Saito et al, Maximum Classifier Discrepancy for Unsupervised Domain Adaptation, CVPR 2018에 대한 간단한 리뷰
기존 DANN을 이용한 Domain adaptation의 문제점
기존 DANN은 Feature Generator , 그리고 generated 된 feature가 source / target 중 어느 데이터에서 추출된 것인지를 구별하는 classifier 를 바탕으로 적대적 학습을 진행한다. 기존의 문제는, 모델 방식이 Source와 Target의 Feature 공간을 맞추는 데에 너무 집중한 나머지, Label boundary를 고려하지 못했다는 데에 있다.
예를 들어, Label classifier 를 Source domain에서 학습을 시키고, adaptation을 통해서 target sample을 source domain에 가깝게 했다. 그렇다고 해서, target sample이 올바르게 분류된다는 보장은 없다.
이러한 문제점을 해결하고자, 본 논문에서는 두 개의 label classifier을 이용한 새로운 방법론을 제시한다.
Proposed Method
두괄식으로, 먼저 제안된 방법론 먼저 제시한 후, 이에대한 직관적 설명과 이론적인 설명을 덧붙이도록 한다.
Discrepancy Loss
논문에서 두 분포 간의 discrepancy는 다음과 같은 식으로 정의한다(L1 distance) 이러한 정의는 후술할 이론적 내용과 연관이 있다. 추가적으로, L2거리를 loss로 정의하면 잘 작동하지 않는다고 한다.(경험적으로)
Step A
우선 Sample domain에 대하여 두 개의 classifier 와 를 train 한다.
where
논문의 main idea인 두 개의 classifier을 사용하기 위해서는, 일단 이들이 sample domain에 대해서는 잘 작동해야 한다.
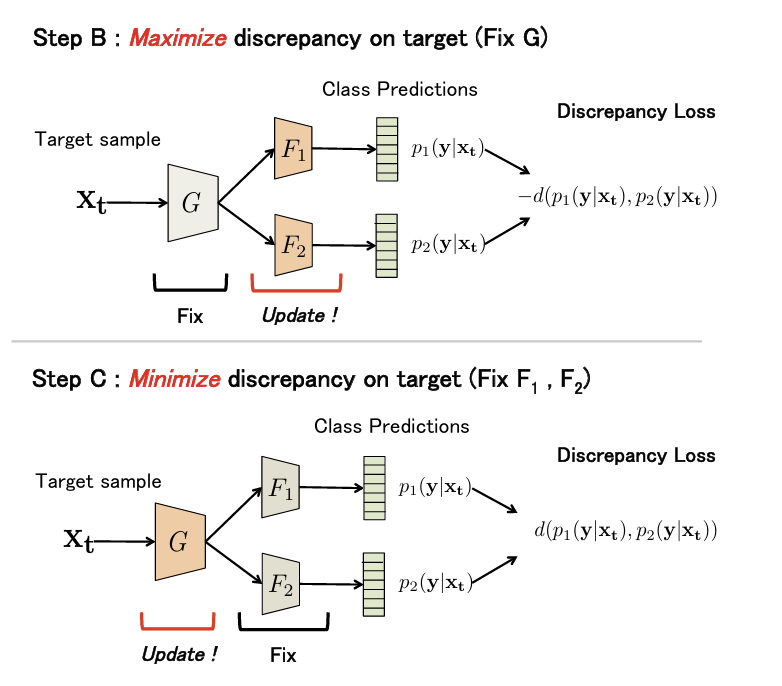
Step B
Feature Generater 를 고정시키고, 의 판별 discrepancy를 최대화 시킨다.
where
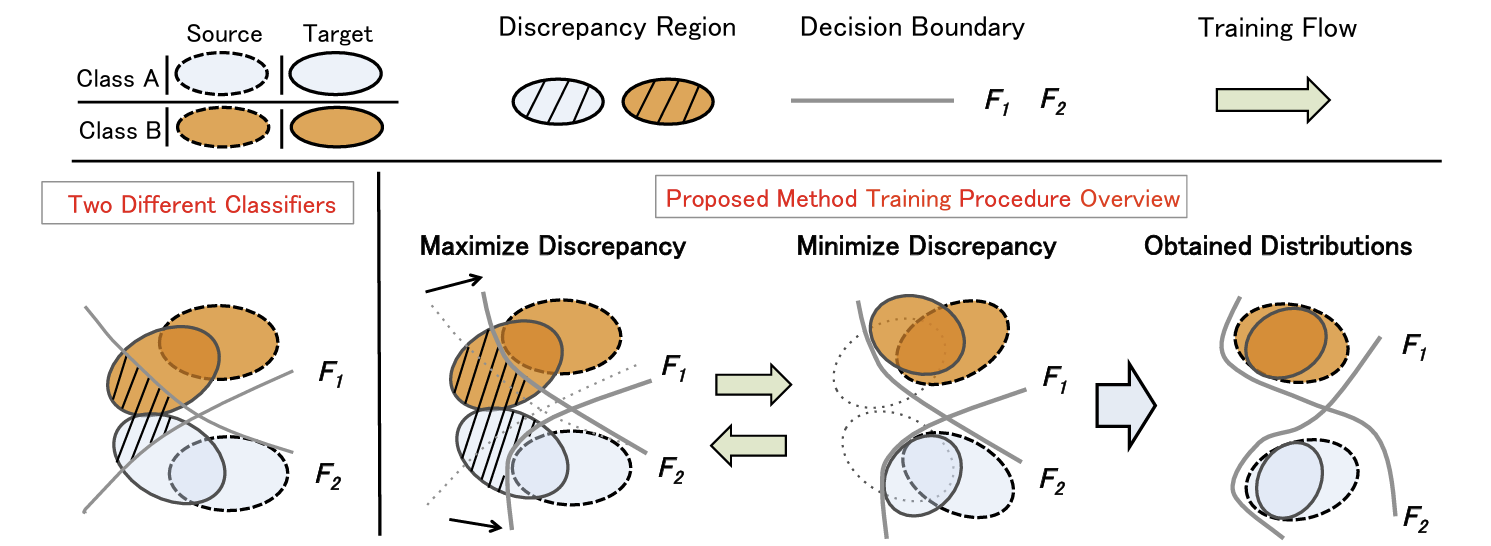
위의 그림을 참고하여 이게 무슨 말인지 설명해보면, 두 label을 잘 분류하는 두 label classifier에 대하여, 이들의 target에 대한 분류 discrepancy가 최대가 된다는 것은 의 decision boundary가 sample 데이터의 각 label(0,1)에 해당하는 경계에 가깝게 형성된다는 직관을 이용한 것이다.
Step C
를 고정시키고 를 위에서 구한 discrepancy가 최소화되도록 학습시킨다.
그렇다면, sample support에서 벗어나서 위치한 target data에 대하여 feature generator는 이들의 분포를 sample support로 이동시키려고 할 것이다.
이후 step B,C를 반복함으로써 model에 대한 update가 지속적으로 이루어진다
Target label에 맞춰 해당하는 classifier의 경계로 이동한다는 보장이 어디있는가?
가 고정되어 있을 때, sample support에서 떨어져있는 target sample 가 Generator의 update를 통하여 두 경계() 중 더 가까운 경계로 이동할까?
-> 그럴 것이다. 경계와의 거리와 는 밀접한 관련이 있는 개념이기 때문에, 최대한 빨리 discrepancy를 최소화 하기 위해서는 target data가 가장 가까운 경계로 이동해야 할 것이다.
Theoretical Insight
저자들은 다음과 같은 domain adaptation theorem에서 본 방법론의 아이디어를 떠올렸다고 한다.
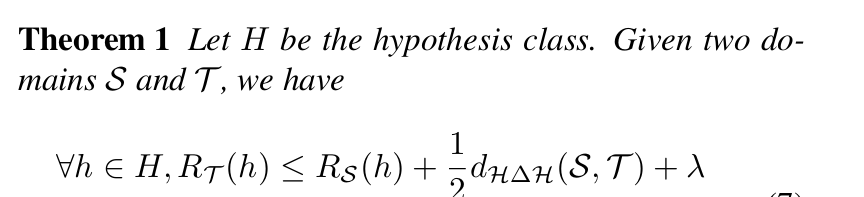
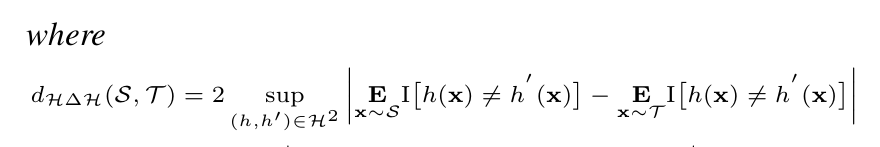

여기서 를 sample data를 잘 분류하는 classifier들의 집합으로 생각하자.
우리의 모델 하에서, , 의 합성함수 형태로 표현이 가능하다.
또한, sample data를 가 잘 분류한다는 가정 하에서,
의 첫번째 항은 0에 가깝게 된다.
즉, Theorem 1의 upper bound를 줄이기 위해서는
를 를 minimize 시켜는 target domain을 선택해야 하고, 이는 다음과 같이 표현 할 수 있다.
이 식이 우리가 이 논문에서 제시된 방법론과 일맥상통하는 부분이 있음을 알 수 있다.
