
성능 테스트 진행 중 커버링 인덱스를 통해 성능을 개선한 사례를 정리해보려고한다.
성능 테스트 대상 API
성능 개선에 대한 내용을 정리하기 전, 테스트 진행 할 기능에 대한 설명을 작성해보려고한다.
해당 프로젝트는 투표형 커뮤니티로 게시글 생성 시, 게시글의 내용과 투표에 대한 설명글을 따로 작성하기 때문에 투표가 게시글에 종속되는 형태이다. 또한 게시글 상세보기 기능에서 투표 선택지의 개수와, 자신의 선택한 기록을 확인하는 기능 때문에 게시글, 투표, 투표 선택지, 투표 기록으로 테이블을 분리하였다.
그런데 게시글(투표)의 리스트 조회 기능에 있어서, 게시글/투표에 대한 정보 뿐 아니라, 사용자 정보, 투표 기록에 대한 정보도 함께 리스트로 보여주어야한다.
해당 기능을 구현하면서 조인이 많이 발생하기 때문에 데이터의 양이 많아질 수록 응답속도가 느려질 것 같다는 생각이 들었었다...
ERD
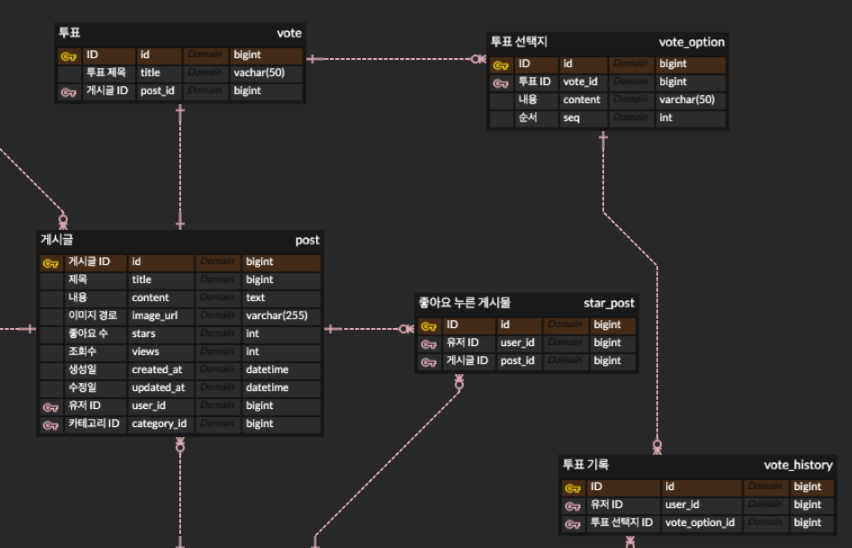
위 사진은 프로젝트를 진행하면서 설계한 ERD이며, 투표는 게시글에 종속되는 것을 확인할 수 있다.
실제 서비스 UI
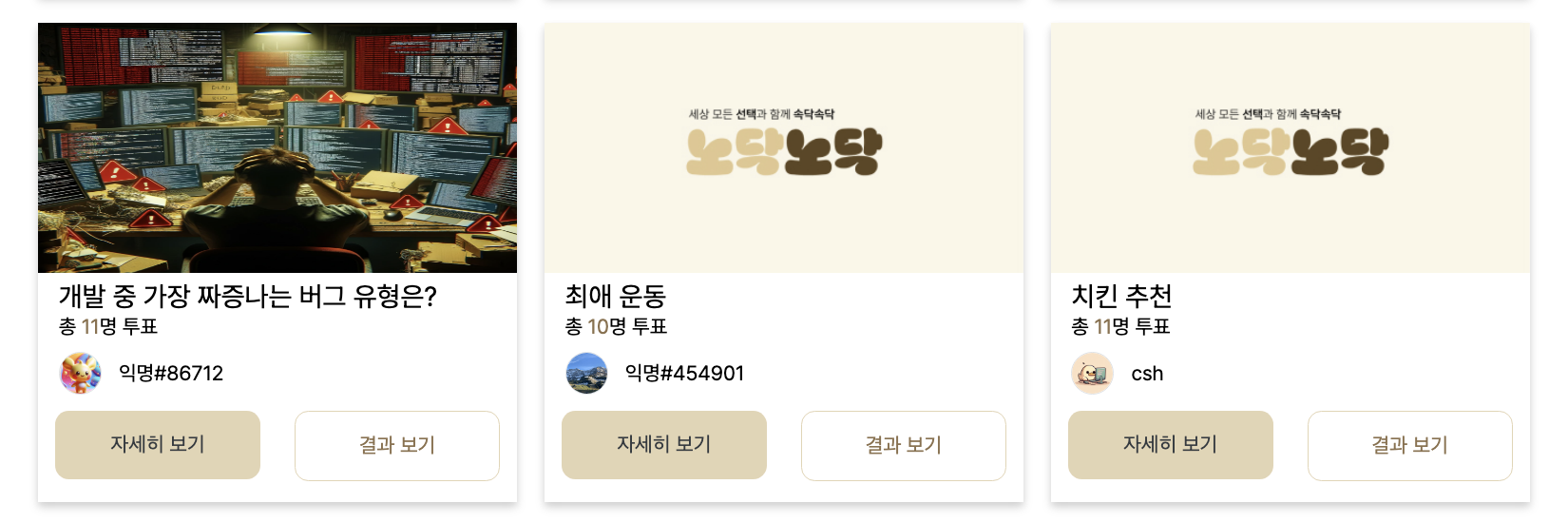
실제 서비스 화면을 보면, 게시글 리스트를 보면 현재 게시글에 종속된 투표에 참여한 유저의 수를 보여주는 것을 볼 수 있다.
즉, 투표에 종속된 투표 후보지들을 확인하고, 종속된 투표 후보지들에 종속된 투표 기록의 수의 총합을 구해야한다는 것이다.
구현 코드
JPAQuery<PostSearchResponse> query = queryFactory.select(
new QPostSearchResponse(
post.id,
post.vote.id,
post.title,
JPAExpressions
.select(voteHistory.count())
.from(voteHistory)
.where(voteHistory.voteOption.in(post.vote.voteOptions)),
post.user.nickname,
post.user.profileImageUrl,
post.imageUrl
)
)
.from(post)
.where(
searchCondition(request),
searchCategory(request)
)
.offset(0)
.limit(10)
.orderBy(post.createdAt.desc());게시글 리스트 기능 구현을 위해서 QueryDsl을 이용해 위 코드와 같이 작성하였다.
위 코드를 살펴보면, 메인 쿼리에서 검색 조건(게시글 제목, 내용, 카테고리)을 필터하였고, 그에 대한 조회 내용을 게시글 id, 투표id, 투표 제목, 투표 참여자 수, 작성자 이름 등을 projection하는 코드이다.
해당 글은 성능 개선에 대한 내용으로 쿼리 작성에 대한 자세한 내용은 생략하도록 하겠다..
성능 테스트
기능 테스트 확인 후, 성능 테스트를 진행하면서 응답속도가 느린 것을 확인하였다. 또한 게시글 리스트 조회 API는 사용자가 자주 사용하게 되는 서비스이기 때문에 해당 문제를 반드시 해결해야한다고 느꼈다.
성능 테스트 조건
회원 데이터 : 1,000건
게시글, 투표 데이터 : 40,000건
투표 후보 데이터 : 120,000건
투표 기록 데이터 : 1,200,000건
성능 테스트 1건 조회 결과

위 사진은 검색 조건도 없고, offset=0, size=10 인 데이터를 조회하는데 8736ms(약 8.7초)가 소비된 것을 확인할 수 있다.
스스로 생각해봤을 때, 8.7초라는 시간은 서비스를 이용하는데 사용자에게 굉장한 불편하다고 생각할 것이다. 왜냐하면 위 쿼리는 서비스를 이용하기 위한 첫 페이지에 호출되는 API이기 때문이다.
그 뿐만 아니라 만약 offset값이 높아진다면 응답 속도는 더욱 느려질 것이기 때문에 실행 계획을 통해 튜닝을 진행해야한다는 생각을 했다.
MySQL 실행 계획
해당 쿼리에서 어느 지점에서 문제가 있는지 실행 계획을 수립해보았습니다.

위 사진은 MySQL의 Explain 명령어를 통해 실행계획을 수립한 결과입니다.
vh1_0(투표 기록) 테이블을 참조한 결과를 살펴보면 sql명령어를 수행하기 위해 mysql이 찾아야하는 데이터 행 수(rows 값 : 1,203,630)인 것을 확인할 수 있다. 그리고 filtered를 확인해보면 100인 것을 알 수 있다.
그리고 옵티마이저가 SQL문을 해석하여 수행할 것인지에 대한 정보인 EXTRA 필드도 NULL인 것을 확인할 수 있다.
즉, vh1_0테이블을 참조할 때, Optimizer가 1,203,630의 행의 수를 스캔해야하는데 filtering을 수행하고 남은 레코드의 비율이 100%라는 것이다. 그리고 EXTRA 필드가 null이므로, 데이터 베이스의 최적의 성능을 달성하기 위해 노력하는 옵티마이저에게 전달하는 특별한 추가 정보가 없다는 것이다.
JPAQuery<PostSearchResponse> query = queryFactory.select(
new QPostSearchResponse(
post.id,
post.vote.id,
post.title,
JPAExpressions
.select(voteHistory.count())
.from(voteHistory)
.where(voteHistory.voteOption.in(post.vote.voteOptions)),
post.user.nickname,
post.user.profileImageUrl,
post.imageUrl
)
)
.from(post)
.where(
searchCondition(request),
searchCategory(request)
)
.offset(0)
.limit(10)
.orderBy(post.createdAt.desc());작성한 코드를 다시 확인해보자.
voteHistory 의 where절을 살펴보면, voteHistory 테이블에서 voteHistory.voteOptionㅇ post.vote.votesOption에 포함되는 값만 필터링을 해야한다.
그런데 약 120,000,000의 값을 스캔하는데 100모두 필터가 된다는 것은 post.vote.voteOptions를 정상적으로 필터하지 못했다는 것이다.
이러한 문제를 해결하기 위해서 covering index를 사용하기로 결정했다.
covering index는 쿼리에서 필요한 모든 데이터를 인덱스 자체에서 가져오는 인덱스를 말한다.
즉, 쿼리가 필요로하는 모든 컬럼에 대한 값을 인덱스에서 직접 가져올 수 있다는 것이다.
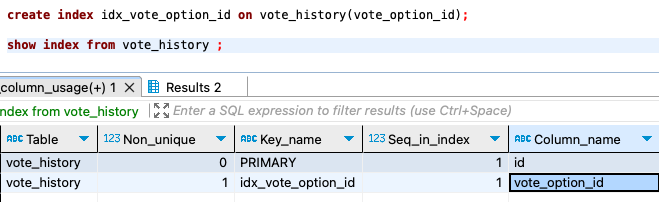
이처럼 게시글 리스트의 응답값 중 하나인 투표 참여자 수 결과를 얻어내기 위해 voteHistory 테이블에 vote_option_id의 인덱스를 추가하였다.
그리고 다시 실행 계획을 살펴보자.

vh1_0 테이블을 참조하는데 있어서 covering index가 사용된 것을 볼 수 있다. (vh1_0 테이블을 참조한 행의 extra 값이 *Using Index)
그러면 쿼리에 대한 응답속도가 얼마나 빨라졌는지 확인해보자.
성능 개선 후 실행 속도

실행속도가 튜닝 전 보다 훨씬 빨라진 것을 확인할 수 있다.
약 8.7초 정도가 소요되었는데, 현재는 약 0.5초로 줄어든 것을 확인할 수 있다.(약 92.8% 정도의 성능 향상)
데이터 수에 따른 실행 속도를 비교해보자.
데이터 건 수 실행 속도 비교
테스트 1
- 검색조건
- 게시글 / 투표 데이터 : 100건
- 투표 후보 데이터 : 300건
- 투표 기록 데이터 : 3,000건

테스트 2
- 검색조건
- 게시글 / 투표 데이터 : 1,000건
- 투표 후보 데이터 : 3,000건
- 투표 기록 데이터 : 30,000건

테스트 3
- 검색조건
- 게시글 / 투표 데이터 : 5,000건
- 투표 후보 데이터 : 15,000건
- 투표 기록 데이터 : 150,000건

테스트 4
- 검색조건
- 게시글 / 투표 데이터 : 10,000건
- 투표 후보 데이터 : 30,000건
- 투표 기록 데이터 : 300,000건
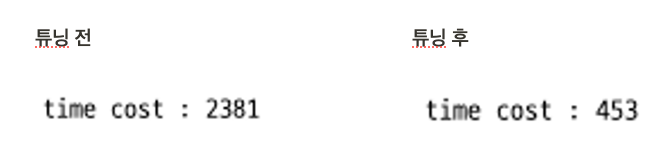
테스트 5
- 검색조건
- 게시글 / 투표 데이터 : 30,000건
- 투표 후보 데이터 : 90,000건
- 투표 기록 데이터 : 900,000건

