c1_0.id,
c1_0.content,
c1_0.createdAt,
c1_0.profile_id,
c1_0.updatedAt,
c1_0.user_id
from
Comment c1_0
join
Profile p1_0
on c1_0.user_id=p1_0.user_id
where
c1_0.profile_id=287 limit 0,1000;결과

실행계획 결과를 살펴보면 thetajoin보다 scalar subquery를 사용한 경우가 cost가 훨씬 낮은 것을 확인할 수 있다.
직접 QueryDsl을 사용해서 조회할 때는 얼마나 차이나는지 확인해보았다.
Scalar SubQuery를 이용한 코드
List<CommentResponse> fetch = queryFactory
.select(new QCommentResponse(
JPAExpressions
.select(subProfile.userName)
.from(subProfile)
.where(subProfile.user.id.eq(comment.user.id)), comment
)
)
.from(comment)
.offset(0L)
.limit(10000L)
.where(comment.profile.id.eq(프로필ID)).fetch();위 코드는 Scalar SubQuery를 이용한 코드이다.
간단하게 코드를 설명하면 Comment 테이블에서 profileId가 요청 프로필 id를 추출하여 Profile 테이블에서 userId와 Comment 테이블의 userId가 동일한 데이터의 userName을 추출한 코드이다.
그러면 해당 쿼리문을 실행해서 실제로 time cost가 얼마나 차이나는지 확인해보았다.
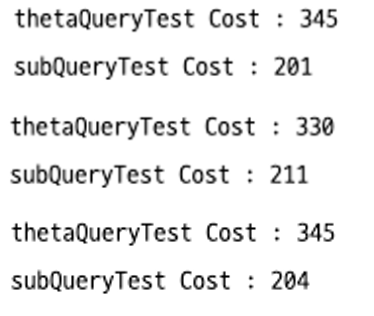
1만건 테스트
1회 호출

위 사진은 1회 호출 했을 때 time cost를 보여주고 있다. 3번정도 실행해보았는데 subQuery보다 thejoin 방식이 성능이 좋게 나오는 것을 확인할 수 있다.
10회 호출
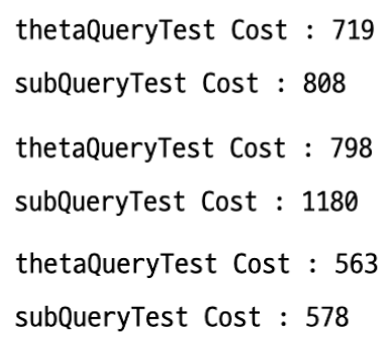
10회 호출하고 평균 cost를 살펴봐도 1회 호출이랑 비슷한 결과가 나온다.
5만건 테스트
1회 호출
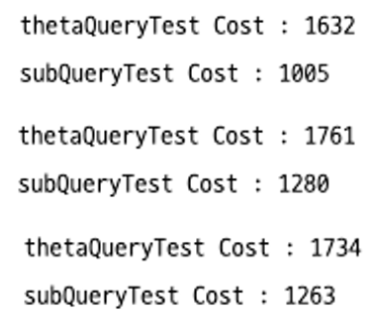
5만건의 데이터로 테스트를 진행해보면 1만건 데이터에 비해서 scalary subquery의 성능이 더 좋게 나오는 것을 확인할 수 있다.
10회 호출
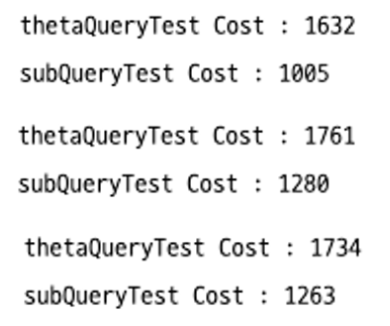
10회 호출하여 테스트해보아도 scalary subquery 더 빠른 것을 확인할 수 있다.
10만건 테스트
1회 호출

10회 호출
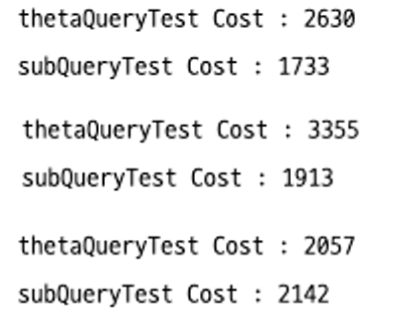
15만건 테스트
1회 호출
10회 호출
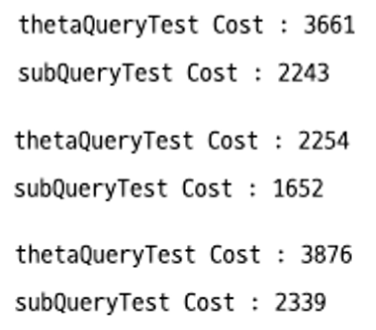
결과
테스트 결과를 살펴보면 scalar subquery를 사용하게 되면 성능이 향상되는 것을 확인할 수 있다.
데이터가 적다면 기존의 코드인 theta join방식과 큰 차이가 나지 않지만, 데이터의 개수가 많아지면 scalary subquery를 사용했을 때 성능 향상이 된다.
이전까지는 무조건 scalar subquery는 서브쿼리가 반복수행되어서 성능이 저하된다고 알고 있었다. 하지만 캐싱효과를 이용한다면 오히려 join방식보다 성능 최적화가 가능하다는 것을 알 수 있었다.
